基于 Pytorch 和 VGG19 模型实现图片风格迁移。
相关 Pytorch 官方教程
相关 Github 源码
版权声明:本文为 frendy 原创文章,可以随意转载,但请务必在明确位置注明出处。

实践出真知,其实该 Demo 基本是参考 Pytorch 官方教程实现,frendy 在这里只是按照自己的学习路径实践记录了一遍,并提取部分重点跟大家做分享,还是墙裂建议大家去看看官方教程的,文章前面已附上链接地址。好吧,稍微啰嗦一下,笔者的传统学习路径是:浏览概念不求甚解;跑 Demo;回头啃概念或论文(捂脸,目前啃得都不好哎)。
文中涉及到的相关概念如有偏颇或错误,请各位大神不吝赐教,批评指出,这里先谢过。
为什么选 Pytorch
Pytorch 来自 Facebook,我们先来看看它的宣传语吧:
Matlab is so 2012.
Caffe is so 2013.
Theano is so 2014.
Torch is so 2015.
TensorFlow is so 2016.
It's 2017 now.
实际上呢?frendy 还不敢妄言,学习和实践也不是很透彻。不过感觉 Pytorch 比 TensorFlow 要容易上手一点,而且是动态图,比起 TensorFlow 的静态图要灵活一点。道听途说,TensorFlow 依然拥有最大的社区,而 Pytorch 则最近增长比较快。
环境配置
可以到下面的官网获取相应配置的安装命令(官方目前只支持 Linux 和 OSX):
http://pytorch.org/
frendy 这里是 Win10,侥幸找到一个别人编译好的版本,更侥幸的是他的电脑配置跟我的基本一样,可以直接使用(百度云下载地址):
conda install pytorch-0.1.12-py36_0.1.12cu80.tar.bz2
pip install torchvision
其中 conda 的版本为 Anaconda3 (with Python 3.6)。
原理分析
提取图片 A 的内容,提取图片 B 的风格,合成一张新图:
Image_A (content) + Image_B (style) = Image_C (result)
- 使得 A 和 C 的内容差异尽可能小;
- 使得 B 和 C 的风格差异尽可能小。
好了,目标明确,但是该怎么定义或者说是衡量内容差异和风格差异呢?frendy 觉得这就是风格迁移的核心问题所在了。
内容差异
其实比较容易可以想到的就是比较两张图片每个像素点。怎么比较呢?也就是求一下差。在 torch 里,我们可以直接调用 nn.MSELoss 来计算输入和目标之间的均方误差。
class ContentLoss(nn.Module):
def __init__(self, target, weight):
super(ContentLoss, self).__init__()
# we 'detach' the target content from the tree used
self.target = target.detach() * weight
# to dynamically compute the gradient: this is a stated value,
# not a variable. Otherwise the forward method of the criterion
# will throw an error.
self.weight = weight
self.criterion = nn.MSELoss()
def forward(self, inputs):
self.loss = self.criterion(inputs*self.weight, self.target)
self.outputs = inputs
return self.outputs
def backward(self, retain_variables=True):
self.loss.backward(retain_variables=retain_variables)
return self.loss
其中 forward 是根据图往前计算,backward 是反向传播优化权重。Pytorch 封装了细节,支持自动求导。
风格差异
风格是一个挺抽象的概念。什么是风格?有个性。恩,自己的特点越突出,别人的越不突出最好。巨人们的论文告诉我们可以用 Gram 矩阵来衡量风格。
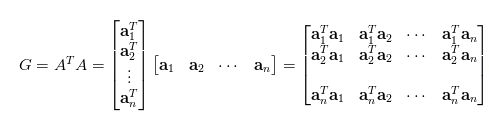
从上图可以看出,内积之后,对角线元素(即不同特征图各自的信息)就放大了,同时其余元素则提供了不同特征图之间的相关信息。于是,在一个Gram矩阵中,既能体现出有哪些特征,又能体现出不同特征间的紧密程度。那么,接下来我们就可以定量分析风格啦:
class GramMatrix(nn.Module):
def forward(self, input):
a, b, c, d = input.size()
# a=batch size(=1)
# b=number of feature maps
# (c,d)=dimensions of a f. map (N=c*d)
features = input.view(a * b, c * d) # resise F_XL into \hat F_XL
G = torch.mm(features, features.t()) # compute the gram product
# we 'normalize' the values of the gram matrix
# by dividing by the number of element in each feature maps.
return G.div(a * b * c * d)
class StyleLoss(nn.Module):
def __init__(self, target, weight):
super(StyleLoss, self).__init__()
self.target = target.detach() * weight
self.weight = weight
self.gram = GramMatrix()
self.criterion = nn.MSELoss()
def forward(self, inputs):
self.output = inputs.clone()
self.G = self.gram(inputs)
self.G.mul_(self.weight)
self.loss = self.criterion(self.G, self.target)
return self.output
def backward(self, retain_variables=True):
self.loss.backward(retain_variables=retain_variables)
return self.loss
模型搭建
这里使用 19 层的 vgg 作为提取特征的卷积网络,并定义了哪几层为需要的特征。
def get_model_and_losses(style_img, content_img,
