文章标签:深度学习 人工智能 paddlepaddle 入门 实战 教程
内容标签:Reader、Program、Scope使用基础 PaddlePaddle基础
前言
该系列文章相对于极简入门系列要更注重理解部分,同时对代码进行解读,依旧不会牵扯太复杂的数学原理部分,以入门为主。随后会补出实战视频,方便大家进一步学习深度学习。
点击进入PaddlePaddle入门专题页面,获取完整教程信息
点击进入往期PaddlePaddle文章、极简入门专题页面
PaddlePaddle官方网站:https://www.paddlepaddle.org.cn/
PaddlePaddle{官方用户交流群: 796771754},也可以在官方网站中找到。
该篇文章将带你编写一个较为标准的PaddlePaddle程序,你需要制作一个属于自己的Reader(数据读取器)。
为了防止在应该Python文件中执行多个PaddlePaddle程序时出现问题,这里将会简单介绍Program和Scope的使用。
本篇以线性回归任务为例,py_reader(异步读取数据)、xmap(多线程预处理方案)、name_scope(局部命名空间)等操作将在接下来的文章中介绍。
点击回顾上节线性回归任务
构建标准的数据读取器--Reader
如果是像上节那样,先准备好所有的数据,然后对这些已经加载到内存的数据进行处理。这些操作在其它任务中(图像分类、
目标检测等)将会占用大量计算机资源。
除此之外,一般在进行读取数据时候可能还需要打乱数据等操作,便捷的调节Batch_size也将会让你在调试时可以更加轻松。
1、定义数据读取
构建Reader还是非常简单的,下面提供一个模版来举例。
def reader():
def req_one_data():
# 数据的读取、预处理部分(如果想多进程预处理可以考虑使用xmap,但大多数场景不需要这样做)
# 单条数据返回部分 yield XXX,XXX,XXX
return req_one_data # 返回这个函数的变量名
以上节的线性回归任务为例,因为我们要构造一个y = 10x +3的数据集,喂给神经网络x让它吐出y。
def reader():
def req_one_data():
for i in range(10):
data_X = [i]
data_Y = [i * 10 + 3]
data_X = np.array(data_X).reshape(1, 1).astype("float32")
data_Y = np.array(data_Y).reshape(1, 1).astype("float32")
yield data_X, data_Y # 使用yield来返回单条数据
return req_one_data # 返回 req_one_data 这个变量名!可不是req_one_data()
这里我们构造出单挑数据data_X、data_Y之后,因为需要使用yield返回的是numpy的array对象,所以提前使用np.array使单条数据变成array对象。
为什么要对array对象使用.reshape(1, 1)呢?不是一维数组吗?怎么要设定两个维度?
因为我们在定义张量的时候默认会在shape的第一维加入-1来表示Batch_size的大小
定义时是x = fluid.layers.data(name="x", shape=[1], dtype="float32")
实际上是x = fluid.layers.data(name="x", shape=[-1,1], dtype="float32")
但我们在使用yield返回array对象时,并不会默认增加应该维度表示Batch_size,所以我们需要手动添加这个维度,因此我们需要np.array(XXX).reshape(1, 1)
2、定义数据传输格式
在我们定义好Reader的读取后,我们还可以对Batch进行一些操作,比方说设置Batch_size、动态打乱数据集。
train_reader = paddle.batch(reader=reader(), batch_size=10)
注意 reader=reader(),这个reader()是刚刚定义的那个数据读取函数,而且是带()的,可不是变量名!
如果想对数据集进行动态打乱,只需要将train_reader变成下面的样子就可以了。
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader(), buf_size), batch_size=10)
这里的buf_size则是打乱的缓冲器大小。
例如设置为10,则对每10个数据进行打乱一次。
3、定义数据输入格式
还记得上节的info = exe.run(feed={"x": x_, "y": y_}...吗?使用字典来传参是不是不太美观?
试试这个!
train_feeder = fluid.DataFeeder(feed_list=[x, y], place=place, program=hi_ai_program)
feed_list里就是我们所定义张量的变量名,顺序是yield返回数据的顺序。
place是最开始定义的训练环境。
program是作用的项目名称,如果你不了解这个,可以不写。
4、修改训练部分的代码
# 开始训练
for epoch in range(100):
for data in train_reader():
info = exe.run(feed=train_feeder.feed(data),
fetch_list=[loss])
(是不是感觉有点迷?贴上完整代码!)
import paddle.fluid as fluid
import paddle
import numpy as np
# 重写Reader
def reader():
def req_one_data():
for i in range(10):
data_X = [i]
data_Y = [i * 10 + 3]
data_X = np.array(data_X).reshape(1, 1).astype("float32")
data_Y = np.array(data_Y).reshape(1, 1).astype("float32")
yield data_X, data_Y
return req_one_data
# 初始化项目环境
hi_ai_program = fluid.Program() # 空白程序
start_program = fluid.Program() # 用于初始化框架的空白程序
with fluid.program_guard(main_program=hi_ai_program, startup_program=start_program):
# 定义张量格式
x = fluid.layers.data(name="x", shape=[1], dtype="float32")
y = fluid.layers.data(name="y", shape=[1], dtype="float32")
# 定义神经网络
out = fluid.layers.fc(input=x, size=1)
# 定义损失函数
loss = fluid.layers.square_error_cost(input=out, label=y)
avg_loss = fluid.layers.mean(loss)
# 定义优化器
opt = fluid.optimizer.SGD(learning_rate=0.01)
opt.minimize(avg_loss)
# 初始化环境
place = fluid.CPUPlace() # 初始化运算环境
exe = fluid.Executor(place) # 初始化执行器
exe.run(start_program)
# 定义数据传输格式
train_reader = paddle.batch(reader=reader(), batch_size=10)
train_feeder = fluid.DataFeeder(feed_list=[x, y], place=place, program=hi_ai_program)
# 开始训练
for epoch in range(100):
for data in train_reader():
info = exe.run(program=hi_ai_program,
feed=train_feeder.feed(data),
fetch_list=[loss])
划分项目空间
有没有感觉上面代码有些陌生?
fluid.program_guard和fluid.Program()又是什么鬼?
