前言
我们每天都在与Java堆打交道,对它的组成与调优都有了比较深刻的理解。Java堆的简单示意图如下。
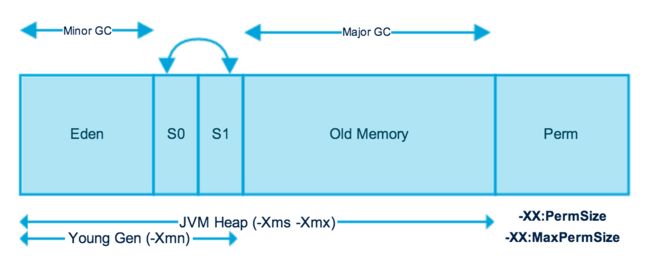
不过,你有没有想过堆空间到底是怎么产生的呢?要搞清楚这个问题,就得通过阅读JVM的源码来追根究底了。本文分析的是OpenJDK 7u版本的源码,OpenJDK源码可以在其非官方的GitHub Repo上clone。建议用一个趁手的C/C++ IDE导入源码,方便阅读,我用的是CLion。
Java堆初始化的入口为Universe::initialize_heap()方法,位于hotspot/src/share/vm/memory/universe.cpp文件中。下面开始咯。
根据GC方式确定GC策略与堆实现
这部分的源码如下。
if (UseParallelGC) {
#ifndef SERIALGC
Universe::_collectedHeap = new ParallelScavengeHeap();
#else // SERIALGC
fatal("UseParallelGC not supported in java kernel vm.");
#endif // SERIALGC
} else if (UseG1GC) {
#ifndef SERIALGC
G1CollectorPolicy* g1p = new G1CollectorPolicy();
G1CollectedHeap* g1h = new G1CollectedHeap(g1p);
Universe::_collectedHeap = g1h;
#else // SERIALGC
fatal("UseG1GC not supported in java kernel vm.");
#endif // SERIALGC
} else {
GenCollectorPolicy *gc_policy;
if (UseSerialGC) {
gc_policy = new MarkSweepPolicy();
} else if (UseConcMarkSweepGC) {
#ifndef SERIALGC
if (UseAdaptiveSizePolicy) {
gc_policy = new ASConcurrentMarkSweepPolicy();
} else {
gc_policy = new ConcurrentMarkSweepPolicy();
}
#else // SERIALGC
fatal("UseConcMarkSweepGC not supported in java kernel vm.");
#endif // SERIALGC
} else { // default old generation
gc_policy = new MarkSweepPolicy();
}
Universe::_collectedHeap = new GenCollectedHeap(gc_policy);
}
jint status = Universe::heap()->initialize();
if (status != JNI_OK) {
return status;
}
该段代码的执行流程是:
- 如果JVM使用了并行收集器(
-XX:+UseParallelGC),则将堆初始化为ParallelScavengeHeap类型,即并行收集堆。 - 如果JVM使用了G1收集器(
-XX:+UseG1GC),则将堆初始化为G1CollectedHeap类型,即G1堆。同时设置GC策略为G1专用的G1CollectorPolicy。 - 如果没有选择以上两种收集器,就继续检查是否使用了串行收集器(
-XX:+UseSerialGC),如是,设置GC策略为MarkSweepPolicy,即标记-清除。 - 再检查到如果使用了CMS收集器(
-XX:+UseConcMarkSweepGC),就根据是否启用自适应开关(-XX:+UseAdaptiveSizePolicy),设置GC策略为自适应的ASConcurrentMarkSweepPolicy,或者标准的ConcurrentMarkSweepPolicy。 - 如果以上情况都没有配置,就采用默认的GC策略为MarkSweepPolicy。对于步骤3~5的所有情况,都会将堆初始化为GenCollectedHeap类型,即分代收集堆。
- 调用各堆实现类对应的initialize()方法执行堆的初始化操作。
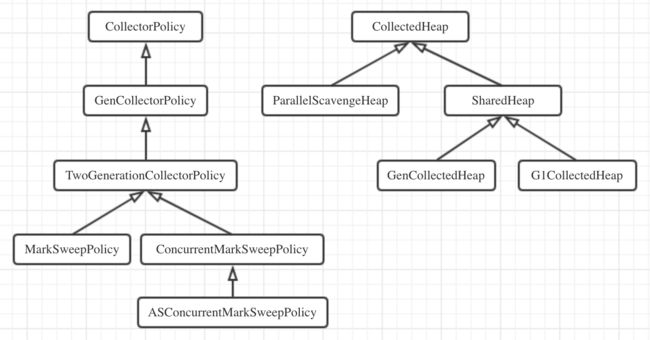
下图示出分代GC策略类以及各堆实现类的继承体系。
构造GC策略与堆参数
为了方便讲解,我们以较常用的CMS标准GC策略ConcurrentMarkSweepPolicy为例来探讨。先来看其构造方法。
ConcurrentMarkSweepPolicy::ConcurrentMarkSweepPolicy() {
initialize_all();
}