style_weight=1000, content_weight=1):
content_layers = ['conv_4']
style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
use_cuda = torch.cuda.is_available()
cnn = models.vgg19(pretrained=True).features
if use_cuda:
cnn = cnn.cuda()
cnn = copy.deepcopy(cnn)
content_losses = []
style_losses = []
model = nn.Sequential()
gram = GramMatrix()
if use_cuda:
model = model.cuda()
gram = gram.cuda()
i = 1
for layer in list(cnn):
if isinstance(layer, nn.Conv2d):
name = "conv_" + str(i)
model.add_module(name, layer)
if name in content_layers:
# add content loss:
target = model(content_img).clone()
content_loss = ContentLoss(target, content_weight)
model.add_module("content_loss_" + str(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:
# add style loss:
target_feature = model(style_img).clone()
target_feature_gram = gram(target_feature)
style_loss = StyleLoss(target_feature_gram, style_weight)
model.add_module("style_loss_" + str(i), style_loss)
style_losses.append(style_loss)
if isinstance(layer, nn.ReLU):
name = "relu_" + str(i)
model.add_module(name, layer)
if name in content_layers:
# add content loss:
target = model(content_img).clone()
content_loss = ContentLoss(target, content_weight)
model.add_module("content_loss_" + str(i), content_loss)
content_losses.append(content_loss)
if name in style_layers:
# add style loss:
target_feature = model(style_img).clone()
target_feature_gram = gram(target_feature)
style_loss = StyleLoss(target_feature_gram, style_weight)
model.add_module("style_loss_" + str(i), style_loss)
style_losses.append(style_loss)
i += 1
if isinstance(layer, nn.MaxPool2d):
name = "pool_" + str(i)
model.add_module(name, layer)
return model, style_losses, content_losses
模型训练
这里使用 L-BFGS(Limited-memory Broyden–Fletcher–Goldfarb–Shanno) 算法来跑梯度下降,并通过 backward 反向优化权重,不断缩小 A 和 C 的内容差异、缩小 B 和 C 的风格差异。
def get_input_param_optimizer(input_img):
# this line to show that input is a parameter that requires a gradient
input_param = nn.Parameter(input_img.data)
optimizer = optim.LBFGS([input_param])
return input_param, optimizer
def train():
...
model, style_losses, content_losses = get_model_and_losses(style_img, content_img, style_weight, content_weight)
input_param, optimizer = get_input_param_optimizer(input_img)
print('Optimizing..')
run = [0]
while run[0] <= num_steps:
def closure():
# correct the values of updated input image
input_param.data.clamp_(0, 1)
optimizer.zero_grad()
model(input_param)
style_score = 0
content_score = 0
for sl in style_losses:
style_score += sl.backward()
for cl in content_losses:
content_score += cl.backward()
run[0] += 1
if run[0] % 50 == 0:
print("run {}:".format(run))
print('Style Loss : {:4f} Content Loss: {:4f}'.format(
style_score.data[0], content_score.data[0]))
print()
return style_score + style_score
optimizer.step(closure)
input_param.data.clamp_(0, 1)
output = input_param.data
效果图
- 莫奈(900 次迭代的结果):

- 毕加索(900 次迭代的结果):

- 毕加索(300 次迭代的结果):
这 300 次的结果是不是感觉比 900 次的结果要好看?!
后话:谷歌最近又开源了一个库 Tensor2Tensor,号称 One Model To Learn Them All;苹果的 Core ML 几行代码就可以导入并使用训练好的模型...进击的巨人们啊!
