Kubernetes |Pod 深入理解与实践
这篇文章参考自《Kubernete权威指南》,对其中的相关章节做了一些总结,从下面十个点对pod进行深入讲解,也会有些配置的实例,希望对大家学习kubernetes带来些许帮助。
1pod定义详解
2pod到底是什么
3静态pod
4pod容器共享volume
5pod的配置管理
6pod的生命周期和重启策略
7pod健康检查
8玩转pod调度
9pod的扩容和缩容
10pod的滚动升级
1pod定义详解
下面是一个完整的yaml格式定义的文件,注意格式,子集包含关系,不要有tab,要用空格。不是所有的元素都要写,按照实际应用场景配置即可。
apiVersion: v1 //版本
kind: pod //类型,pod
metadata: //元数据
name: String //元数据,pod的名字
namespace: String //元数据,pod的命名空间
labels: //元数据,标签列表
- name: String //元数据,标签的名字
annotations: //元数据,自定义注解列表
- name: String //元数据,自定义注解名字
spec: //pod中容器的详细定义
containers: //pod中的容器列表,可以有多个容器
- name: String
image: String //容器中的镜像
imagesPullPolicy: [Always|Never|IfNotPresent]//获取镜像的策略
command: [String] //容器的启动命令列表(不配置的话使用镜像内部的命令)
args: [String] //启动参数列表
workingDir: String //容器的工作目录
volumeMounts: //挂载到到容器内部的存储卷设置
- name: String
mountPath: String
readOnly: boolean
ports: //容器需要暴露的端口号列表
- name: String
containerPort: int //容器要暴露的端口
hostPort: int //容器所在主机监听的端口(容器暴露端口映射到宿主机的端口)
protocol: String
env: //容器运行前要设置的环境列表
- name: String
value: String
resources: //资源限制
limits:
cpu: Srting
memory: String
requeste:
cpu: String
memory: String
livenessProbe: //pod内容器健康检查的设置
exec:
command: [String]
httpGet: //通过httpget检查健康
path: String
port: number
host: String
scheme: Srtring
httpHeaders:
- name: Stirng
value: String
tcpSocket: //通过tcpSocket检查健康
port: number
initialDelaySeconds: 0//首次检查时间
timeoutSeconds: 0 //检查超时时间
periodSeconds: 0 //检查间隔时间
successThreshold: 0
failureThreshold: 0
securityContext: //安全配置
privileged: falae
restartPolicy: [Always|Never|OnFailure]//重启策略
nodeSelector: object //节点选择
imagePullSecrets:
- name: String
hostNetwork: false //是否使用主机网络模式,默认否
volumes: //在该pod上定义共享存储卷
- name: String
meptyDir: {}
hostPath:
path: string
secret: //类型为secret的存储卷
secretName: String
item:
- key: String
path: String
configMap: //类型为configMap的存储卷
name: String
items:
- key: String
path: String
2pod到底是什么
kubernetes中的一切都可以理解为是一种资源对象,pod,rc,service,都可以理解是 一种资源对象。podd的组成示意图如下:
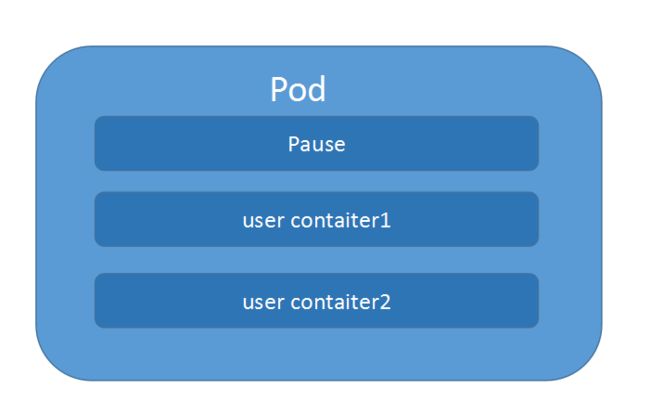
由一个叫”pause“的根容器,加上一个或多个用户自定义的容器构造。pause的状态带便了这一组容器的状态,pod里多个业务容器共享pod的Ip和数据卷。
我是这样理解的,在kubernetes环境下,pod是容器的载体,所有的容器都是在pod中被管理,一个或多个容器放在pod里作为一个单元方便管理。还有就是docker和kubernetes也不是一家公司的,如果做一个编排部署的工具,你也不可能直接去管理别人公司开发的东西吧,然后就把docker容器放在了pod里,在kubernetes的集群环境下,我直接管理我的pod,然后对于docker容器的操作,我把它封装在pod里,不直接操作。
3静态pod
静态Pod是由kubelet进行管理的仅存在于特定Node上的pod.它们不能通过API Server进行管理,无法与ReplicationController,Ddeployment或者DaemonSet进行关联,也无法进行健康检查。
所以我觉得这个静态pod没啥用武之地啊,就不详细的写下去了,偷个懒,嘻嘻。
4pod容器共享volume
在pod中定义容器的时候可以为单个容器配置volume,然后也可以为一个pod中的多个容器定义一个共享的pod 级别的volume。 那为啥要这样做呢,比如你在一个pod里定义了一个web容器,然后把生成的日志文件放在了一个文件夹,你还定义了一个分析日志的容器,那这个时候你就可以把这放日志的文件配置为共享的,这样一个容器生产,一个容器度就好了。