该initialize_all()方法由ConcurrentMarkSweepPolicy的父类GenCollectorPolicy来定义。
virtual void initialize_all() {
initialize_flags();
initialize_size_info();
initialize_generations();
}
可见,这个方法直接调用了另外三个以initialize为前缀的方法,它们分别完成特定的功能,下面按顺序来看。
initialize_flags()方法:对齐与校验
GenCollectorPolicy::initialize_flags()方法的源码如下。
void GenCollectorPolicy::initialize_flags() {
// All sizes must be multiples of the generation granularity.
set_min_alignment((uintx) Generation::GenGrain);
set_max_alignment(compute_max_alignment());
CollectorPolicy::initialize_flags();
// All generational heaps have a youngest gen; handle those flags here.
// Adjust max size parameters
if (NewSize > MaxNewSize) {
MaxNewSize = NewSize;
}
NewSize = align_size_down(NewSize, min_alignment());
MaxNewSize = align_size_down(MaxNewSize, min_alignment());
// Check validity of heap flags
assert(NewSize % min_alignment() == 0, "eden space alignment");
assert(MaxNewSize % min_alignment() == 0, "survivor space alignment");
if (NewSize < 3*min_alignment()) {
// make sure there room for eden and two survivor spaces
vm_exit_during_initialization("Too small new size specified");
}
if (SurvivorRatio < 1 || NewRatio < 1) {
vm_exit_during_initialization("Invalid heap ratio specified");
}
}
这个方法首先调用set_min_alignment()/set_max_alignment()设置堆空间的对齐,来看一下最小对齐的定义。
enum SomePublicConstants {
LogOfGenGrain = 16 ARM_ONLY(+1),
GenGrain = 1 << LogOfGenGrain
};
这里定义了分代堆空间的粒度,即216B = 64KB。也就是说各代必须至少按64KB对齐。
最大对齐则通过调用compute_max_alignment()方法来计算,代码如下。注释很有用,所以我留下了。
size_t GenCollectorPolicy::compute_max_alignment() {
// The card marking array and the offset arrays for old generations are
// committed in os pages as well. Make sure they are entirely full (to
// avoid partial page problems), e.g. if 512 bytes heap corresponds to 1
// byte entry and the os page size is 4096, the maximum heap size should
// be 512*4096 = 2MB aligned.
size_t alignment = GenRemSet::max_alignment_constraint(rem_set_name());
// Parallel GC does its own alignment of the generations to avoid requiring a
// large page (256M on some platforms) for the permanent generation. The
// other collectors should also be updated to do their own alignment and then
// this use of lcm() should be removed.
