*本篇文章已授权微信公众号 guolin_blog (郭霖)独家发布
在JDK 1.5之后,java提供了对注解的支持,这些注解与普通代码一样,在运行期间发挥作用。在JDK 1.6中实现了JSR-269规范,提供了一组插入式注解处理器的标准API在编译期间对注解进行处理,可以看作是一组编译器的插件,可以读取/修改/添加抽象语法树中的任意元素。
在Android模块开发之APT技术介绍了自定义注解处理器的一些知识,自定义注解处理器注册才能被Java虚拟机调用,在上面的博客第四小节中用的方法是手动注册,这比较违反程序员懒的特点,在里面也提到了自动注册的方法,就是AutoService,今天这篇博客就是来扒一扒谷歌提供的这个开源库。
先通过一个栗子看下AutoService怎么用的。
1.使用
定义一个简单的接口:
public interface Display {
String display();
}
有两个Module A和B分别实现了这个接口,然后在app Module中调用这两个实现类, 比较低级的办法就是在app Module中直接依赖这两个模块,然后就可以调用实现类了。这有两个坏处,一个是app Module直接强依赖A和B两个Module,另外如果开发中拿不到依赖的模块呢,有可能模块是第三方的,这个时候强依赖这种方式就行不通了。
看下AutoService是怎么实现的,先看下包结构,interfaces只简单包含上面的Display接口,modulea和moduleb实现这个接口,app统一加载所有这个接口的实现类。
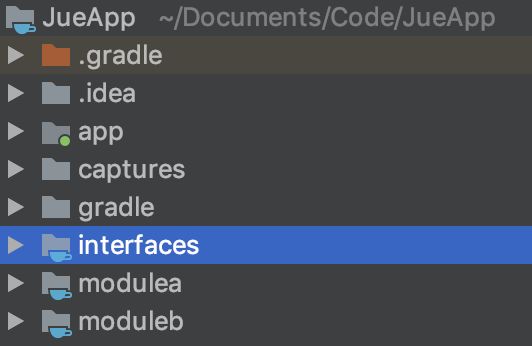
看下modulea和moduleb实现,方法实现里面简单返回一个字符串,主要是上面的@AutoService(Display.class)注解,注解值是接口的名称,也就是implements实现的类接口名称。
// modulea
import com.google.auto.service.AutoService;
@AutoService(Display.class)
public class ADisplay implements Display{
@Override
public String display() {
return "A Display";
}
}
// moduleb
@AutoService(Display.class)
public class BDisplay implements Display {
@Override
public String display() {
return "B Display";
}
}
再看下app Module里面的怎么调用上面的ADispaly和BDisplay,加载原理就是通过ServiceLoader去加载,可以得到接口Display的所有实现类,在我们这个栗子中就是上面的ADisplay和BDisplay两个实现者。DisplayFactory通过getDisplay可以拿到所有的实现类。
import com.example.juexingzhe.interfaces.Display;
import java.util.Iterator;
import java.util.ServiceLoader;
public class DisplayFactory {
private static DisplayFactory mDisplayFactory;
private Iterator mIterator;
private DisplayFactory() {
ServiceLoader loader = ServiceLoader.load(Display.class);
mIterator = loader.iterator();
}
public static DisplayFactory getSingleton() {
if (null == mDisplayFactory) {
synchronized (DisplayFactory.class) {
if (null == mDisplayFactory) {
mDisplayFactory = new DisplayFactory();
}
}
}
return mDisplayFactory;
}
public Display getDisplay() {
return mIterator.next();
}
public boolean hasNextDisplay() {
return mIterator.hasNext();
}
}
使用就是这么几个步骤,比较简单,下面看下AutoService实现原理。
2.实现原理
首先先简单介绍下Javac的编译过程,大致可以分为3个过程:
- 解析与填充符号表
- 插入式注解处理器的注解处理过程
- 分析与字节码生成过程
看下一个图片,图片来源深入理解Java虚拟机,首先会进行词法和语法分析,词法分析将源代码的字符流转变为Token集合,关键字/变量名/字面量/运算符读可以成为Token,词法分析过程由com.sun.tools.javac.parserScanner类实现;
语法分析是根据Token序列构造抽象语法树的过程,抽象语法树AST是一种用来描述程序代码语法结构的树形表示,语法树的每一个节点读代表着程序代码中的一个语法结构,例如包/类型/修饰符/运算符/接口/返回值/代码注释等,在javac的源码中,语法分析是由com.sun.tools.javac.parser.Parser类实现,这个阶段产出的抽象语法树由com.sun.tools.javac.tree.JCTree类表示。经过上面两个步骤编译器就基本不会再对源码文件进行操作了,后续的操作读建立在抽象语法树上。
完成了语法和词法分析后就是填充符号表的过程。符号表是由一组符号地址和符号信息构成的表格。填充符号表的过程由com.sun.tools.javac.comp.Enter类实现。
如前面介绍的,如果注解处理器在处理注解期间对语法树进行了修改,编译器将回到解析与填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环称为一个Round,如下图中的环。

上面简单回顾了下编译注解的一些东西,接下来看下AutoService这个注解的实现,使用它有三个限定条件;
- 不能是内部类和匿名类,必须要有确定的名称
- 必须要有公共的,可调用的无参构造函数
- 使用这个注解的类必须要实现value参数定义的接口
@Documented
@Target(TYPE)
public @interface AutoService {
/** Returns the interface implemented by this service provider. */
Class value();
}
