原文地址:https://hechao.li/2018/06/25/Rate-Limiter-Part1/
概论
通常,流量限制用于控制资源的消耗速率。 例如,服务器每分钟最多可以提供10个请求。 或者每秒最多可以向网络发送1MB数据。 流量限制对于保护系统不会过载是必要的。
算法
有许多限流算法。 我只列出其中的几个。 我们假设用例是限制对服务器的请求率。 可以在Github上找到本文中的代码。 对于下面的所有实现,我们假设有一个RateLimiter类和一个驱动程序类,定义如下:
RateLimiter类:
public abstract class RateLimiter {
protected final int maxRequestPerSec;
protected RateLimiter(int maxRequestPerSec) {
this.maxRequestPerSec = maxRequestPerSec;
}
abstract boolean allow();
}
驱动类:
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
public class Main {
public static void main(String[] args) throws InterruptedException {
final int MAX_REQUESTS_PER_SEC = 10;
RateLimiter rateLimiter = ; // new a RateLimiter here
Thread requestThread = new Thread(() -> {
sendRequest(rateLimiter, 10, 1);
sendRequest(rateLimiter, 20, 2);
sendRequest(rateLimiter,50, 5);
sendRequest(rateLimiter,100, 10);
sendRequest(rateLimiter,200, 20);
sendRequest(rateLimiter,250, 25);
sendRequest(rateLimiter,500, 50);
sendRequest(rateLimiter,1000, 100);
});
requestThread.start();
requestThread.join();
}
private static void sendRequest(RateLimiter rateLimiter, int totalCnt, int requestPerSec) {
long startTime = System.currentTimeMillis();
CountDownLatch doneSignal = new CountDownLatch(totalCnt);
for (int i = 0; i < totalCnt; i++) {
try {
new Thread(() -> {
while (!rateLimiter.allow()) {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
doneSignal.countDown();
}).start();
TimeUnit.MILLISECONDS.sleep(1000 / requestPerSec);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
doneSignal.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
double duration = (System.currentTimeMillis() - startTime) / 1000.0;
System.out.println(totalCnt + " requests processed in " + duration + " seconds. "
+ "Rate: " + (double) totalCnt / duration + " per second");
}
}
Leaky Bucket(漏桶)
下图完美地说明了漏桶算法。
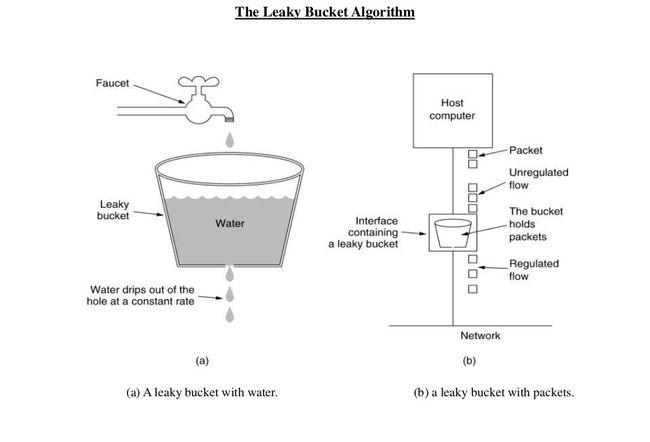
该图显示了漏桶算法在流量整形中的用法。 如果我们将其限制请求映射到服务器用例,则来自水龙头的水滴是请求,桶是请求队列,从桶中泄漏的水滴是响应。 正如水落到满桶时会溢出,队列变满后到达的请求将被拒绝。
正如我们所看到的,在漏桶算法中,请求以大致恒定的速率处理,从而平滑了请求的突发。 即使传入的请求可能是突发性的,传出的响应也始终处于相同的速率。
用于演示目的的简单实现:
public class LeakyBucket extends RateLimiter {
private long nextAllowedTime;
private final long REQUEST_INTERVAL_MILLIS;
protected LeakyBucket(int maxRequestPerSec) {
super(maxRequestPerSec);