为什么要划分项目空间?
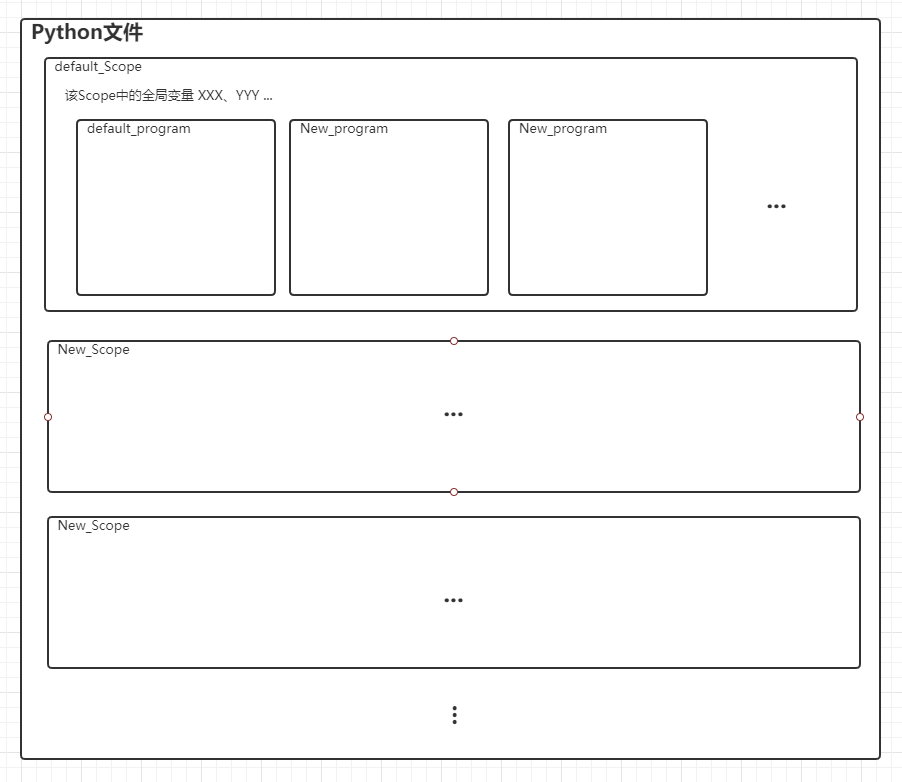
初次看这张图会比较懵逼,因为你还不了解划分这些框框能帮到你什么。
上节在数据集方面提到了训练集和交叉验证集,在训练过程中交叉验证集能评估当前训练的拟合情况,但它本身并不参与反向传播(学习)的过程。
如果你的项目中包含了反向传播,那么交叉验证集就没办法正在进行了。此时我们可以划分项目空间来确定不同数据集在哪种策略上进行。
图中的default_program就是默认的项目空间,因为是默认的,所以在你创建Python文件并导入paddle时它就已经存在了。如果不想使用这个项目空间,则要单独创建一个新空间则需要使用XXX = fluid.Program()来创建,然后使用with关键字来打开项目进行编辑
with fluid.program_guard(main_program=hi_ai_program, startup_program=start_program):
#定义张量、loss、acc等操作
main_program是需要编辑的项目,startup_program是用做初始化参数的项目,先别急,下方会有介绍。
如果你要定义交叉验证集的程序,则只需要新建一个这样的训练项目空间,将训练时定义的优化器代码删去就不会进行反向传播了。
实际上PaddlePaddle提供了更简单的方法来创建交叉验证集项目,只需要eval = train_prog.clone(for_test = True)就会生成一个没有反向传播等操作的新项目空间,并取名为你所定义的那个变量名。
但需要注意的是,如果你习惯了使用default_program,而突然因为某某特殊情况来使用新项目空间,在执行exe.run、fluid.io.save_xxx等操作时可能会漏掉program参数,例如:
fluid.io.save_inference_model(dirname="infer.model",
feeded_var_names=["x"],
target_vars=[out],
executor=exe,
main_program=hi_ai_program) # 如果是使用default_program则这一行可以忽略
那start_program又是干什么用的呢?它是用来初始化神经网络参数而准备的,它可以是一个空白的Program。
当然训练时候需要你去初始化参数,预测就不需要再初始化了,因为预测只需要你加载参数。
Scope
当你想要在一个Python中加载两个预测模型该怎么办?两个Program就可以了吗?
但实际上由于PaddlePaddle的设计,加载多个模型会替换Scope里面全局变量,可能会有冲突。
所以,为了避免冲突,可以使用Scope和with关键字来划分总体的空间,每个新Scope就像是一个新的Python文件,不必再将训练和预测分成两个Python文件来执行了~
至此,Reader、Program、Scope的简介也就大概这些内容了,如果对这些不了解也没问题,等你需要用到的时候知道有这样的用法就足够了。
当然,如果想一次性获取全部代码,可以点击下方GitHub链接,希望看到你的Star哟~
https://github.com/GT-ZhangAcer/DLExample/tree/master/easy02_Hi_AI
文章不定期更新,欢迎关注!
点击进入PaddlePaddle入门专题页面,获取完整教程信息
点击进入往期PaddlePaddle文章、极简入门专题页面