PSM第一篇链接:模型系列-PSM原理介绍
第一篇主要介绍了为什么需要匹配?匹配的思路是什么?什么是倾向值?什么是倾向值匹配?这篇中将会介绍和PSM有关的stata操作。
以下原理复习取自 许老师的计量经济学讲义,推荐公号 宏观经济学会
PSM原理复习
首先来温习下“倾向值匹配”在说些什么?
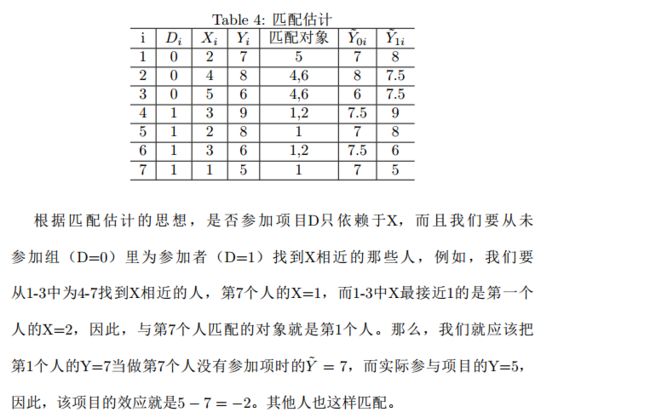
使用匹配估计量的条件:假设个体根据可观测变量来选择是否可参与项目
以一个就业培训项目为例,在对项目进行效应评估时,我们除了能观测到人们是否参与了该项目Di和项目实施前后的收入Yi,还可以观测到参与者一些个体特征,比如年龄、受教育程度、肤色、性别等等协变量。
如果个体是否参与项目完全是由某些协变量X决定的,那么我们就可以使用匹配估计方法来估计处理效应。
匹配估计的思想简单易懂:实践中,个体i参与了培训(处理组),这人就不可能再穿越回去选择不参加培训。此时,我们就需要在没有参加培训的人中(控制组)找到某个或某些人j,如何找到这些人呢?
前面说,参与项目Di完全取决于可观测变量Xi,那么自然就是找那些与参与者i有相近X的未参与人j。我们选择到的Xj与Xi越接近,j参与培训的概率就越接近i。那么,我们就可以把j的收入Yj近似当作i在没有参与培训情形下的收入,然后将i的实际收入Yi减去近似收入Yj,得到培训的处理效应,即匹配估计量。

一般来说,匹配估计量会存在偏出,因为Xi不可能和Xj完全相同。那么在非精确匹配的情形下:
- 一对一匹配,偏差较大,方差较小
- 一对多匹配,偏差较小,方差加大
经验法则:最好进行一堆四匹配,这样能使均方误差MSE最小。

PSM的思想即,将多个X转换成一个指标,即通过某种函数f(X),把多维变量变成一维变量。这个一维变量就是倾向得分。然后,我们就可以根据这个倾向得分进行上述匹配。
PSM计算处理效应的步骤
- 选择协变量X。尽量将影响D和Y的相关变量都包括在协变量中。如果协变量选择不当或太少,就会引起效应估计偏误;
- 计算倾向得分,一般用logit回归;
- 进行倾向得分匹配。如果倾向得分估计较为精确,那么,X在匹配后的处理组和控制组之间均匀分布,这就是数据平衡。那么我们检验得分是否准确就需要计算X中每个分量的“标准化偏差”。经验法则:一般来说,标准化偏差不能超过10%,如果超过10%,就需要返回第2步重新计算,甚至第1步重新选择匹配协变量,或者改变匹配方法。
- 根据匹配后的样本计算处理效应
在第三部中,得分匹配效果不好,可能要改变匹配方法
- k邻近匹配
- 卡尺匹配或半径匹配
- 卡尺内最近邻匹配
- 核匹配
- 局部线性回归匹配
- 样条匹配