if (UseLargePages && !UseParallelGC) {
// in presence of large pages we have to make sure that our
// alignment is large page aware
alignment = lcm(os::large_page_size(), alignment);
}
assert(alignment >= min_alignment(), "Must be");
return alignment;
}
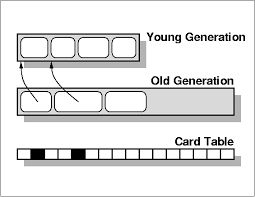
这里可以多说两句。GenRemSet是JVM中维护跨代引用的数据结构,通用名称为“记忆集合”(Remember Set)。对于常见的两分代堆而言,跨代引用就是老生代中存在指向新生代对象的引用,如果不预先维护的话,每次新生代GC都要去扫描老生代,非常麻烦。GenRemSet的经典实现是卡表(CardTableRS),本质是字节数组,每个字节(即一张卡)对应老生代中一段连续的内存是否有跨代引用,如图所示。
那么卡表与最大对齐有什么关系呢?看以下方法。
uintx CardTableModRefBS::ct_max_alignment_constraint() {
return card_size * os::vm_page_size();
}
其中card_size为29 = 512,也就是每张卡对应512B的老生代内存。将它与JVM的普通页大小(一般是4KB)相乘,就是最大对齐。如果JVM启用了大内存分页,就继续用上面的计算结果与大页大小(一般是2MB或4MB)取最小公倍数作为最大对齐。
堆空间对齐设置完了,接下来调用父类CollectorPolicy的同名方法,校验永久代大小(-XX:PermSize、-XX:MaxPermSize)以及一些其他配置。它的流程与本方法实现的校验新生代大小比较像,为节省篇幅,不再给出代码。
我们已经知道,新生代可以通过-XX:NewSize、-XX:MaxNewSize与-Xmn三个参数来设定,设定-Xmn就相当于将前两个参数设为相同的值。接下来就将NewSize与MaxNewSize按64KB向下对齐,并确定它们是64KB的倍数。向下与向上对齐方法的源码如下,基于宏定义,本质是位运算。
#define align_size_down_(size, alignment) ((size) & ~((alignment) - 1))
inline intptr_t align_size_down(intptr_t size, intptr_t alignment) {
return align_size_down_(size, alignment);
}
#define align_size_up_(size, alignment) (((size) + ((alignment) - 1)) & ~((alignment) - 1))
inline intptr_t align_size_up(intptr_t size, intptr_t alignment) {
return align_size_up_(size, alignment);
}
因为新生代由一个Eden区与两个Survivor区组成,所以NewSize不能小于3 * 64 = 192KB。另外,-XX:NewRatio与-XX:SurvivorRatio都不能小于1,亦即老生代与新生代的比例不能小于1:1,Eden区与Survivor区的比例不能小于1:2。
需要注意的是,GenCollectorPolicy的子类TwoGenerationCollectorPolicy中也有一个同名方法。它先调用了父类的方法,然后校验老生代和最大堆大小,代码比较简单,如下。
void TwoGenerationCollectorPolicy::initialize_flags() {
GenCollectorPolicy::initialize_flags();
OldSize = align_size_down(OldSize, min_alignment());
if (NewSize + OldSize > MaxHeapSize) {
MaxHeapSize = NewSize + OldSize;
}
MaxHeapSize = align_size_up(MaxHeapSize, max_alignment());
always_do_update_barrier = UseConcMarkSweepGC;
// Check validity of heap flags
assert(OldSize % min_alignment() == 0, "old space alignment");
assert(MaxHeapSize % max_alignment() == 0, "maximum heap alignment");
}
老生代大小OldSize对应JVM参数中的-XX:OldSize,最大堆大小MaxHeapSize自然对应-Xmx。这样,新生代、老生代和永久代的参数就都对齐并校验完毕了。
initialize_size_info()方法:设置堆与分代大小
与上面的initialize_flags()方法相似,这个方法在CollectorPolicy、GenCollectorPolicy、TwoGenerationCollectorPolicy中各有一个,分别负责真正设置整个堆、新生代和老生代的大小,并且同样是链式调用。它们的代码都很长,但功能单一,都是比较、对齐与赋值操作。选择设置新生代的GenCollectorPolicy::initialize_size_info()来看看。
void GenCollectorPolicy::initialize_size_info() {
CollectorPolicy::initialize_size_info();
size_t max_new_size = 0;
if (FLAG_IS_CMDLINE(MaxNewSize) || FLAG_IS_ERGO(MaxNewSize)) {
if (MaxNewSize < min_alignment()) {
max_new_size = min_alignment();
}
if (MaxNewSize >= max_heap_byte_size()) {
max_new_size = align_size_down(max_heap_byte_size() - min_alignment(),
min_alignment());
warning("MaxNewSize (" SIZE_FORMAT "k) is equal to or "
"greater than the entire heap (" SIZE_FORMAT "k). A "
"new generation size of " SIZE_FORMAT "k will be used.",
