7.1 基本原理
上一章提到的MemTable是内存表,当内存表增长到一定程度时(memtable.size> Options::write_buffer_size),Compact动作会将当前的MemTable数据持久化,持久化的文件称之为SSTable(Sorted String Table)。
LevelDB中的SSTable分为不同的层级,这也是LevelDB称之为Level DB的原因,当前版本的最大层级为7(0-6),level-0的数据最新,level-6的数据最旧。除此之外,Compact动作会将多个SSTable合并成少量的几个SSTable,以剔除无效数据,保证数据访问效率并降低磁盘占用。
7.2 物理布局
在存储设备上,一个SSTable被划分为多个Block数据块。每个Block中存储的可能是用户数据、索引数据或任何其他数据。Block除了数据块外,每个Block尾部还带了额外信息,布局如下:

- Compression Type标识Block中的数据是否被压缩,采用了何种压缩算法。
- CRC则是Block的数字签名,用于校验数据的有效性。
Block是SSTable物理布局的关键。来看Block结构:
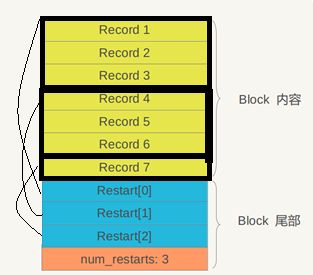
Block内部由以下两部分组成:
- 数据记录:每一个Record代表了一条用户记录(Key-Value对)。严格上讲,并不是完整的用户记录,LevelDB在Key上Block做了优化。
- 重启点信息:亦即索引信息,用于Record快速定位。如Restart[0]永远指向block的相对偏移0,Restart[1]指向重启点Record4的相对偏移。LevelDB在Key存储上做了优化,每个重启点指向的第一条Record记录了完整的Key值,而本重启点之内的其他key仅包含和前一条的差异项。
通过Block的构建过程进一步了解上述结构:
void BlockBuilder::Add(const Slice &key, const Slice &value)
{
Slice last_key_piece(last_key_);
assert(!finished_);
assert(counter_ <= options_->block_restart_interval);
assert(buffer_.empty() // No values yet?
|| options_->comparator->Compare(key, last_key_piece) > 0);
//1. 构建Restart Point
size_t shared = 0;
//每block_restart_interval条记录创建一个重启点
if (counter_ < options_->block_restart_interval) //配置参数,默认为16
{
//尚未达到重启点间隔,沿用当前的重启点
// See how much sharing to do with previous string
const size_t min_length = std::min(last_key_piece.size(), key.size());
while ((shared < min_length) && (last_key_piece[shared] == key[shared]))
{
shared++;
}
}
else
{
//触发并创建新的重启点
//此时,shared = 0; 重启点中将保存完整key
// Restart compression
restarts_.push_back(buffer_.size()); //buffer_.size()为当前数据块偏移
counter_ = 0;
}
const size_t non_shared = key.size() - shared;
//2. 记录数据
// shared size | no shared size | value size | no shared key data | value data
// Add "" to buffer_
PutVarint32(&buffer_, shared);
PutVarint32(&buffer_, non_shared);
PutVarint32(&buffer_, value.size());
// Add string delta to buffer_ followed by value
buffer_.append(key.data() + shared, non_shared);
buffer_.append(value.data(), value.size());
// Update state
last_key_.resize(shared);
last_key_.append(key.data() + shared, non_shared);
assert(Slice(last_key_) == key);
counter_++;
}
Buffer_代表当前数据块,restart_中则包含了重启点信息。当向block中新增一条记录时,首先设置重启点信息,包括:是否创建新的重启点,当前key和last key中公共部分大小。重启点信息整理完毕后,插入Record信息,Record信息的结构如下:
Record: shared size | no shared size | value size | no shared key data | value data
再来看Block构建完成时调用的Finish方法:
Slice BlockBuilder::Finish() {
// Append restart array
for (size_t i = 0; i < restarts_.size(); i++) {
PutFixed32(&buffer_, restarts_[i]);
}
PutFixed32(&buffer_, restarts_.size());
finished_ = true;
return Slice(buffer_);
}
此处和图3.1一致,在所有Record之后记录重启点信息,包括每条重启点信息(block中相对偏移)及重启点数量。
重启点机制主要有两点好处:
- 索引信息:用于快速定位,读取时通过重启点的二分查找先获取查找数据所属的重启点,随后在重启点内部遍历,时间复杂度为Log(n)。
- 空间压缩:有序key值使得相邻记录的key值的重叠度极高,通过上述方式可以有效降低持久化设备占用。
至此,SSTable的物理布局已然清晰。
7.3 逻辑布局
刚刚看过Block的结构,SSTable所有的数据存储都是以Block为基本单元进行的。现在来看SSTable的逻辑布局,这次我们先从实现说起:
void TableBuilder::Add(const Slice &key, const Slice &value)
{
Rep *r = rep_;
assert(!r->closed);
if (!ok())
return;
if (r->num_entries > 0)
{
assert(r->options.comparator->Compare(key, Slice(r->last_key)) > 0);
}
//1. 构建Index
if (r->pending_index_entry)
{
assert(r->data_block.empty());
r->options.comparator->FindShortestSeparator(&r->last_key, key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
//2. 构建过滤器
if (r->filter_block != NULL)
{
r->filter_block->AddKey(key);
}
//3. 记录数据
r->last_key.assign(key.data(), key.size());
r->num_entries++;
r->data_block.Add(key, value);
//4. 数据块(Data Block)大小已达上限,写入文件
const size_t estimated_block_size = r->data_block.CurrentSizeEstimate();
if (estimated_block_size >= r->options.block_size)
{
Flush();
}
}
BlockBuilder 用于构建Block,TableBuidler则用于构建Table。Table构建过程中包含如下部分:
- 构建Index。Block中采用了重启点机制实现索引功能,在保证性能的同时又降低了磁盘占用。那么此处为何没有采用类似的机制呢?
