转载请务必注明原创地址为:https://dongkelun.com/2018/05/17/sparkKafka/
前言
首先要安装好kafka,这里不做kafka安装的介绍,本文是Spark Streaming入门教程,只是简单的介绍如何利用spark 连接kafka,并消费数据,由于博主也是才学,所以其中代码以实现为主,可能并不是最好的实现方式。
1、对应依赖
根据kafka版本选择对应的依赖,我的kafka版本为0.10.1,spark版本2.2.1,然后在maven仓库找到对应的依赖。
(Kafka项目在版本0.8和0.10之间引入了新的消费者API,因此有两个独立的相应Spark Streaming软件包可用)
org.apache.spark
spark-streaming-kafka-0-10_2.11
2.2.1
我用的是sbt,对应的依赖:
"org.apache.spark" % "spark-streaming-kafka-0-10_2.11" % "2.2.1"
2、下载依赖
在命令行执行
sbt eclipse
(我用的是eclipse sbt,具体可看我的其他博客,具体命令根据自己的实际情况)
3、创建topic
创建测试用topic top1
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic top1
4、启动程序
下好依赖之后,根据官方文档提供的示例进行代码测试
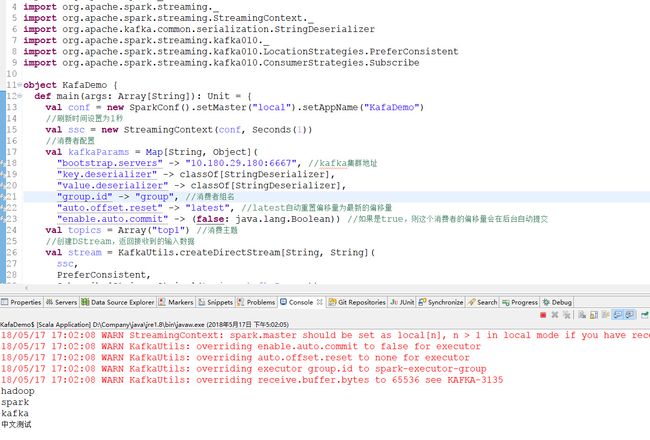
下面的代码示例,主要实现spark 连接kafka,并将接收的数据打印出来,没有实现复杂的功能。
package com.dkl.leanring.spark.kafka
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
object KafaDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("KafaDemo")
//刷新时间设置为1秒
val ssc = new StreamingContext(conf, Seconds(1))
//消费者配置
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "10.180.29.180:6667", //kafka集群地址
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "group", //消费者组名
"auto.offset.reset" -> "latest", //latest自动重置偏移量为最新的偏移量
"enable.auto.commit" -> (false: java.lang.Boolean)) //如果是true,则这个消费者的偏移量会在后台自动提交
val topics = Array("top1") //消费主题,可以同时消费多个
//创建DStream,返回接收到的输入数据
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams))
//打印获取到的数据,因为1秒刷新一次,所以数据长度大于0时才打印
stream.foreachRDD(f => {
if (f.count > 0)
f.foreach(f => println(f.value()))
})
ssc.start();
ssc.awaitTermination();
}
}
启动上面的程序(本地eclipse启动即可)
需要记住的要点
当在本地运行一个 Spark Streaming 程序的时候,不要使用 "local" 或者 "local[1]" 作为 master 的 URL 。这两种方法中的任何一个都意味着只有一个线程将用于运行本地任务。如果你正在使用一个基于接收器(receiver)的输入离散流(input DStream)(例如, sockets ,Kafka ,Flume 等),则该单独的线程将用于运行接收器(receiver),而没有留下任何的线程用于处理接收到的数据。因此,在本地运行时,总是用 "local[n]" 作为 master URL ,其中的 n > 运行接收器的数量。
将逻辑扩展到集群上去运行,分配给 Spark Streaming 应用程序的内核(core)的内核数必须大于接收器(receiver)的数量。否则系统将接收数据,但是无法处理它。
我一开始没有看到官网提醒的这一点,将示例中的local[2]改为local,现在已经在代码里改回local[2]了,但是下面的截图没有替换,注意下。
5、发送消息
运行producer
bin/kafka-console-producer.sh --broker-list localhost:6667 --topic top1
然后依次发送下面几个消息
hadoop
spark
kafka
中文测试
6、结果
然后在eclipse console就可以看到对应的数据了。
hadoop
spark
kafka
中文测试
为了直观的展示和理解,附上截图:
发送消息

结果