REQUEST_INTERVAL_MILLIS = 1000 / maxRequestPerSec;
nextAllowedTime = System.currentTimeMillis();
}
@Override
boolean allow() {
long curTime = System.currentTimeMillis();
synchronized (this) {
if (curTime >= nextAllowedTime) {
nextAllowedTime = curTime + REQUEST_INTERVAL_MILLIS;
return true;
}
return false;
}
}
}
Token Bucket(令牌桶)
假设存储桶中有一些令牌。 当请求到来时,必须从存储桶中获取令牌以便对其进行处理。 如果存储桶中没有可用的令牌,则该请求将被拒绝,请求者必须稍后重试。 令牌桶也按时间单位重新填充。
通过这种方式,我们可以通过为每个用户分配具有固定数量令牌的存储桶来限制每个用户每个时间单位的请求。 当用户在一段时间内用完所有令牌时,我们知道他已超出限制并拒绝他的请求,直到他的桶被重新填充。
我们可以看到,在令牌桶算法中,请求处理速率没有上限,这意味着它只保证平均处理速率不会超过最大速率。 但在某些时期,实时处理速率可能高于最大值。
用于演示目的的简单实现:
mport java.util.concurrent.TimeUnit;
public class TokenBucket extends RateLimiter {
private int tokens;
public TokenBucket(int maxRequestsPerSec) {
super(maxRequestsPerSec);
this.tokens = maxRequestsPerSec;
new Thread(() -> {
while (true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
refillTokens(maxRequestsPerSec);
}
}).start();
}
@Override
public boolean allow() {
synchronized (this) {
if (tokens == 0) {
return false;
}
tokens--;
return true;
}
}
private void refillTokens(int cnt) {
synchronized (this) {
tokens = Math.min(tokens + cnt, maxRequestPerSec);
notifyAll();
}
}
}
在这个程序中,我们有两个线程。 一个人不停地从桶中请求令牌,一个人不断地重新装满桶。 在第一阶段,请求率为每秒1。 在第二阶段,请求率为每秒2。 等等等等。 如果我们运行驱动程序类,我们可以得到以下结果:
10 requests processed in 10.043 seconds. Rate: 0.9957184108334164 per second
20 requests processed in 10.073 seconds. Rate: 1.9855058076044871 per second
50 requests processed in 10.177 seconds. Rate: 4.913039206052865 per second
100 requests processed in 10.357 seconds. Rate: 9.655305590421937 per second
200 requests processed in 19.536 seconds. Rate: 10.237510237510238 per second
250 requests processed in 25.074 seconds. Rate: 9.97048735742203 per second
500 requests processed in 50.203 seconds. Rate: 9.959564169471943 per second
1000 requests processed in 100.36 seconds. Rate: 9.964129135113591 per second
从结果中,我们看到在第一阶段,处理速率为每秒1,与请求速率相同,因为它尚未达到最大限制(10个令牌/秒)。 当请求率分别为每秒2和5时,第二和第三阶段相同。 然后从第四阶段开始,请求率已超过限制。 但是使用令牌桶速率限制机制,平均处理速率可以控制在每秒10左右。
上面的代码有所改进 - 我们可以在请求到来时延迟重新填充,而不是使用专用线程来为存储桶添加固定数量的令牌。 要重新填充的令牌数量等于(current time - last refill time) * max allowed tokens per time unit。 改进后的实现:
public class TokenBucketLazyRefill extends RateLimiter {
private int tokens;
private long lastRefillTime;