实际上,此处索引键值的存储也做了优化,具体实现在FindShortestSeparator中,其目的在于获取最短的可以做为索引的“key”值。
举例来说,“helloworld”和”hellozoomer”之间最短的key值可以是”hellox”。
除此之外,另一个FindShortSuccessor方法则更极端,用于找到比指定key值大的最小key,如传入“helloworld”,返回的key值可能是“i”而已。作者专门为此抽象了两个接口,放置于Compactor中,可见其对编码也是是有“洁癖”的。
- 构建过滤器。在LevelDB的早期版本是没有过滤器的,1.2中引入过滤器,并默认提供布隆过滤器。过滤器的目的同样在于在于快速定位,LevelDB中,每2k大小构造一个过滤器。
// Generate new filter every 2KB of data
static const size_t kFilterBaseLg = 11;
static const size_t kFilterBase = 1 << kFilterBaseLg;
- 记录数据。通过block builder将key-value数据插入到data block中。
- 数据块刷新。当数据块(Data Block)大小已达上限时,写入文件。
除了data block写入文件,其他构建块均存储于内存中,此时并未真正持久化。真正持久化动作在Finish中:
Status TableBuilder::Finish()
{
//1. Data Block
Rep *r = rep_;
Flush();
assert(!r->closed);
r->closed = true;
BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle;
//2. Write filter block
if (ok() && r->filter_block != NULL)
{
WriteRawBlock(r->filter_block->Finish(), kNoCompression,
&filter_block_handle);
}
//3. Write metaindex block
if (ok())
{
BlockBuilder meta_index_block(&r->options);
if (r->filter_block != NULL)
{
// Add mapping from "filter.Name" to location of filter data
std::string key = "filter.";
key.append(r->options.filter_policy->Name());
std::string handle_encoding;
filter_block_handle.EncodeTo(&handle_encoding);
meta_index_block.Add(key, handle_encoding);
}
// TODO(postrelease): Add stats and other meta blocks
WriteBlock(&meta_index_block, &metaindex_block_handle);
}
//4. Write index block
if (ok())
{
if (r->pending_index_entry)
{
r->options.comparator->FindShortSuccessor(&r->last_key);
std::string handle_encoding;
r->pending_handle.EncodeTo(&handle_encoding);
r->index_block.Add(r->last_key, Slice(handle_encoding));
r->pending_index_entry = false;
}
WriteBlock(&r->index_block, &index_block_handle);
}
//5. Write footer
if (ok())
{
Footer footer;
footer.set_metaindex_handle(metaindex_block_handle);
footer.set_index_handle(index_block_handle);
std::string footer_encoding;
footer.EncodeTo(&footer_encoding);
r->status = r->file->Append(footer_encoding);
if (r->status.ok())
{
r->offset += footer_encoding.size();
}
}
return r->status;
}
通过Finish方法,我们可以一窥SSTable的全貌:

- Data Block:数据块,用户数据存放于此。
- Filter Blck:过滤器数据块。
- Meta Block:元数据块,当前存放过滤器数据。
- Index Block:索引块,用于用户数据快速定位。
- Footer:SSTable的注脚区,见下图。
- Meta Index Block Handle指出了Meta Index Block的起始位置和大小。
- Index Block Handle指出了Index Block的起始地址和大小。
-
上述两个字段可以理解为索引的索引,是为了正确读出索引值而设立的,后面跟着一个填充区和魔数。
 SSTable Footer
SSTable Footer
本节最后,总结如下:
- SSTable一旦创建后,将只存在查询行为,在键值查找或SSTable遍历时,必定从重启点开始查找,因此除重启点位置的Record为完整key外,其他均为差异项亦可快速定位。
- Table、Block一旦创建后无法修改,TableBuilder负责Table创建,BlockBuilder负责。Table、Block最重要的接口为Iterator* NewIterator(...) const,用于查找、遍历数据。LevelDB中的Iterator稍显复杂,后面会统一备忘。
- Table、Block各自采用了类似的索引机制,并形成了Table到Block的多级索引。重启点、Table的索引机制在保证性能的同时又降低了存储空间。
表3.1、图3.2中一直强调SSTable中存储的是Block,这种描述并不十分准确。表3.1中讲到,SSTable中存储了“Compression Type(是否压缩)”,如果数据被压缩,SSTable中存储的并不是Block数据本身,而是压缩后的数据,使用时则需先对Block解压。
7.4 总结
LevelDB中,所有数据最终被持久化为SSTable。LevelDB之所以称为“Level DB”是因为数据是分层的,每次被压缩的数据level提升一级。每一层的数据都比下一层更新(MemTable中的最新),各层数据均以SSTable格式存储。
转载请注明:【随安居士】http://www.jianshu.com/p/1ed0b94e8a2c