下面是一个使用共享volume的配置示例
apiVersion: v1
kind: Pod
metadata:
name: volume-pod
spec:
containers:
- name: tomcat
image: tomcat
ports:
- containerPort: 8080
volumeMounts:
- name: app-logs
mountPath: /usr/local/tomcat/logs
- name: loganalysis
image: loganalysis
volumeMounts:
- name: app-logs
mountPath: /usr/local/tomcat/logs
volumes:
- name: app-logs
emptyDir: {}
这个配置文件除了“emptyDir: {}”这个地方有点诡异以为,其他地方我估计大家一看就能明白,在最下面定义了一个叫“app-logs”的volume,然后上面的两个容器来使用它就好了。
然后现在来说说“emptyDir: {}”,其实这个地方有三种选择
volumes:
- name: app-logs
emptyDir: {}
volumes:
- name: app-logs
hostPth:
path: "/data"
volumes:
- name: app-logs
gcePersistenDisk:
pdName: my-data-disk //my-data-disk需要先创建好
fsType: ext4
emptyDir是Pod分配到Node后创建的,他的初始内容为空,pod在Node上移除以后也就被销毁了。
hostPath是挂载到宿主机上的目录,比较适用于需要永久保存的数据
gcePersistenDisk 表示使用谷歌公有云提供的磁盘
创建my-data-disk: gcloud compute disks create --size=500GB --zone=us-centrall-a my-data-disk
5pod的配置管理
应用部署的一个最佳实践,就是将应用所需的配置信息与程序进行分离
kubernetes 提供了一种的集群配置管理方案,即ConfigMap,就是将一些环境变量或者配置文件定义为configmap,放在kubernetes中,可以让其他pod 调用
configmap 有以下典型的用法
1 生成为容器内的环境变量
2 设置容器启动命令的启动参数(需设置为环境变量)
3 以volume的形式挂载为容器内部的文件或目录
局限:
1ConfigMap 必须在pod之前创建
2ConfigMap也可以定于属于某个NameSpace,只有处于相同NameSpace的pod可以应用它
3ConfigMap中的配额管理还未实现
4如果是volume的形式挂载到容器内部,只能挂载到某个目录下,该目录下原有的文件会被覆盖掉
5静态不能用configmap(静态pod 不受API server 管理)
下面是使用ConfigMap的示例
1定义一个ConfigMap 配置文件 cm-appvars.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-appvars
data:
apploglevel: info
appdatadir: /var/date
2创建ConfigMap: kubectl create -f cm-appvars.yaml
3使用ConfigMap(环境变量的形式)
apiVersion: v1
kind: Pod
metadata:
name: cm-test-pod
spec:
containers:
- name: cm-test
image: busybux
env:
- name: APPLOGLEVEL
vlaueFrom:
configMapKeyRef:
name: cm-appvars //要和之前创建的ConfigMap的name对应
key: apploglevel
- name: APPDATADIR
vlaueFrom:
configMapKeyRef:
name: cm-appvars //要和之前创建的ConfigMap的name对应
key: appdatadir
除了可以定义简单的k-v键值对,还可以将整个配置文件定义成ConfigMap
比如server.xml logging.properties(使用volumeMount的形式,挂载到容器内部)
1定义一个ConfigMap 配置文件 cm-jdbcproperties.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-jdbcproperties
data:
key-jdbcproperties: |
JDBC_DRIVER_CLASS_NAME=com.mysql.jdbc.Driver
JDBC_URL=jdbc:mysql://localhost:3306/bz_argon?useUnicode=true&characterEncoding=utf8
JDBC_USER_NAME=root
JDBC_PASSWORD=maojiancai
JDBC_INITIALSIZE=10
JDBC_MAXACTIVE=20
JDBC_MAXIDLE=20
JDBC_MINIDLE=10
JDBC_MAXWAIT=60000
JDBC_VALIDATIONQUERY=SELECT 1 FROM DUAL
JDBC_TESTONBORROW=false
JDBC_TESTONRETURN=false
JDBC_TESTWHILEIDLE=true
JDBC_TIMEBETWEENEVICTIONRUNSMILLIS=6000
JDBC_MINEVICTABLEIDLETIMEMILLIS=25200000
JDBC_REMOVEABANDONED=true
JDBC_REMOVEABANDONEDTIMEOUT=1800