public TokenBucketLazyRefill(int maxRequestPerSec) {
super(maxRequestPerSec);
this.tokens = maxRequestPerSec;
this.lastRefillTime = System.currentTimeMillis();
}
@Override
public boolean allow() {
synchronized (this) {
refillTokens();
if (tokens == 0) {
return false;
}
tokens--;
return true;
}
}
private void refillTokens() {
long curTime = System.currentTimeMillis();
double secSinceLastRefill = (curTime - lastRefillTime) / 1000.0;
int cnt = (int) (secSinceLastRefill * maxRequestPerSec);
if (cnt > 0) {
tokens = Math.min(tokens + cnt, maxRequestPerSec);
lastRefillTime = curTime;
}
}
}
固定窗口计数器(Fixed Window Counter)
固定窗口计数器算法将时间线划分为固定大小的窗口,并为每个窗口分配计数器。 每个请求根据其到达时间映射到一个窗口。 如果窗口中的计数器已达到限制,则应拒绝落入此窗口的请求。 例如,如果我们将窗口大小设置为1分钟。 然后窗口是[00:00, 00:01), [00:01, 00:02), ...[23:59, 00:00)。 假设限制是每分钟2个请求:
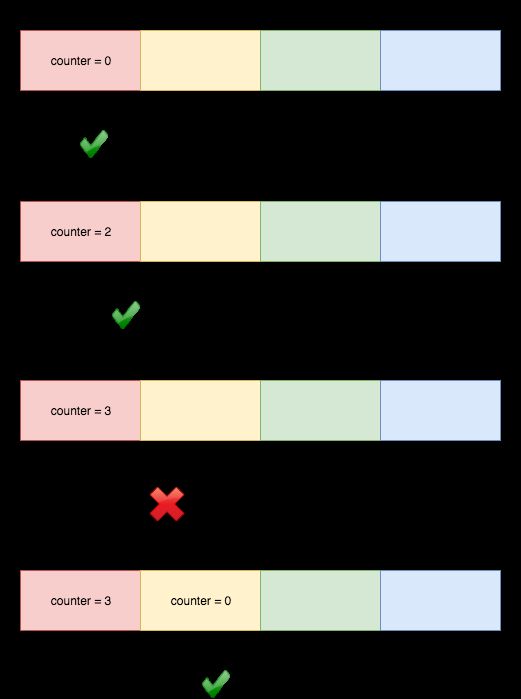
00:00:24的请求属于窗口1,它将窗口的计数器增加到1.下一个请求在00:00:36也属于窗口1,窗口的计数器变为2.下一个请求来自 00:00:49因为计数器超出限制而被拒绝。 然后可以提供00:01:12的请求,因为它属于窗口2。
用于演示目的的简单实现:
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.atomic.AtomicInteger;
public class FixedWindowCounter extends RateLimiter {
// TODO: Clean up stale entries
private final ConcurrentMap windows = new ConcurrentHashMap<>();
protected FixedWindowCounter(int maxRequestPerSec) {
super(maxRequestPerSec);
}
@Override
boolean allow() {
long windowKey = System.currentTimeMillis() / 1000 * 1000;
windows.putIfAbsent(windowKey, new AtomicInteger(0));
return windows.get(windowKey).incrementAndGet() <= maxRequestPerSec;
}
}
上面的代码中省略了清理陈旧条目。 我们可以定期清理陈旧的窗口。 例如,安排在00:00:00运行的任务以删除前一天创建的所有条目。
从实现的角度来看,这种方法的一个优点是,与令牌桶不同,我们必须在从其获取令牌时锁定桶,我们可以使用原子操作来增加每个窗口中的计数器以使代码无锁。
显然,固定窗口计数器算法仅保证每个窗口内的平均速率,但不保证跨窗口。 例如,如果预期的速率是每分钟2个请求,并且在00:00:58和00:00:59有2个请求,在00:01:01和00:01:02有2个请求。 那么窗口[00:00, 00:01)和窗口[00:01, 00:02)的速率是每分钟2个请求。 但是窗口[00:00:30, 00:01:30)的速度实际上是每分钟4个请求。
滑动窗口日志(Sliding Window Log)
滑动窗口日志算法为每个用户保留请求时间戳的日志。 当请求到来时,我们首先弹出所有过时的时间戳,然后将新的请求时间附加到日志中。 然后我们根据日志大小是否超出限制来决定是否应该处理此请求。 例如,假设速率限制是每分钟2个请求:

用于演示目的的简单实现:
import java.util.LinkedList;
import java.util.Queue;
public class SlidingWindowLog extends RateLimiter {
private final Queue log = new LinkedList<>();
protected SlidingWindowLog(int maxRequestPerSec) {
super(maxRequestPerSec);
}
@Override
boolean allow() {
long curTime = System.currentTimeMillis();