有注解,必须要有对应的注解处理器,AutoServiceProcessor继承AbstractProcessor,一般我们会实现其中的3个方法, 在getSupportedAnnotationTypes中返回了支持的注解类型AutoService.class;getSupportedSourceVersion ,用来指定支持的java版本,一般来说我们都是支持到最新版本,因此直接返回 SourceVersion.latestSupported()即可;主要还是process方法。
public class AutoServiceProcessor extends AbstractProcessor {
@Override
public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latestSupported();
}
@Override
public Set getSupportedAnnotationTypes() {
return ImmutableSet.of(AutoService.class.getName());
}
@Override
public boolean process(Set set, RoundEnvironment roundEnvironment) {
try {
return processImpl(annotations, roundEnv);
} catch (Exception e) {
// We don't allow exceptions of any kind to propagate to the compiler
StringWriter writer = new StringWriter();
e.printStackTrace(new PrintWriter(writer));
fatalError(writer.toString());
return true;
}
}
}
process方法调用processImpl,接着看下这个方法的实现,先看下方法实现,就两个逻辑判断,如果上一次循环中注解处理器已经处理完了,就调用generateConfigFiles生成MEATA_INF配置文件;如果上一轮没有处理就调用processAnnotations处理注解。返回true就代表改变或者生成语法树中的内容;返回false就是没有修改或者生成,通知编译器这个Round中的代码未发生变化。
private boolean processImpl(Set annotations, RoundEnvironment roundEnv) {
if (roundEnv.processingOver()) {
generateConfigFiles();
} else {
processAnnotations(annotations, roundEnv);
}
return true;
}
再接着往下看代码之前先看下两个环境变量,RoundEnvironment和ProcessingEnvironment。
RoundEnvironment提供了访问到当前这个Round中语法树节点的功能,每个语法树节点在这里表示为一个Element,在javax.lang.model包中定义了16类Element,包括常用的元素:包,枚举,类,注解,接口,枚举值,字段,参数,本地变量,异常,方法,构造函数,静态语句块即static{}块,实例语句块即{}块,参数化类型即反省尖括号内的类型,还有未定义的其他语法树节点。
public enum ElementKind {
PACKAGE,
ENUM,
CLASS,
ANNOTATION_TYPE,
INTERFACE,
ENUM_CONSTANT,
FIELD,
PARAMETER,
LOCAL_VARIABLE,
EXCEPTION_PARAMETER,
METHOD,
CONSTRUCTOR,
STATIC_INIT,
INSTANCE_INIT,
TYPE_PARAMETER,
OTHER,
RESOURCE_VARIABLE;
private ElementKind() {
}
public boolean isClass() {
return this == CLASS || this == ENUM;
}
public boolean isInterface() {
return this == INTERFACE || this == ANNOTATION_TYPE;
}
public boolean isField() {
return this == FIELD || this == ENUM_CONSTANT;
}
}
看下RoundEnvironment的源码,errorRaised方法返回上一轮注解处理器是否产生错误;getRootElements返回上一轮注解处理器生成的根元素;最后两个方法返回包含指定注解类型的元素的集合,画重点,这个就是我们自定义注解处理器需要经常打交道的方法。
public interface RoundEnvironment {
boolean processingOver();
boolean errorRaised();
Set getRootElements();
Set getElementsAnnotatedWith(TypeElement var1);
Set getElementsAnnotatedWith(Class var1);
}
另外一个参数ProcessingEnvironment,在注解处理器初始化的时候(init()方法执行的时候)创建,代表了注解处理器框架提供的一个上下文环境,要创建新的代码或者向编译器输出信息或者获取其他工具类等都需要用到这个实例变量。看下它的源码。
-
Messager用来报告错误,警告和其他提示信息; -
Filer用来创建新的源文件,class文件以及辅助文件; -
Elements中包含用于操作Element的工具方法; -
Types中包含用于操作类型TypeMirror的工具方法;
public interface ProcessingEnvironment {
Map getOptions();
Messager getMessager();
Filer getFiler();
Elements getElementUtils();
Types getTypeUtils();
SourceVersion getSourceVersion();
Locale getLocale();
}
介绍完一些基础变量后,我们就接着上面先看下processAnnotations方法,方法看起来有点长,但是结构很简单,首先第一步通过RoundEnvironment的getElementsAnnotatedWith(AutoService.class)拿到所有的标注了AutoService注解的元素。
private void processAnnotations(Set annotations,
RoundEnvironment roundEnv) {
// 1.
