前言:
以斯坦福cs231n课程的python编程任务为主线,展开对该课程主要内容的理解和部分数学推导。建议PC端阅读,该课程的学习资料和代码如下:
视频和PPT
笔记
assignment3初始代码
Part 1: 空间定位和检测(Spatial Localization and Detection)
以ILSVRC竞赛为例,该竞赛包含了三个计算机视觉任务:分类、定位和检测。
分类:图像上是啥? 预测top-5分类
定位:目标在哪里、是啥? 预测top-5分类+每个类别的bounding box(覆盖率50%以上)
检测:在哪里、都有啥?
---->> 定位是介于分类和检测的中间任务,分类和定位使用相同的数据集,检测的数据集有额外的数据集(物体比较小)。
这里贴张图,方便直观理解下各个任务的区别:
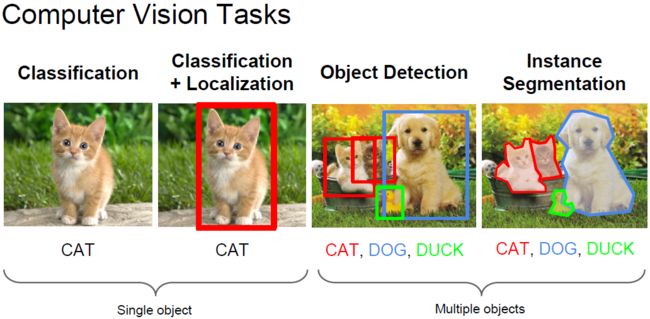
其中,分类+定位我们可以一起完成。方便感受,上张图:

那么改如何一起完成呢?我们可以将定位看成回归问题,具体请看下图:
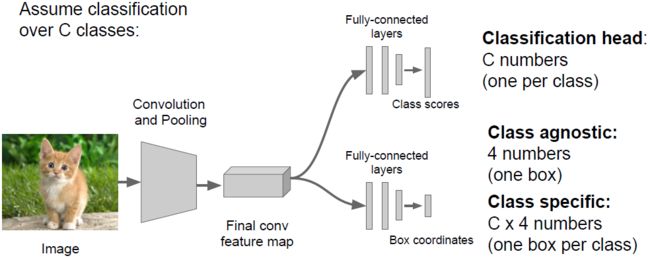
对于目标检测问题,我们是否也可以看成回归问题来解决呢?由于每个图像中目标个数不一样,要定位的坐标数量也不一样,所以这并不是一个很好的思路;另一个思路是将其看成分类问题,不过我们需要在不同位置进行很多次分类,这会很耗时。
对于目标检测,R-CNN无疑是深度学习下目标检测的经典作品,其思想引领了最近两年目标检测的潮流。这里简单介绍下R-CNN的算法思路:
输入一张图片,我们先定位出2K个物体候选框,然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维,接着采用SVM算法对各个候选框中的物体进行分类识别。

这里列一下近两年来目标检测的风向标:
R-CNN ---> SPPNET ---> Fast-RCNN ---> Faster-RCNN
Part 2: 循环神经网络(Recurrent Neural Networks)
RNNs主要用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子中的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。下图是一个典型的RNNs(右侧是左侧的简化结构):
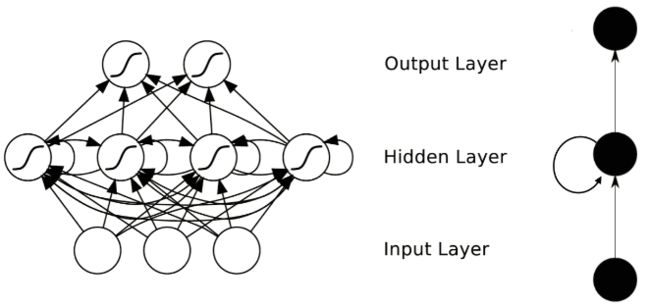
为了更好地说明RNN,我们可以将网络按照时间进行展开:

在RNN中每一个时间步骤用到的参数(U, W, V)都是一样的。一般来说,每一时间的输入和输出是不一样的,比如对于序列数据就是将序列项依次传入,每个序列项再对应不同的输出(比如下一个序列项)。
1. 反向传播算法(Back Propagation Through Time, BPTT)
RNNs的前向传播依次按照时间的顺序计算,反向传播就是从最后一个时间点将累积的残差传递回来即可。下面给出前向传播和后向传播的计算公式:

2. 图像描述(Image Captioning)
顾名思义,对于给定的一张图片,自动生成一段文字描述。就像这样:

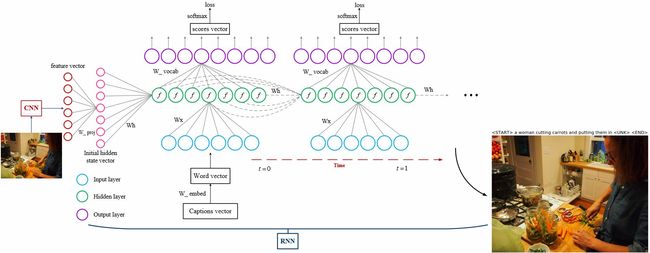
在Assignment3中,我们将用CNN+RNN来实现图像自动描述,将会用到Microsoft COCO数据库。那么如何搭建结构框架呢?这里先给张图直观感受下:

上图中,我们用CNN来对输入图像进行特征提取,然后将提取到的特征作为RNN隐藏层的初始态(相当于t = -1时,隐藏层的输出值)输入到第一个时间点(t = 0)的隐藏层。RNN每个时间点的输出是当前输入序列项的下一项(比如,输入"straw",输出"hat")。
下面我给出一张详细的diagram,方便大家完成Assignment3第一部分的编程任务,即RNN_Captioning.ipynb里的任务:
3. Python编程任务(RNN)
这部分我们需要完成以下编程任务(此外,需要理解下captioning_solver.py):
--> rnn_layers.py,除了LSTM部分
--> rnn.py
具体代码如下:
--> rnn_layers.py
__coauthor__ = 'Deeplayer'
# 8.13.2016 #
import numpy as np
def rnn_step_forward(x, prev_h, Wx, Wh, b):
next_h = np.tanh(x.dot(Wx) + prev_h.dot(Wh) + b)
cache = (x, Wx, Wh, prev_h, next_h)
return next_h, cache
def rnn_step_backward(dnext_h, cache):
x, Wx, Wh, prev_h, next_h = cache
dtanh = 1 - next_h ** 2 # (N, H)
dx = (dnext_h * dtanh).dot(Wx.T) # (N, D)
dprev_h = (dnext_h * dtanh).dot(Wh.T) # (N, H)
dWx = x.T.dot(dnext_h * dtanh) # (D, H)
dWh = prev_h.T.dot(dnext_h * dtanh) # (H, H)
db = np.sum((dnext_h * dtanh), axis=0)
return dx, dprev_h, dWx, dWh, db
def rnn_forward(x, h0, Wx, Wh, b):
N, T, D = x.shape
_, H = h0.shape
h = np.zeros((N, T, H))
h_interm = h0
cache = []
for i in xrange(T):
h[:, i, :], cache_sub = rnn_step_forward(x[:, i, :], h_interm, Wx, Wh, b)
h_interm = h[:, i, :]
cache.append(cache_sub)
return h, cache
def rnn_backward(dh, cache):
x, Wx, Wh, prev_h, next_h = cache[-1]
_, D = x.shape
N, T, H = dh.shape
dx = np.zeros((N, T, D))
dh0 = np.zeros((N, H))
dWx = np.zeros((D, H))
dWh = np.zeros((H, H))
db = np.zeros(H)
dprev_h_=np.zeros((N, H))
for i in xrange(T-1, -1, -1):
dx_, dprev_h_, dWx_, dWh_, db_ = rnn_step_backward(dh[:, i, :] + dprev_h_, cache.pop())
dx[:, i, :] = dx_
dh0 = dprev_h_
dWx += dWx_
dWh += dWh_
db += db_
return dx, dh0, dWx, dWh, db
def word_embedding_forward(x, W):
N, T = x.shape
V, D = W.shape
out = np.zeros((N, T, D))
for n in xrange(N):
for t in xrange(T):
out[n, t, :] = W[x[n, t]]
cache = (x, W)
return out, cache
def word_embedding_backward(dout, cache):
x, W = cache
N, T, D = dout.shape
dW = np.zeros(W.shape)
for n in xrange(N):
for t in xrange(T):
dW[x[n, t]] += dout[n, t, :]
return dW
--> rnn.py
__coauthor__ = 'Deeplayer'
# 8.13.2016 #
def loss(self, features, captions):
captions_in = captions[:, :-1]
captions_out = captions[:, 1:]
mask = (captions_out != self._null)
W_proj, b_proj = self.params['W_proj'], self.params['b_proj']
W_embed = self.params['W_embed']
Wx, Wh, b = self.params['Wx'], self.params['Wh'], self.params['b']
W_vocab, b_vocab = self.params['W_vocab'], self.params['b_vocab']
loss, grads = 0.0, {}
# forward pass
imf2hid = features.dot(W_proj) + b_proj # initial hidden state: [N, H]
word_vectors, word_cache = word_embedding_forward(captions_in, W_embed) # [N, T, W]
if self.cell_type == 'rnn':
hidden, rnn_cache = rnn_forward(word_vectors, imf2hid, Wx, Wh, b) # [N, T, H]
else:
hidden, lstm_cache = lstm_forward(word_vectors, imf2hid, Wx, Wh, b)
scores, h2v_cache = temporal_affine_forward(hidden, W_vocab, b_vocab) # [N, T, V]
loss, dscores = temporal_softmax_loss(scores, captions_out, mask)
# backward pass
dhidden, grads['W_vocab'], grads['b_vocab'] = temporal_affine_backward(dscores, h2v_cache)
if self.cell_type == 'rnn':
dword_vectors, dimf2hid, grads['Wx'], grads['Wh'], grads['b'] = rnn_backward(dhidden, rnn_cache)
else:
dword_vectors, dimf2hid, grads['Wx'], grads['Wh'], grads['b'] = lstm_backward(dhidden, lstm_cache)
grads['W_embed'] = word_embedding_backward(dword_vectors, word_cache)
grads['W_proj'] = features.T.dot(dimf2hid)
grads['b_proj'] = np.sum(dimf2hid, axis=0)
return loss, grads
def sample(self, features, max_length=30):
N = features.shape[0]
captions = self._null * np.ones((N, max_length), dtype=np.int32) # [N, max_length]
# Unpack parameters
W_proj, b_proj = self.params['W_proj'], self.params['b_proj']
W_embed = self.params['W_embed'] # [V, W]
V, W = W_embed.shape
Wx, Wh, b = self.params['Wx'], self.params['Wh'], self.params['b']
W_vocab, b_vocab = self.params['W_vocab'], self.params['b_vocab'] # [H, V]
h = features.dot(W_proj) + b_proj # [N, H]
c = np.zeros(h.shape)
init_word = np.repeat(self._start, N)
captions[:, 0] = init_word
for i in xrange(1, max_length):
onehots = np.eye(V)[captions[:, i-1]] # [N, V]
word_vectors = onehots.dot(W_embed) # [N, W]
if self.cell_type == 'rnn':
h, cache = rnn_step_forward(word_vectors, h, Wx, Wh, b)
else:
h, c, cache = lstm_step_forward(word_vectors, h, c, Wx, Wh, b)
scores = h.dot(W_vocab) + b_vocab # [N, V]
captions[:, i] = np.argmax(scores, axis=1)
return captions
Part 3: Long Short-Term Memory Networks (LSTM Networks)
对于上面提到的RNN,存在一个问题,就是无法解决长期依赖问题(long-term dependencies)。当时间序列变得很长的时候,前后信息的关联度会越来越小,直至消失,即所谓的梯度消失现象。而LSTM这种特殊的RNN结构,可以解决长期依赖问题。LSTM由Hochreiter & Schmidhuber于1997年提出,之后有很多改进版本。
下面介绍下一般的LSTM,也将是我们在assignment中用到的结构,内容借鉴自Colah 的博文。
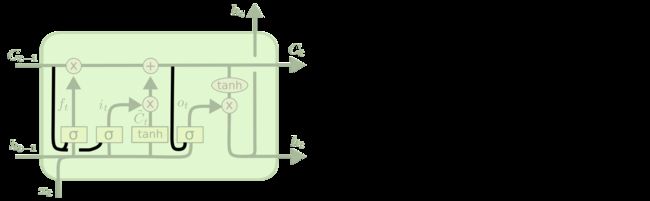
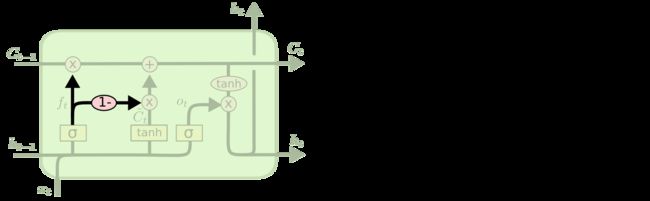
和RNN一样,LSTM也是随着时间序列重复着一样的模块,只是LSTM的每个某块比RNN更加复杂,拥有四个层(3个门+1个记忆单元)。下图方框内上方的那条水平线,被称为胞元状态(cell state),LSTM通过门结构对记忆单元上的信息进行线性修改,保证了当时间序列变得很长的时候,前后信息的关联度不会衰减。