long boundary = curTime - 1000;
synchronized (log) {
while (!log.isEmpty() && log.element() <= boundary) {
log.poll();
}
log.add(curTime);
return log.size() <= maxRequestPerSec;
}
}
}
虽然在上面的实现中我们在对日志执行操作时使用锁,但实际上,Redis的有序集和ZREMRANGEBYSCORE命令可以提供原子操作来完成此操作。
在固定窗口计数器上滑动窗口日志的优点在于,它不是确保每个窗口内的平均速率,而是提供更准确的速率限制,因为窗口边界是动态的而不是固定的。 例如,如果时间单位为1分钟,则固定窗口计数器保证窗口[00:00, 00:01),[00:01,00:02)等的平均速率。但滑动窗口日志保证每个请求到达时间t,窗口中的速率(t-1,t)不会超过限制。
这种方法的缺点是其内存占用。 我们注意到,即使请求被拒绝,其请求时间也会记录在日志中,使日志无限制。
滑动窗口(Sliding Window)
滑动窗口计数器类似于固定窗口计数器,但它通过在前一窗口中将加权计数添加到当前窗口中的计数来平滑流量突发。 例如,假设限制为每分钟10次。 窗口[00:00, 00:01)中有9个请求,窗口[00:01, 00:02)中有5个请求。 如果请求到达00:01:15,即窗口[00:01, 00:02)的25%位置,我们按公式计算请求数:9 x(1 - 25%)+ 5 = 14.75 > 10.因此,我们拒绝这一要求。 即使两个窗口都没有超过限制,请求也会被拒绝,因为前一窗口和当前窗口的加权总和确实超过了限制。
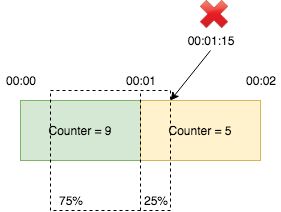
这仍然不准确,因为它假设前一窗口中的请求分布是偶数,这可能不是真的。 但是比较固定窗口计数器,它只保证每个窗口内的速率,而滑动窗口日志,具有巨大的内存占用,滑动窗口更实用。
用于演示目的的简单实现:
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.atomic.AtomicInteger;
public class SlidingWindow extends RateLimiter {
// TODO: Clean up stale entries
private final ConcurrentMap windows = new ConcurrentHashMap<>();
protected SlidingWindow(int maxRequestPerSec) {
super(maxRequestPerSec);
}
@Override
boolean allow() {
long curTime = System.currentTimeMillis();
long curWindowKey = curTime / 1000 * 1000;
windows.putIfAbsent(curWindowKey, new AtomicInteger(0));
long preWindowKey = curWindowKey - 1000;
AtomicInteger preCount = windows.get(preWindowKey);
if (preCount == null) {
return windows.get(curWindowKey).incrementAndGet() <= maxRequestPerSec;
}
double preWeight = 1 - (curTime - curWindowKey) / 1000.0;
long count = (long) (preCount.get() * preWeight
+ windows.get(curWindowKey).incrementAndGet());
return count <= maxRequestPerSec;
}
}
这样假设, 先把一分钟划分成6段! 也就是10s一个段!在第一段里,假如请求61次,那么直接触发了规则!肯定就过不去了!如果只请求了1次!则是正常的! 当时间走到第二个段里,即10s~20s这段范围里,我请求数不能超过总的限定条件,且当前段的请求数量 加上 之前段的总数量也不能超过总限定数量!
当时间到了50s~60s,依然是一样!
如果过了60s,所以请求数都是正常的,则把划分段往右移一段!那么此时的6个分段是 10 ~ 20,20 ~ 30,30 ~ 40,40 ~ 50,50 ~ 60,60 ~ 70
然后统计规则还跟上面一样!
所以,只有划分的越细,请求限制越平滑!
结束语
在本文中,我们学习了几种限流算法及其简单实现。 在下一篇文章中,我们将分析Google guava库是如何实现限流的。
参考
[1] Leaky Bucket & Tocken Bucket - Traffic shaping
[2] How to Design a Scalable Rate Limiting Algorithm
[3] An alternative approach to rate limiting
[4] Better Rate Limiting With Redis Sorted Sets