JDBC_LOGABANDONED=true
2创建ConfigMap: kubectl create -f cm-jdbcproperties.yaml
3使用ConfigMap(使用volumeMount的形式)
apiVersion: v1
kind: Pod
metadata:
name: cm-test-app
spec:
containers:
- name: cm-test-app
image: cm-test-app
ports:
- containerPort: 8080
volumeMounts:
- name: jdbcproperties //应用下面定义的volumes名
mountPath: /configfiles
volumes:
- name: jdbcproperties //volumes名
configMap:
name: cm-jdbcproperties//这个名字是第二步创建的configMap
items:
- key: key-jdbcproperties
path: jdbc.properties
再提醒一下;
如果是volume的形式挂载到容器内部,只能挂载到某个目录下,该目录下原有的文件会被覆盖掉
6pod的生命周期和重启策略
pod一共有四种状态
| 状态值 | 描述 |
|---|---|
| Pending | APIserver已经创建该server,但pod内有一个或多个容器的镜像还未创建,可能在下载中。 |
| Running | Pod内所有的容器已创建,且至少有一个容器处于运行状态,正在启动或重启状态 |
| Failed | Pod内所有容器都已退出,其中至少有一个容器退出失败 |
| Unknown | 由于某种原因无法获取Pod的状态比如网络不通。 |
| 重启策略 | 描述 |
|---|---|
| Always | 容器失效时,即重启 |
| OnFailure | 容器终止运行,且退出码不为0 时重启 |
| Never | P不重启 |
Pod的重启策略应用于Pod内的所有容器,由Pod所在Node节点上的Kubelet进行判断和重启操作。重启策略有以下三种:
| 重启策略 | 描述 |
|---|---|
| Always | 容器失效时,即重启 |
| OnFailure | 容器终止运行,且退出码不为0 时重启 |
| Never | P不重启 |
7pod健康检查
Kubernetes内部通过2种探针,实现了对Pod健康的检查
LivenessProbe探针:判断容器是否存活(running)
ReadinessProbe探针: 用于判断容器是否启动完成(ready)
LivenessProbe探针通过三种方式来检查容器是否健康
(1)ExecAction:在容器内部执行一个命令,如果返回码为0,则表示健康
示例:
apiVersion: v1
kind: Pod
metadata:
name: liveness
spec:
containers:
- name: liveness
image: liveness
args:
- /bin/sh
- -c
- echo ok > /tmp/healthy: sleep 10; rm - rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/health
initialDelaySeconds: 15
timeoutSeconds: 1
(2)TcpAction:通过IP 和port ,如果能够和容器建立连接则表示容器健康
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-healthcheck
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 15
timeoutSeconds: 1
(3)HttpGetAction:发送一个http Get请求(ip+port+请求路径)如果返回状态吗在200-400之间则表示健康
示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-with-healthcheck
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /_status/healthz //请求路径
port: 80
initialDelaySeconds: 15
timeoutSeconds: 1
8玩转pod调度
在kubernetes系统中,pod在大部分场景下都只是容器的载体而已,通常需要通过Deployment,DaemonSet,Job等对象来完成Pod的调度与自动控制功能。
(1)RC,Deployment: 全自动调度
RC的主要功能之一就是自动部署一个容器应用的多份副本,以及持续监控,保持集群内有一定数量的副本数量(配置文件指定了副本数量)
NodeSelector: 定向调度
kubernetes中的Schduler 负责实现pode的调度,他会根据一些复杂的算法,把pod调度到某一个Node上,如果你想指定某个Pod需要指定在某个Node上则可以通过NodeSelector定向调度
示例:
1首先通过kubectl给node打上标签:
格式: kubectl label nodes
kubectl label nodes node1 zone=north
2在pod定义里选择某个node
apiVersion: v1
kind: Pod
metadata:
name: pod-with-healthcheck
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
nodeSelector:
zone: north
除了有定向的,还有亲和性的调度 NodeAffinity,符合某种条件的,比如,某个值大于1的(可以理解为模糊匹配),NodeAffinity有In NotIn Exists DoesNotExists Gt Lt 等操作规则来选择Node.