下面介绍下3个门:
遗忘门(Forget gate): 通过sigmoid来控制,它会根据上一时刻的输出ht-1和当前输入xt来产生一个0到1的值ft,来决定让上一时刻学到的信息Ct-1通过的程度(即对上一时刻的信息Ct-1进行遗忘)。

输入门(Input gate): 通过sigmoid来决定哪些值用来更新进cell state,这里的值是由一个tanh层生成的,称为候选值Ct(上方少个 ~)。
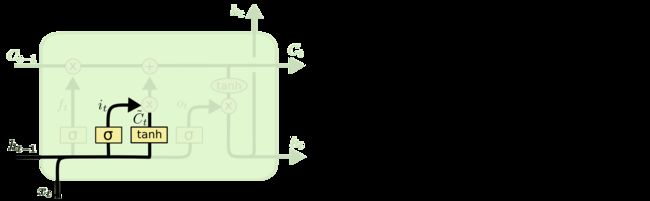
现在,我们对cell state进行更新(丢弃不需要的信息,添加新信息),如下所示:
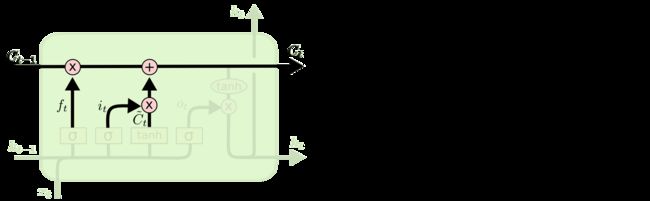
输出门(Output gate): 通过sigmoid层来决定cell state的哪个部分将被输出。接着,我们把当前的cell state通过tanh层进行处理,并将它和sigmoid层的输出相乘,最终输出我们确定要输出的那部分信息 ht 。
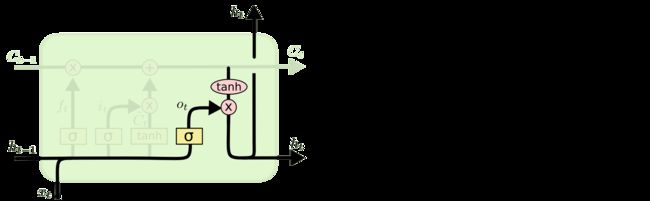
目前为止,我们所讲的是标准的LSTM。LSTM 还有许多变体,这里我们介绍几种变体。
由Gers & Schmidhuber于2000年提出的,增加了 “peephole connection” 的LSTM。主要变化是:3个门层接受了cell state的输入。
另一个变体是通过使用 coupled 遗忘门和输入门,遗忘和输入是同时进行的。从下图的公式可以看出,新的信息仅仅是输入到那些已经被遗忘的部分。
另一个变体是 Gated Recurrent Unit (GRU),由 Cho, et al. 于2014年提出。它将忘记门和输入门合成了一个单一的更新门。同样还混合了胞元状态和隐藏状态,和其他一些改动。最终的模型比标准的 LSTM 模型要简单。