MaxNewSize/K, max_heap_byte_size()/K, max_new_size/K);
} else {
max_new_size = align_size_down(MaxNewSize, min_alignment());
}
} else {
max_new_size = scale_by_NewRatio_aligned(max_heap_byte_size());
max_new_size = MIN2(MAX2(max_new_size, NewSize), MaxNewSize);
}
assert(max_new_size > 0, "All paths should set max_new_size");
if (max_heap_byte_size() == min_heap_byte_size()) {
set_min_gen0_size(max_new_size);
set_initial_gen0_size(max_new_size);
set_max_gen0_size(max_new_size);
} else {
size_t desired_new_size = 0;
if (!FLAG_IS_DEFAULT(NewSize)) {
_min_gen0_size = NewSize;
desired_new_size = NewSize;
max_new_size = MAX2(max_new_size, NewSize);
} else {
_min_gen0_size = MAX2(scale_by_NewRatio_aligned(min_heap_byte_size()),
NewSize);
desired_new_size =
MAX2(scale_by_NewRatio_aligned(initial_heap_byte_size()),
NewSize);
}
assert(_min_gen0_size > 0, "Sanity check");
set_initial_gen0_size(desired_new_size);
set_max_gen0_size(max_new_size);
// ...后面一大堆set方法调用,略去...
}
if (PrintGCDetails && Verbose) {
gclog_or_tty->print_cr(/*...*/);
}
}
解释起来肯定很费劲,并且也没有必要逐句读,只说三个值得注意的点。
- 新生代的通用名称其实是gen0。相对地,老生代就是gen1。
- 设定大小时,是先计算MaxNewSize,再计算NewSize。设定之前如果经过了运算,就必须重新对齐。
- 如果用
-XX:MaxNewSize或-Xmn显式指定了新生代最大大小,或者JVM自动优化(Ergonomics)机制更改了该值,-XX:NewRatio的值就会被忽略。NewSize同理。
另外两个initialize_size_info()在代码库中能找到,看官有兴趣的话可以自己去看。
initialize_generations()方法:生成分代管理器
虽然该方法的名字是“初始化分代”的意思,但它还不会执行真正的初始化动作,而是生成GenerationSpec实例,该实例内含有分代的描述信息(名称、大小等),在真正初始化分代时需要用到。这个方法由ConcurrentMarkSweepPolicy自己实现,代码如下。
void ConcurrentMarkSweepPolicy::initialize_generations() {
initialize_perm_generation(PermGen::ConcurrentMarkSweep);
_generations = new GenerationSpecPtr[number_of_generations()];
if (_generations == NULL)
vm_exit_during_initialization("Unable to allocate gen spec");
if (ParNewGeneration::in_use()) {
if (UseAdaptiveSizePolicy) {
_generations[0] = new GenerationSpec(Generation::ASParNew,
_initial_gen0_size, _max_gen0_size);
} else {
_generations[0] = new GenerationSpec(Generation::ParNew,
_initial_gen0_size, _max_gen0_size);
}
} else {
_generations[0] = new GenerationSpec(Generation::DefNew,
_initial_gen0_size, _max_gen0_size);
}
if (UseAdaptiveSizePolicy) {
_generations[1] = new GenerationSpec(Generation::ASConcurrentMarkSweep,
_initial_gen1_size, _max_gen1_size);
} else {
_generations[1] = new GenerationSpec(Generation::ConcurrentMarkSweep,
_initial_gen1_size, _max_gen1_size);
}
if (_generations[0] == NULL || _generations[1] == NULL) {
vm_exit_during_initialization("Unable to allocate gen spec");
}
}
可见,首先调用initialize_perm_generation()方法生成永久代对应的PermanentGenerationSpec(代码略)。然后,检查是否符合ParNewGeneration::in_use()的条件,即启用并行新生代GC(-XX:+UseParNewGC)并且GC线程数(-XX:ParallelGCThreads)>0,如是,将新生代GenerationSpec的类型设置为ParNew,否则设为DefNew。老生代GenerationSpec的类型则固定为ConcurrentMarkSweep。
至此,初始化GC策略与堆参数的工作就完成了,下面主要是分配堆内存空间与分代的过程,还有一些其他的工作。
分配堆内存空间与分代
前面已经说过,各堆实现都有一个initialize()方法用于初始化。GenCollectedHeap::initialize()方法很长,所以我们拆开来看。
最后一次对齐
在创建分代之前,再将它们对齐一次,代码如下。
int i;
_n_gens = gen_policy()->number_of_generations();
guarantee(HeapWordSize == wordSize, "HeapWordSize must equal wordSize");