Set elements = roundEnv.getElementsAnnotatedWith(AutoService.class);
log(annotations.toString());
log(elements.toString());
for (Element e : elements) {
// TODO(gak): check for error trees?
// 2.
TypeElement providerImplementer = (TypeElement) e;
// 3.
AnnotationMirror providerAnnotation = getAnnotationMirror(e, AutoService.class).get();
// 4.
DeclaredType providerInterface = getProviderInterface(providerAnnotation);
TypeElement providerType = (TypeElement) providerInterface.asElement();
log("provider interface: " + providerType.getQualifiedName());
log("provider implementer: " + providerImplementer.getQualifiedName());
// 5.
if (!checkImplementer(providerImplementer, providerType)) {
String message = "ServiceProviders must implement their service provider interface. "
+ providerImplementer.getQualifiedName() + " does not implement "
+ providerType.getQualifiedName();
error(message, e, providerAnnotation);
}
// 6.
String providerTypeName = getBinaryName(providerType);
String providerImplementerName = getBinaryName(providerImplementer);
log("provider interface binary name: " + providerTypeName);
log("provider implementer binary name: " + providerImplementerName);
providers.put(providerTypeName, providerImplementerName);
}
}
public static Optional getAnnotationMirror(Element element,
Class annotationClass) {
String annotationClassName = annotationClass.getCanonicalName();
for (AnnotationMirror annotationMirror : element.getAnnotationMirrors()) {
TypeElement annotationTypeElement = asType(annotationMirror.getAnnotationType().asElement());
if (annotationTypeElement.getQualifiedName().contentEquals(annotationClassName)) {
return Optional.of(annotationMirror);
}
}
return Optional.absent();
}
AutoService只能作用于非内部非匿名类或者接口,第二步在for循环中强转Element为TypeElement,这个就是被AutoService标注的元素,这里简称为T。接下来这个可能让人容易乱,在前面说过每一个javac是一个循环过程,在第一次扫描到AutoService注解的时候是还没有T的class对象,所以也就不能通过反射来拿到这个注解和注解的参数值value。这个时候第三步就得通过AnnotationMirror,用来表示一个注解,通过它可以拿到注解类型和注解参数。在getAnnotationMirror会判断这个T的注解(通过element.getAnnotationMirrors())名称是不是等于AutoService,相等就返回这个AutoService的AnnotationMirror。
public interface AnnotationMirror {
DeclaredType getAnnotationType();
Map getElementValues();
}
拿到这个注解了,接下来就是要拿到注解的参数value值了,这个在第四步getProviderInterface方法中完成。
private DeclaredType getProviderInterface(AnnotationMirror providerAnnotation) {
Map valueIndex =
providerAnnotation.getElementValues();
log("annotation values: " + valueIndex);
AnnotationValue value = valueIndex.values().iterator().next();
return (DeclaredType) value.getValue();
}
这里也是同上面的原因,在这个阶段我们不可能通过下面的代码反射来拿到注解的参数值,因为这个时候还拿不到class对象。所以上面费了很大的劲去通过AnnotationMirror来拿到注解的参数值,在我们这个栗子中就是Display.class了。
AutoService autoservice = e.getAnnotation(AutoService.class);
Class providerInterface = autoservice.value()
接下来第5步检查类型T是不是实现了注解参数值说明的接口,也就是ADisplay和BDisplay是不是实现了Display接口,没有实现肯定就是没有意义了。第6步就是获取到接口名和实现类名,注册到map中,类似于MapAutoService标注的实现类。
通过上面的步骤就已经扫描得到了所有的通过AutoService标注的实现类和对应接口的映射关系,并且在processImpl里面返回了true,下个Round就是生成配置文件了。看下processImpl if分支里面的generateConfigFiles方法。
private void generateConfigFiles() {
Filer filer = processingEnv.getFiler();
// 1.
for (String providerInterface : providers.keySet()) {
String resourceFile = "META-INF/services/" + providerInterface;
log("Working on resource file: " + resourceFile);
try {
SortedSet allServices = Sets.newTreeSet();
try {
// 2.
FileObject existingFile = filer.getResource(StandardLocation.CLASS_OUTPUT, "",
resourceFile);
log("Looking for existing resource file at " + existingFile.toUri());
// 3.