在给出LSTM代码前,我先给出一下使用标准LSTM进行Image captioning的模型结构图:

代码如下:
def lstm_step_forward(x, prev_h, prev_c, Wx, Wh, b):
_, H = prev_h.shape
a = x.dot(Wx) + prev_h.dot(Wh) + b # (N, 4H)
ai, af, ao, ag = a[:, 0:H], a[:, H:2*H], a[:, 2*H:3*H], a[:, 3*H:]
i, f, o, g = sigmoid(ai), sigmoid(af), sigmoid(ao), np.tanh(ag)
next_c = f * prev_c + i * g
next_h = o * np.tanh(next_c)
cache = (x, prev_h, prev_c, Wx, Wh, a, i, f, o, g, next_c, next_h)
return next_h, next_c, cache
def lstm_step_backward(dnext_h, dnext_c, cache):
_, H = dnext_h.shape
x, prev_h, prev_c, Wx, Wh, a, i, f, o, g, next_c, next_h = cache
ai, af, ao, ag = a[:, 0:H], a[:, H:2*H], a[:, 2*H:3*H], a[:, 3*H:]
dnext_c += dnext_h * o * (1 - (np.tanh(next_c))**2)
do = dnext_h * np.tanh(next_c)
df = dnext_c * prev_c
dprev_c = dnext_c * f
di = dnext_c * g
dg = dnext_c * i
dai = di * (sigmoid(ai) * (1-sigmoid(ai)))
daf = df * (sigmoid(af) * (1-sigmoid(af)))
dao = do * (sigmoid(ao) * (1-sigmoid(ao)))
dag = dg * (1 - np.tanh(ag)**2)
da = np.hstack((dai, daf, dao, dag)) # (N, 4H)
dx = da.dot(Wx.T) # (N, D)
dWx = x.T.dot(da)
dprev_h = da.dot(Wh.T)
dWh = prev_h.T.dot(da)
db = np.sum(da, axis=0)
return dx, dprev_h, dprev_c, dWx, dWh, db
def lstm_forward(x, h0, Wx, Wh, b):
N, T, D = x.shape
_, H = h0.shape
cache = []
hidden = h0
h = np.zeros((N, T, H))
cell = np.zeros((N, H))
for i in xrange(T):
hidden, cell, sub_cache = lstm_step_forward(x[:, i, :], hidden, cell, Wx, Wh, b)
cache.append(sub_cache)
h[:, i, :] = hidden
return h, cache
def lstm_backward(dh, cache):
x, prev_h, prev_c, Wx, Wh, a, i, f, o, g, next_c, next_h = cache[0]
N, T, H = dh.shape
N, D = x.shape
dh0 = np.zeros((N, H))
db = np.zeros(4*H)
dWx = np.zeros((D, 4*H))
dWh = np.zeros((H, 4*H))
dx = np.zeros((N, T, D))
dprev_c_ = np.zeros((N, H))
dprev_h = np.zeros((N, H))
for i in xrange(T-1, -1, -1):
dx_, dprev_h, dprev_c_, dWx_, dWh_, db_ = lstm_step_backward(dh[:, i, :]+dprev_h, dprev_c_, cache.pop())
dWx += dWx_
dWh += dWh_
db += db_
dx[:, i, :] += dx_
dh0 = dprev_h
return dx, dh0, dWx, dWh, db
这里给出一些在验证集上的结果:

Part 4:图像梯度(Image Gradients)
这部分我们将用预训练好的CNN模型来计算图像的梯度,并用图像梯度来产生class saliency maps 和 fooling images。这部分我们会用到TinyImageNet数据集,它是ILSVRC-2012分类数据集的一个子集,包含了200个类,每一个类拥有500张训练图片,50张验证图片和50张测试图片,每张图片大小为64x64。TinyImageNet数据集被分成了两部分:TinyImageNet-100-A和TinyImageNet-100-B,每部分包含100个类,这里我们使用的是TinyImageNet-100-A。