size_t gen_alignment = Generation::GenGrain;
_gen_specs = gen_policy()->generations();
PermanentGenerationSpec *perm_gen_spec =
collector_policy()->permanent_generation();
size_t heap_alignment = collector_policy()->max_alignment();
for (i = 0; i < _n_gens; i++) {
_gen_specs[i]->align(gen_alignment);
}
perm_gen_spec->align(heap_alignment);
number_of_generations()就是分代数量,这里固定为2。新生代和老生代都是按最小粒度(即64KB)对齐,永久代则是按最大粒度对齐。
分配堆内存空间
代码如下。
char* heap_address;
size_t total_reserved = 0;
int n_covered_regions = 0;
ReservedSpace heap_rs;
heap_address = allocate(heap_alignment, perm_gen_spec, &total_reserved,
&n_covered_regions, &heap_rs);
if (UseSharedSpaces) {
if (!heap_rs.is_reserved() || heap_address != heap_rs.base()) {
if (heap_rs.is_reserved()) {
heap_rs.release();
}
FileMapInfo* mapinfo = FileMapInfo::current_info();
mapinfo->fail_continue("Unable to reserve shared region.");
allocate(heap_alignment, perm_gen_spec, &total_reserved, &n_covered_regions,
&heap_rs);
}
}
if (!heap_rs.is_reserved()) {
vm_shutdown_during_initialization(
"Could not reserve enough space for object heap");
return JNI_ENOMEM;
}
这段代码中起主要作用的是allocate()方法,其本质是将一段连续的内存空间分配成ReservedSpace,即预留空间。下面重点看看allocate()方法的实现,其全貌如下。
char* GenCollectedHeap::allocate(size_t alignment,
PermanentGenerationSpec* perm_gen_spec,
size_t* _total_reserved,
int* _n_covered_regions,
ReservedSpace* heap_rs){
// Now figure out the total size.
size_t total_reserved = 0;
int n_covered_regions = 0;
const size_t pageSize = UseLargePages ?
os::large_page_size() : os::vm_page_size();
assert(alignment % pageSize == 0, "Must be");
for (int i = 0; i < _n_gens; i++) {
total_reserved = add_and_check_overflow(total_reserved, _gen_specs[i]->max_size());
n_covered_regions += _gen_specs[i]->n_covered_regions();
}
assert(total_reserved % alignment == 0,
err_msg("Gen size; total_reserved=" SIZE_FORMAT ", alignment="
SIZE_FORMAT, total_reserved, alignment));
total_reserved = add_and_check_overflow(total_reserved, perm_gen_spec->max_size());
assert(total_reserved % alignment == 0,
err_msg("Perm size; total_reserved=" SIZE_FORMAT ", alignment="
SIZE_FORMAT ", perm gen max=" SIZE_FORMAT, total_reserved,
alignment, perm_gen_spec->max_size()));
n_covered_regions += perm_gen_spec->n_covered_regions();
// Add the size of the data area which shares the same reserved area
// as the heap, but which is not actually part of the heap.
size_t misc = perm_gen_spec->misc_data_size() + perm_gen_spec->misc_code_size();
total_reserved = add_and_check_overflow(total_reserved, misc);
if (UseLargePages) {
assert(misc == 0, "CDS does not support Large Pages");
assert(total_reserved != 0, "total_reserved cannot be 0");
assert(is_size_aligned(total_reserved, os::large_page_size()), "Must be");
total_reserved = round_up_and_check_overflow(total_reserved, os::large_page_size());
}
// Calculate the address at which the heap must reside in order for
// the shared data to be at the required address.
char* heap_address;
if (UseSharedSpaces) {
// Calculate the address of the first word beyond the heap.
