Scrapy
什么是scrapy
- Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
什么是网络爬虫
- 又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常被称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域。搜索引擎使用网络爬虫抓取Web网页、文档甚至图片、音频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索用户进行查询。网络爬虫也为中小站点的推广提供了有效的途径,网站针对搜索引擎爬虫的优化曾风靡一时.
Scrapy的安装过程
- 首先在终端中输入python,ubuntu检查是否自带了python 如果没有自带则重新安装
- 在终端输入python 然后出现以下
- 接着输入import lxml
- 然后再输入import OpenSSL
- 如果没有报错的话,说明ubuntu自带了python
依次在终端中输入以下指令
- sudo apt-get install python-dev
- sudo apt-get install libevent-dev
- sudo apt-get install python-pip
- sudo pip install Scrapy
然后输入scrapy 出现以下界面

scrapy安装完成之后,便是进行简单的抓取网页数据(对的首页进行数据抓取)
- 创建新工程:scrapy startproject XXX(例如:scrapy startproject jianshu)

- 显示文件的树状结构
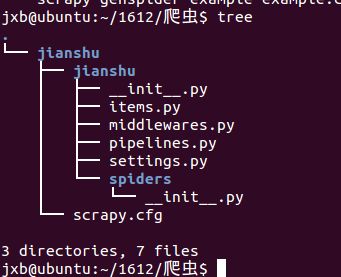
- spiders文件夹下就是要实现爬虫功能(具体如何爬取数据的代码),爬虫的核心。
- 在spiders文件夹下自己创建一个spider,用于爬取首页热门文章。
- scrapy.cfg是项目的配置文件。
- settings.py用于设置请求的参数,使用代理,爬取数据后文件保存等。
- items.py: 项目中的item文件,该文件存放的是抓取的类目,类似于dict字典规则
- pipelines.py: 项目中的pipelines文件,该文件为数据抓取后进行数据处理的方法
进行简单的的首页数据的抓取
- 在spiders文件夹下创建了文件jianshuSpider.py并且在里面输入
MicrosoftInternetExplorer4
0
2
DocumentNotSpecified
7.8 磅
Normal
0
@font-face{
font-family:"Times New Roman";
}
@font-face{
font-family:"宋体";
}
@font-face{
font-family:"Calibri";
}
@font-face{
font-family:"Courier New";
}
p.MsoNormal{
mso-style-name:正文;
mso-style-parent:"";
margin:0pt;
margin-bottom:.0001pt;
mso-pagination:none;
text-align:justify;
text-justify:inter-ideograph;
font-family:Calibri;
mso-fareast-font-family:宋体;
mso-bidi-font-family:'Times New Roman';
font-size:10.5000pt;
mso-font-kerning:1.0000pt;
}
p.MsoPlainText{
mso-style-name:纯文本;
margin:0pt;
margin-bottom:.0001pt;
mso-pagination:none;
text-align:justify;
text-justify:inter-ideograph;
font-family:宋体;
mso-hansi-font-family:'Courier New';
mso-bidi-font-family:'Times New Roman';
font-size:10.5000pt;
mso-font-kerning:1.0000pt;
}
span.msoIns{
mso-style-type:export-only;
mso-style-name:"";
text-decoration:underline;
text-underline:single;
color:blue;
}
span.msoDel{
mso-style-type:export-only;
mso-style-name:"";
text-decoration:line-through;
color:red;
}
@page{mso-page-border-surround-header:no;
mso-page-border-surround-footer:no;}@page Section0{
}
div.Section0{page:Section0;}
#coding=utf-8
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
from scrapy.http import Request
from jianshu.items import JianshuItem
import urllib
class Jianshu(CrawlSpider):
name='jianshu'
start_urls=['http://www.jianshu.com/top/monthly']
url = 'http://www.jianshu.com'
def parse(self, response):
item = JianshuItem()
selector = Selector(response)
articles = selector.xpath('//ul[@class="article-list thumbnails"]/li')
for article in articles:
title = article.xpath('div/h4/a/text()').extract()
url = article.xpath('div/h4/a/@href').extract()
author = article.xpath('div/p/a/text()').extract()
# 下载所有热门文章的缩略图, 注意有些文章没有图片
try:
image = article.xpath("a/img/@src").extract()
urllib.urlretrieve(image[0], '/Users/apple/Documents/images/%s-%s.jpg' %(author[0],title[0]))
except:
print '--no---image--'
listtop = article.xpath('div/div/a/text()').extract()
likeNum = article.xpath('div/div/span/text()').extract()
readAndComment = article.xpath('div/div[@class="list-footer"]')
data = readAndComment[0].xpath('string(.)').extract()[0]
item['title'] = title
item['url'] = 'http://www.jianshu.com/'+url[0]
item['author'] = author
item['readNum']=listtop[0]
# 有的文章是禁用了评论的
try:
item['commentNum']=listtop[1]
except:
item['commentNum']=''
item['likeNum']= likeNum
yield item
next_link = selector.xpath('//*[@id="list-container"]/div/button/@data-url').extract()
if len(next_link)==1 :
next_link = self.url+ str(next_link[0])
print "----"+next_link
yield Request(next_link,callback=self.parse)
- 在items.py中
MicrosoftInternetExplorer4
0
2
DocumentNotSpecified
7.8 磅
Normal
0
@font-face{
font-family:"Times New Roman";
}
@font-face{
font-family:"宋体";
}
@font-face{
font-family:"Calibri";
}
@font-face{
font-family:"Courier New";
}
p.MsoNormal{
mso-style-name:正文;
mso-style-parent:"";
margin:0pt;
margin-bottom:.0001pt;
mso-pagination:none;
text-align:justify;
text-justify:inter-ideograph;
font-family:Calibri;
mso-fareast-font-family:宋体;
mso-bidi-font-family:'Times New Roman';
font-size:10.5000pt;
mso-font-kerning:1.0000pt;
}
p.MsoPlainText{
mso-style-name:纯文本;
margin:0pt;
margin-bottom:.0001pt;
mso-pagination:none;
text-align:justify;