(2)DaemonSet: 特点场景调度
DaemonSet,用于管理在集群中每个Node上只运行一份Pod的副本实例,比如在每节点上都运行有且只有一个fluentd
示例:配置使得在每个节点上都有一个fluentd 容器
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: fluentd-cloud-logging
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
template:
metadata:
namespace: kube-system
labels:
k8s-app: fluentd-cloud-logging
spec:
containers:
- name: fluentd-cloud-logging
images: gcr.io/google_containers/fluentd-elasticsearch:1.17
resources:
limits:
cpu: 100m
memory: 200Mi
env:
- name: FLUENTD_ARGS
value: -q
volumeMounts:
- name: varlog
mountPath: /var/log
readOnly: false
- name: containers
mountPath: /var/lib/docker/containers
volumes:
- name: containers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log
(3)Job: 批处理调度
我们可以通过Kubernetes job资源对象来定义并启动一个批处理任务。批处理任务通常并行(或者串行)启动多个计算机进程去处理一批工作项。·
9pod的扩容和缩容
1通过scale来完成扩容或缩容
假设 redis-slave 这个pod原来定义了5个副本(reolics:5)
扩容到10个,执行命令: kubectl scale rc redis-slave --replicas=10
缩容到2个,执行命令:kubectl scale rc redis-slave --replicas=2
2动态扩容缩容(HPA)
通过对cpu使用率的监控,HPA(Horizontal Pod Autoscaler),来动态的扩容或缩容。pod cpu使用率是考heapster组件来获取的,所以要预先安装好。
创建HPA:
在创建HPA前需要已经存在一个RC或Deployment对象,并且该RC或Deployment中的Pod必须定义 resource.request.cpu的请求值,否则无法获取cpu使用情导致HPA 无法工作
假设现在有一个php-apache RC
1通过kubectl autoscale 命令创建
kubectl autoscale rc php-apache --min=1 --max=10 --cpu-percent=50
含义:在1-10之间调整副本数量,使CPU使用率维持在50%左右
2通过配置文件的方式创建HPA
apiVersion: autoscaling/v1
kind: HorizaontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: v1
kind: ReplicationController
name: php-apache
minReplicas: 1
maxrReplicas: 10
targetCPUUtilizationPercentage: 50
10pod的滚动升级
滚动升级通过kubectl rolling-update 命令一键完成。
示例:假设现在运行的redis-master的pod是1.0版本,现在需要升级到2.0版本。
创建redis-master-controller-v2.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: redis-master-v2
labels:
name: redis-master
version: v2
spec:
replicas: 1
selector:
name: redis-master
version: v2
template:
metadata:
labels:
name: redis-master
version: v2
spec:
containers:
- name: master
images: kubeguide/redis-master:2.0
ports:
- containerPort: 6379
更新:kubectl rolling-update redis-master -f redis-master-controller-v2.yaml
需要注意到是:
rc的名字(name)不能与旧的rc的名字相同
在selector中至少有一个Label与旧的Label不同。以标识其为新的RC