FileMapInfo* mapinfo = FileMapInfo::current_info();
int lr = CompactingPermGenGen::n_regions - 1;
size_t capacity = align_size_up(mapinfo->space_capacity(lr), alignment);
heap_address = mapinfo->region_base(lr) + capacity;
// Calculate the address of the first word of the heap.
heap_address -= total_reserved;
} else {
heap_address = NULL; // any address will do.
if (UseCompressedOops) {
heap_address = Universe::preferred_heap_base(total_reserved, alignment, Universe::UnscaledNarrowOop);
*_total_reserved = total_reserved;
*_n_covered_regions = n_covered_regions;
*heap_rs = ReservedHeapSpace(total_reserved, alignment,
UseLargePages, heap_address);
if (heap_address != NULL && !heap_rs->is_reserved()) {
// Failed to reserve at specified address - the requested memory
// region is taken already, for example, by 'java' launcher.
// Try again to reserver heap higher.
heap_address = Universe::preferred_heap_base(total_reserved, alignment, Universe::ZeroBasedNarrowOop);
*heap_rs = ReservedHeapSpace(total_reserved, alignment,
UseLargePages, heap_address);
if (heap_address != NULL && !heap_rs->is_reserved()) {
// Failed to reserve at specified address again - give up.
heap_address = Universe::preferred_heap_base(total_reserved, alignment, Universe::HeapBasedNarrowOop);
assert(heap_address == NULL, "");
*heap_rs = ReservedHeapSpace(total_reserved, alignment,
UseLargePages, heap_address);
}
}
return heap_address;
}
}
*_total_reserved = total_reserved;
*_n_covered_regions = n_covered_regions;
*heap_rs = ReservedHeapSpace(total_reserved, alignment,
UseLargePages, heap_address);
return heap_address;
}
该方法的大致执行流程如下,有点长:
- 确定当前的页大小。
- 根据新生代、老生代和永久代的各个GenerationSpec,将它们的最大内存大小累加到total_reserved变量,作为申请内存的总量。
- 同时将GenerationSpec中的n_covered_regions一同累加,该字段代表申请内存区域的数量,新生代、老生代都为1,永久代为2。
- 如果配置为大页模式,将申请内存的量向上对齐到页大小。
- 若启用了压缩普通对象指针(
-XX:+UseCompressedOops),调用Universe::preferred_heap_base()方法,以32位直接压缩的方式(UnscaledNarrowOop)取得堆的基地址,并调用ReservedHeapSpace的构造方法,申请内存。 - 如果上一步申请失败,说明比4GB大,就以零基地址压缩的方式(ZeroBasedNarrowOop)在更高的地址空间上取得堆的基地址并申请内存。
- 如果仍然申请失败,说明比32GB还大,就只能用普通的指针压缩方式(HeapBasedNarrowOop)取得堆的基地址并申请内存。
- 如果没有启用压缩普通对象指针,就直接用ReservedHeapSpace申请内存。最终都返回起始地址。
那么真正分配内存的逻辑在哪里呢?它位于ReservedHeapSpace的父类——ReservedSpace的initialize()方法中,为了节省篇幅,只看最核心的一段。
void ReservedSpace::initialize(size_t size, size_t alignment, bool large,
char* requested_address,
const size_t noaccess_prefix,
bool executable) {
// ...
if (base == NULL) {
// Optimistically assume that the OSes returns an aligned base pointer.
// When reserving a large address range, most OSes seem to align to at
// least 64K.
// If the memory was requested at a particular address, use
// os::attempt_reserve_memory_at() to avoid over mapping something
// important. If available space is not detected, return NULL.
if (requested_address != 0) {
base = os::attempt_reserve_memory_at(size, requested_address);
if (failed_to_reserve_as_requested(base, requested_address, size, false)) {
// OS ignored requested address. Try different address.
base = NULL;
}
} else {
base = os::reserve_memory(size, NULL, alignment);
}
if (base == NULL) return;
// Check alignment constraints
if ((((size_t)base + noaccess_prefix) & (alignment - 1)) != 0) {
// Base not aligned, retry
release_memory(base, size);
// Make sure that size is aligned
size = align_size_up(size, alignment);
base = os::reserve_memory_aligned(size, alignment);
if (requested_address != 0 &&
failed_to_reserve_as_requested(base, requested_address, size, false)) {
// As a result of the alignment constraints, the allocated base differs
// from the requested address. Return back to the caller who can
// take remedial action (like try again without a requested address).
assert(_base == NULL, "should be");
return;
}
}
}
// Done ...