Set oldServices = ServicesFiles.readServiceFile(existingFile.openInputStream());
log("Existing service entries: " + oldServices);
allServices.addAll(oldServices);
} catch (IOException e) {
// According to the javadoc, Filer.getResource throws an exception
// if the file doesn't already exist. In practice this doesn't
// appear to be the case. Filer.getResource will happily return a
// FileObject that refers to a non-existent file but will throw
// IOException if you try to open an input stream for it.
log("Resource file did not already exist.");
}
// 4.
Set newServices = new HashSet(providers.get(providerInterface));
if (allServices.containsAll(newServices)) {
log("No new service entries being added.");
return;
}
allServices.addAll(newServices);
log("New service file contents: " + allServices);
// 5.
FileObject fileObject = filer.createResource(StandardLocation.CLASS_OUTPUT, "",
resourceFile);
OutputStream out = fileObject.openOutputStream();
ServicesFiles.writeServiceFile(allServices, out);
out.close();
log("Wrote to: " + fileObject.toUri());
} catch (IOException e) {
fatalError("Unable to create " + resourceFile + ", " + e);
return;
}
}
}
主要分成5个步骤要生成配置文件,分别来看下:
- 第一步遍历上面拿到的映射关系map providers,我们这里就是com.example.juexingzhe.interfaces.Display,然后生成文件名resourceFile =
META-INF/services/com.example.juexingzhe.interfaces.Display - 第二步先检查下在类编译class输出位置有没有存在配置文件,
- 第三步就是如果第二步存在配置文件,需要把接口和所有实现类保存到
allServices中 - 第四步检查
processAnnotations方法输出的映射map是否不存在上面的allServices,不存在则添加,存在则直接返回不需要生成新的文件 - 第五步就是通过Filer生成配置文件,文件名就是
resourceFile,文件内容就是allServices中的所有实现类。
最后我们看下编译编译的结果,在每个module中都会生成配置文件
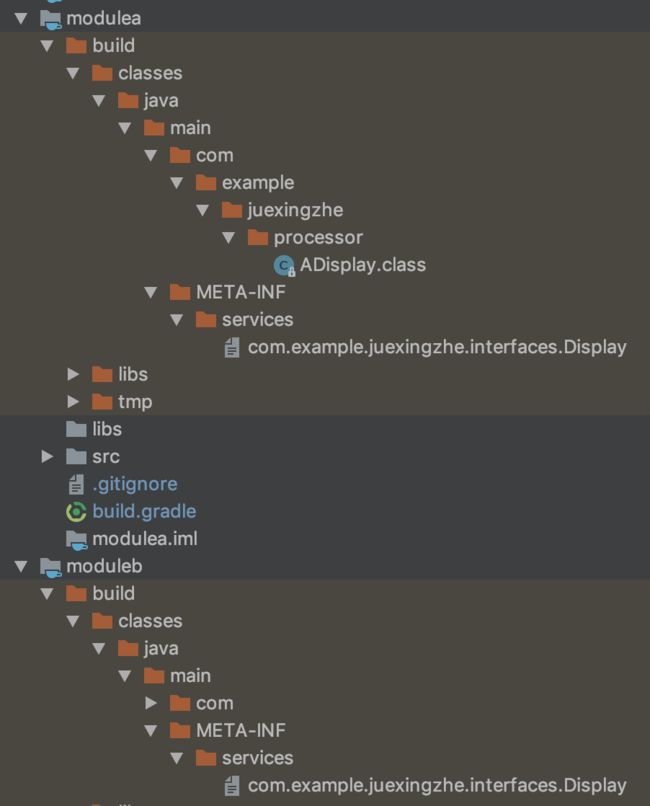
最后在apk中会合并所有的META-INF文件目录,可以看到在接口文件Display下面包含了所有module中通过AutoService注解标注的实现类。
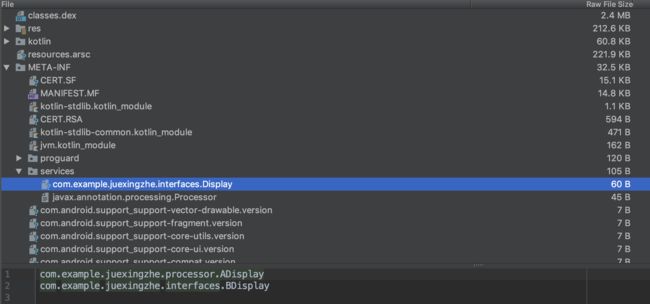
最后通过ServiceLoader就可以通过反射拿到所有的实现类,ServiceLoader的源码分析可以参考我的另外一片博客Android模块开发之SPI.
3.总结
这次的源码分析其实是完成之前在Android模块开发之APT技术立下的flag,到今天才补上有点惭愧。AutoService源码解析结合APT和SPI服用效果可能更佳哦。
这个也是组件化技术中常用的一个技术点,后面会再更新一些组件化gradle相关的一些知识,有需要的小伙伴们欢迎关注。
完。
参考:
深入理解Java虚拟机