text-justify:inter-ideograph;
font-family:宋体;
mso-hansi-font-family:'Courier New';
mso-bidi-font-family:'Times New Roman';
font-size:10.5000pt;
mso-font-kerning:1.0000pt;
}
span.msoIns{
mso-style-type:export-only;
mso-style-name:"";
text-decoration:underline;
text-underline:single;
color:blue;
}
span.msoDel{
mso-style-type:export-only;
mso-style-name:"";
text-decoration:line-through;
color:red;
}
@page{mso-page-border-surround-header:no;
mso-page-border-surround-footer:no;}@page Section0{
}
div.Section0{page:Section0;}
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
from scrapy.item import Item,Field
class JianshuItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = Field()
author = Field()
url = Field()
readNum = Field()
commentNum = Field()
likeNum = Field()
- 在setting.py中
···
MicrosoftInternetExplorer4
0
2
DocumentNotSpecified
7.8 磅
Normal
0
@font-face{
font-family:"Times New Roman";
}
@font-face{
font-family:"宋体";
}
@font-face{
font-family:"Calibri";
}
@font-face{
font-family:"Courier New";
}
p.MsoNormal{
mso-style-name:正文;
mso-style-parent:"";
margin:0pt;
margin-bottom:.0001pt;
mso-pagination:none;
text-align:justify;
text-justify:inter-ideograph;
font-family:Calibri;
mso-fareast-font-family:宋体;
mso-bidi-font-family:'Times New Roman';
font-size:10.5000pt;
mso-font-kerning:1.0000pt;
}
p.MsoPlainText{
mso-style-name:纯文本;
margin:0pt;
margin-bottom:.0001pt;
mso-pagination:none;
text-align:justify;
text-justify:inter-ideograph;
font-family:宋体;
mso-hansi-font-family:'Courier New';
mso-bidi-font-family:'Times New Roman';
font-size:10.5000pt;
mso-font-kerning:1.0000pt;
}
span.msoIns{
mso-style-type:export-only;
mso-style-name:"";
text-decoration:underline;
text-underline:single;
color:blue;
}
span.msoDel{
mso-style-type:export-only;
mso-style-name:"";
text-decoration:line-through;
color:red;
}
@page{mso-page-border-surround-header:no;
mso-page-border-surround-footer:no;}@page Section0{
}
div.Section0{page:Section0;}
-- coding: utf-8 --
Scrapy settings for jianshu project
For simplicity, this file contains only settings considered important or
commonly used. You can find more settings consulting the documentation:
http://doc.scrapy.org/en/latest/topics/settings.html
http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'jianshu'
SPIDER_MODULES = ['jianshu.spiders']
NEWSPIDER_MODULE = 'jianshu.spiders'
Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'jianshu (+http://www.yourdomain.com)'
Obey robots.txt rules
ROBOTSTXT_OBEY = True
Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
Configure a delay for requests for the same website (default: 0)
See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
The download delay setting will honor only one of:
CONCURRENT_REQUESTS_PER_DOMAIN = 16
CONCURRENT_REQUESTS_PER_IP = 16
Disable cookies (enabled by default)
COOKIES_ENABLED = False
Disable Telnet Console (enabled by default)
TELNETCONSOLE_ENABLED = False
Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,/;q=0.8',
'Accept-Language': 'en',
}
Enable or disable spider middlewares
See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'jianshu.middlewares.MyCustomSpiderMiddleware': 543,
}
Enable or disable downloader middlewares
See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'jianshu.middlewares.MyCustomDownloaderMiddleware': 543,
}
Enable or disable extensions
See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
EXTENSIONS = {
'scrapy.extensions.telnet.TelnetConsole': None,
}
Configure item pipelines
See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jianshu.pipelines.SomePipeline': 300,
}
Enable and configure the AutoThrottle extension (disabled by default)
See http://doc.scrapy.org/en/latest/topics/autothrottle.html
AUTOTHROTTLE_ENABLED = True
The initial download delay
AUTOTHROTTLE_START_DELAY = 5
The maximum download delay to be set in case of high latencies
AUTOTHROTTLE_MAX_DELAY = 60
The average number of requests Scrapy should be sending in parallel to
each remote server
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
Enable showing throttling stats for every response received:
AUTOTHROTTLE_DEBUG = False
Enable and configure HTTP caching (disabled by default)
See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_IGNORE_HTTP_CODES = []
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
FEED_URI=u'/Users/apple/Documents/jianshu-monthly.csv'
FEED_FORMAT='CSV'
···
- 运行结果还有点问题,CSV保存文件字节数为0