1. Saliency Maps
给定一张图片X,我们想要知道到底是图片中的哪些部分决定了该图片的最终分类结果。给定一个类,我们可以通过反向传播求出X关于loss function的偏导矩阵,这个偏导矩阵就是该图片的图像梯度,然后计算出类显著度图(class saliency map, csm)。Karen Simonyan论文的3.1节给出了计算方法:如果图片是灰度图,那么csm就取图像梯度的绝对值;如果是RGB图,csm就取图像梯度3个通道中绝对值最大的那个通道。csm中元素值的大小表示对应位置的图片像素对最终分类结果的影响程度。
代码如下:
def compute_saliency_maps(X, y, model):
N,C,H,W = X.shape
saliency = np.zeros((N,H,W))
# Compute the score by a single forward pass
scores, cache = model.forward(X, mode='test') # Score size (N,100)
# The loss function we want to optimize(maximize)
# loss = (scores[np.arange(N), y] - lambda*np.sqrt(np.sum(X**2))) # Size (N,)
# The gradient of this loss wih respect to the input image
dscores = np.zeros_like(scores)
dscores[np.arange(N), y] = 1.0
dX, grads = model.backward(dscores, cache)
saliency += np.max(np.abs(dX), axis=1)
return saliency
下图是一些saliency maps的可视化结果:


2. Fooling Images
我们可以用图像梯度来生成 虚假图像(fooling images)。给定一张图片和一个目标类,我们可以对该图片执行梯度上升(将图像梯度不断地叠加到原图片上),以产生一个fooling image。该fooling image和原图片在视觉上非常接近,但是CNN会把它识别成我们预先设定的目标类。
代码如下:
def make_fooling_image(X, target_y, model):
X_fooling = X.copy()
N,C,H,W = X_fooling.shape # N=1
i = 0
y_pred = -1
lr = 200.0
while (y_pred != target_y) & (i<200):
scores, cache = model.forward(X_fooling, mode='test') # Score size (N,100)
# The loss function we want to optimize(maximize)
# loss = scores[np.arange(N), target_y] # Size (N,)
# print loss
# The gradient of this loss wih respect to the input image
dscores = np.zeros_like(scores)
dscores[np.arange(N), target_y] = 1.0
dX, grads = model.backward(dscores, cache)
X_fooling += lr*dX
y_pred = model.loss(X_fooling).argmax(axis=1)
i+=1
print 'Iteration %d: current class: %d; target class: %d ' % (i, y_pred, target_y)
return X_fooling

从上图结果我们可以看出:CNN依旧无法摆脱维度的诅咒这一难题,因为存在对抗样本使它无法正确辨识。
Part 5:图像生成(Image Generation)
这一部分我们继续探索图像梯度,我们将使用不同的方法通过图像梯度生成图像。
1. Class visualization
给定一个目标类(比如蜘蛛),我们可以在一个随机噪声图像上,利用梯度上升来生成一个(蜘蛛)图像,并且CNN会把它识别成目标类。具体实现方法可以参见论文:Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps。
代码如下:
def create_class_visualization(target_y, model, **kwargs):
learning_rate = kwargs.pop('learning_rate', 10000)
blur_every = kwargs.pop('blur_every', 1)
l2_reg = kwargs.pop('l2_reg', 1e-6)
max_jitter = kwargs.pop('max_jitter', 4)
num_iterations = kwargs.pop('num_iterations', 200)
show_every = kwargs.pop('show_every', 25)
X = np.random.randn(1, 3, 64, 64)
for t in xrange(num_iterations):
# As a regularizer, add random jitter to the image
ox, oy = np.random.randint(-max_jitter, max_jitter+1, 2)
X = np.roll(np.roll(X, ox, -1), oy, -2)
# Compute the score and gradient
scores, cache = model.forward(X, mode='test')
# loss = scores[0, target_y] - l2_reg*np.sum(X**2)
dscores = np.zeros_like(scores)
dscores[0, target_y] = 1.0
dX, grads = model.backward(dscores, cache)
dX -= 2*l2_reg*X
X += learning_rate*dX
# Undo the jitter
X = np.roll(np.roll(X, -ox, -1), -oy, -2)
# As a regularizer, clip the image
X = np.clip(X, -data['mean_image'], 255.0 - data['mean_image'])
# As a regularizer, periodically blur the image
if t % blur_every == 0:
X = blur_image(X)
# Periodically show the image
if t % show_every == 0:
print 'The loss is %f' % loss
plt.imshow(deprocess_image(X, data['mean_image']))
plt.gcf().set_size_inches(3, 3)
plt.axis('off')
plt.title('Iteration: %d' % t)
plt.show()
return X
下图是迭代过程中生成的(蜘蛛)图像:

2. Feature Inversion
这部分我们将完成一个很有意思的工作:在一张随机噪声图像上重建出指定层CNN学习到的图像特征表达。详细的实现方法参见论文: Understanding Deep Image Representations by Inverting them 和 Understanding Neural Networks Through Deep Visualization。
代码如下:
def invert_features(target_feats, layer, model, **kwargs):
learning_rate = kwargs.pop('learning_rate', 10000)
num_iterations = kwargs.pop('num_iterations', 500)
l2_reg = kwargs.pop('l2_reg', 1e-7)
blur_every = kwargs.pop('blur_every', 1)
show_every = kwargs.pop('show_every', 50)
X = np.random.randn(1, 3, 64, 64)
for t in xrange(num_iterations):
# Forward until target layer
feats, cache = model.forward(X, end=layer, mode='test')
# Compute the loss
loss = np.sum((feats-target_feats)**2) + l2_reg*np.sum(X**2)
# Compute the gradient of the loss with respect to the activation
dfeats = 2*(feats-target_feats)
dX, grads = model.backward(dfeats, cache)
dX += 2*l2_reg*X
X -= learning_rate*dX
# As a regularizer, clip the image
X = np.clip(X, -data['mean_image'], 255.0 - data['mean_image'])
# As a regularizer, periodically blur the image
if (blur_every > 0) and t % blur_every == 0:
X = blur_image(X)
if (show_every > 0) and (t % show_every == 0 or t + 1 == num_iterations):
print loss
plt.imshow(deprocess_image(X, data['mean_image']))
plt.gcf().set_size_inches(3, 3)
plt.axis('off')
plt.title('Iteration: %d' % t)
plt.show()
下图是迭代过程中生成的图像特征(浅层和深层):


3. DeepDream
这部分我们体验一下简化版的DeepDream。实现思想很简单,我们先选定CNN的某一层(我们将在该层dream),然后将需要dream的图像输入进预训练好的CNN。前向传播至目标层,令该层的梯度等于该层的激活值(特征)。然后反向传播至输入层,求出图像梯度,同过梯度下降法将图像梯度不断叠加到输入图像上。
代码如下:
def deepdream(X, layer, model, **kwargs):
X = X.copy()
learning_rate = kwargs.pop('learning_rate', 5.0)
max_jitter = kwargs.pop('max_jitter', 16)
num_iterations = kwargs.pop('num_iterations', 200)
show_every = kwargs.pop('show_every', 50)
for t in tqdm(xrange(num_iterations)):
# As a regularizer, add random jitter to the image
ox, oy = np.random.randint(-max_jitter, max_jitter+1, 2)
X = np.roll(np.roll(X, ox, -1), oy, -2)
# Forward until dreaming layer
fea, cache = model.forward(X, end=layer ,mode='test')
# Set the gradient equal to the feature
dfea = fea
dX, grads = model.backward(dfea, cache)
X += learning_rate*dX
# Undo the jitter
X = np.roll(np.roll(X, -ox, -1), -oy, -2)
# As a regularizer, clip the image
mean_pixel = data['mean_image'].mean(axis=(1, 2), keepdims=True)
X = np.clip(X, -mean_pixel, 255.0 - mean_pixel)
# Periodically show the image
if t == 0 or (t + 1) % show_every == 0:
img = deprocess_image(X, data['mean_image'], mean='pixel')
plt.imshow(img)
plt.title('Iteration: %d' % (t + 1))
plt.gcf().set_size_inches(8, 8)
plt.axis('off')
plt.show()
return X
接下来我们就可以生成DeepDream图像啦!



---> CS231n : Assignment 1
---> CS231n : Assignment 2