可见,如果堆要在指定地址分配,亦即配置了共享空间或者指针压缩,就调用os::attempt_reserve_memory_at()申请内存,否则就调用os::reserve_memory()方法申请内存。申请成功之后仍然要对齐,方法是先检查基地址是否对齐,如果没有,就直接释放掉分配的空间,将内存大小向上对齐之后,调用os::reserve_memory_aligned()重新申请一块对齐的空间。
调整堆大小并创建GenRemSet
_reserved = MemRegion((HeapWord*)heap_rs.base(),
(HeapWord*)(heap_rs.base() + heap_rs.size()));
_reserved.set_word_size(0);
_reserved.set_start((HeapWord*)heap_rs.base());
size_t actual_heap_size = heap_rs.size() - perm_gen_spec->misc_data_size()
- perm_gen_spec->misc_code_size();
_reserved.set_end((HeapWord*)(heap_rs.base() + actual_heap_size));
_rem_set = collector_policy()->create_rem_set(_reserved, n_covered_regions);
set_barrier_set(rem_set()->bs());
可见,这段代码首先将堆空间封装成一个MemRegion对象,然后将前面的堆大小减去永久代中Misc Code与Misc Data两个区域的大小,就是堆的实际大小。最后,调用GC策略的create_rem_set()方法生成GenRemSet的实现,对于CMS而言就是CardTableRS,即卡表。
分代初始化
for (i = 0; i < _n_gens; i++) {
ReservedSpace this_rs = heap_rs.first_part(_gen_specs[i]->max_size(),
UseSharedSpaces, UseSharedSpaces);
_gens[i] = _gen_specs[i]->init(this_rs, i, rem_set());
// tag generations in JavaHeap
MemTracker::record_virtual_memory_type((address)this_rs.base(), mtJavaHeap);
heap_rs = heap_rs.last_part(_gen_specs[i]->max_size());
}
_perm_gen = perm_gen_spec->init(heap_rs, PermSize, rem_set());
各个GenerationSpec中都有一个init()方法来初始化它对应的分代,主体是一个switch-case结构。我们只来关注一下CMS情况下的ParNew与ConcurrentMarkSweep分代实现。
Generation* GenerationSpec::init(ReservedSpace rs, int level,
GenRemSet* remset) {
switch (name()) {
case Generation::DefNew: // ...
case Generation::MarkSweepCompact: // ...
#ifndef SERIALGC
case Generation::ParNew:
return new ParNewGeneration(rs, init_size(), level);
case Generation::ASParNew: // ...
case Generation::ConcurrentMarkSweep: {
assert(UseConcMarkSweepGC, "UseConcMarkSweepGC should be set");
CardTableRS* ctrs = remset->as_CardTableRS();
if (ctrs == NULL) {
vm_exit_during_initialization("Rem set incompatibility.");
}
// Otherwise
// The constructor creates the CMSCollector if needed,
// else registers with an existing CMSCollector
ConcurrentMarkSweepGeneration* g = NULL;
g = new ConcurrentMarkSweepGeneration(rs,
init_size(), level, ctrs, UseCMSAdaptiveFreeLists,
(FreeBlockDictionary::DictionaryChoice)CMSDictionaryChoice);
g->initialize_performance_counters();
return g;
}
case Generation::ASConcurrentMarkSweep: // ...
#endif // SERIALGC
default:
guarantee(false, "unrecognized GenerationName");
return NULL;
}
}
可见,新生代对应的是ParNewGeneration实现,老生代对应的是ConcurrentMarkSweepGeneration实现。根据GenerationSpec中记录的内存大小,就可以将之前申请的堆空间划分给各个代。整个堆空间至此就基本创建完成了。
总结
这篇写了3天,不想写总结了,晚安吧各位_(´ཀ`」 ∠)_