在实践中,并没有明确的规则来限定使用哪种匹配方法,但有一些经验法则可以来参考:
- 如果控制个体不多,应选择又放回匹配
- 如果控制组有较多个体,应选择核匹配
最常用的方法:尝试不同的匹配方法,然后比较它们的结果,结果相似说明很稳健。结果差异较大,就要深挖其中的原因。
但PSM也有局限性:
- 大样本
- 要求处理组和控制组有较大的共同取值范围
- 只控制了可观测的变量,如果存在不可观测的协变量,就会引起“隐性偏差”
PSM实操stata命令
数据准备
*使用美国国家调查数据
webuse nlswork
*设置面板
xtset idcode year
*面板数据描述
xtdes
*生成平方项
gen age2 = age^2
gen ttl_exp2 = ttl_exp^2
gen tenure2 = tenure^2
*定义全局变量
global xlist "grade age age2 ttl_exp ttl_exp2 tenure tenure2 not_smsa south race"
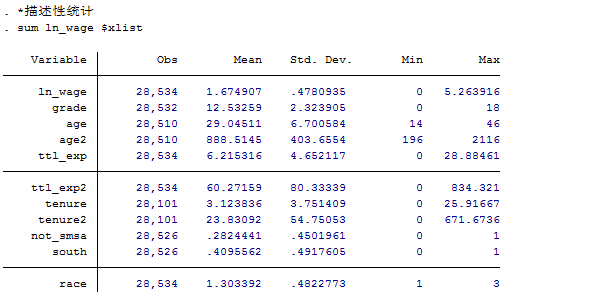
*描述性统计
sum ln_wage $xlist
*定义种子
set seed 0001
*生成随机数
gen tmp = runiform()
*将数据库随机整理
sort tmp
倾向值匹配
*设置idcode大于2000的地方执行政策
gen treated = (idcode > 2000) &! missing(idcode)
首次使用需要安装外部命令*
ssc install psmatch2,replace
*使用二值选择模型 logit 回归估计倾向值,并基于近邻匹配(默认 K=1)实现一对一匹配;
*其它匹配方法,例如半径匹配、核匹配、样条匹配等,选项格式见psmatch2 命令的帮助文档
psmatch2 treated $xlist,out(ln_wage) logit ate neighbor(1) common caliper(.05) ties
模型拟合结果,此处无太多实际意义。
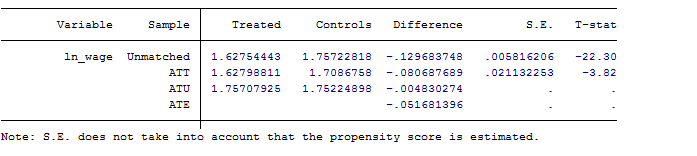
ATT估计值

试验组可匹配的观测概览,按照命令中设定的匹配规则,试验组有22组未能匹配到合适对照。
*检验协变量在处理组与控制组之间是否平衡
pstest $xlist, both graph
gen common = _support
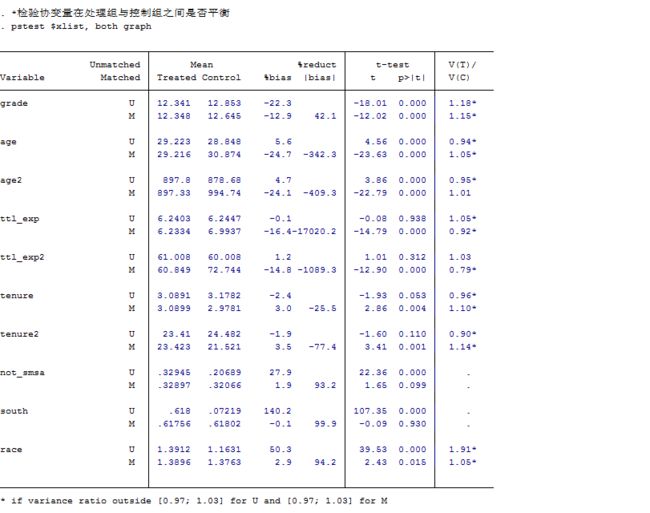
均衡性检验结果
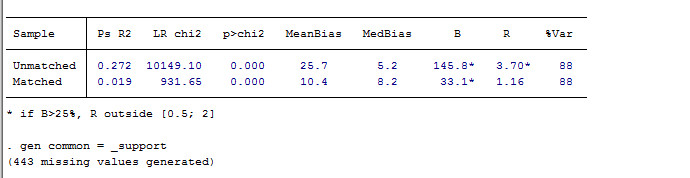
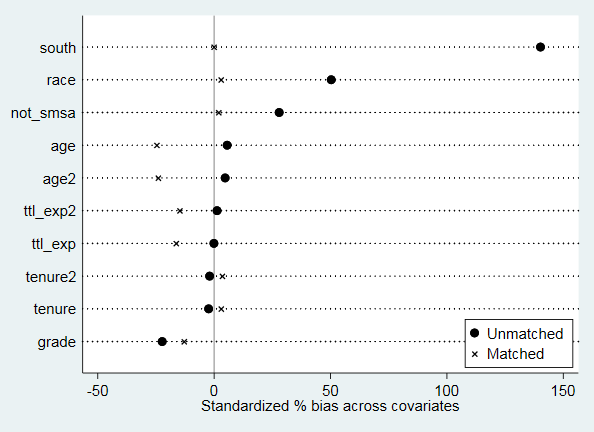
pstest, both做匹配后均衡性检验,理论上说此处只能对连续变量做均衡性检验,对分类变量的均衡性检验应该重新整理数据后运用χ2检验或者秩和检验。但此处对于分类变量也有一定的参考价值。
*去掉不满足共同区域假定的观测值
drop if common == 0
*绘图显示倾向值的共同取值范围
psgraph
psgraph对匹配的结果进行图示。
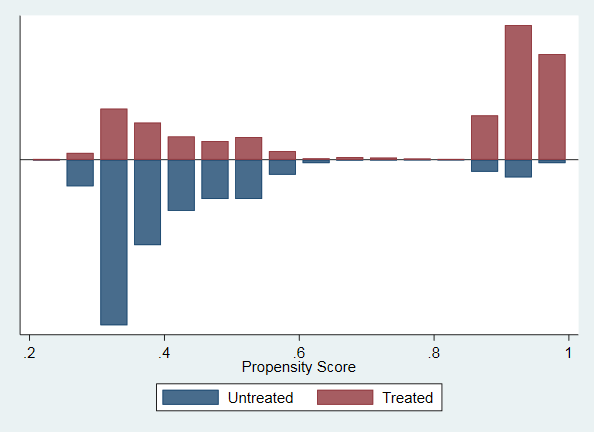
匹配结果的图示化
关于PSM语法命令
以下是帮助菜单的中psmatch2语法格式:
psmatch2 depvar [indepvars] [if exp] [in range] [, outcome(varlist) pscore(varname) neighbor(integer) radius caliper(real) mahalanobis(varlist) ai(integer) population altvariance kernel llr kerneltype(type) bwidth(real) spline nknots(integer) common trim(real) noreplacement descending odds index logit ties quietly w(matrix) ate]
简单说就是:psmatch2 因变量 协变量,[选择项]。
以文中为例:
psmatch2 treated $xlist,out(ln_wage) logit ate neighbor(1) common caliper(.05) ties
重点解读命令语句中选择项的含义。本例中选择“nearest neighbor matching within caliper”匹配方法。
- out(ln_wage)指明结局变量
- logit指定使用logit模型进行拟合,默认的是probit模型
- neighbor(1)指定按照1:1进行匹配,如果要按照1:3进行匹配,则设定为neighbor(3)
- common强制排除试验组中倾向值大于对照组最大倾向值或低于对照组最小倾向值
- caliper(.05)试验组与匹配对照所允许的最大距离为0.05
- ties强制当试验组观测有不止一个最优匹配时同时记录
- ate 求平均处理效应即求ATT估计值
参考资料:
1.PSM与政策评估(附Stata实现)阿虎定量笔记
2.应用计量经济学讲稿 许文立
3.实例演示Stata软件实现倾向性匹配得分(PSM)分析