2018年4-5月间,笔者参加了百度举办的机器阅读理解竞赛,抱师兄大腿地从不知连机器学习的门入没入的状态到对自然语言以及阅读理解有了一定理解。期间经历了读不懂论文、不会实现算法、对师兄谈及的各种算法一无所知等等痛苦,最终坚持下来,算是有了一些收获,就在这篇文章把参加比赛的整个过程以及解题、构建模型的思路梳理一下。
我和组队的毕业师兄都是第一次参加阅读理解的比赛,但他在自然语言方面有更多了解,先前也打过kaggle之类的比赛,比赛实际上以他打为主,我以辅助和学习的形式参加。
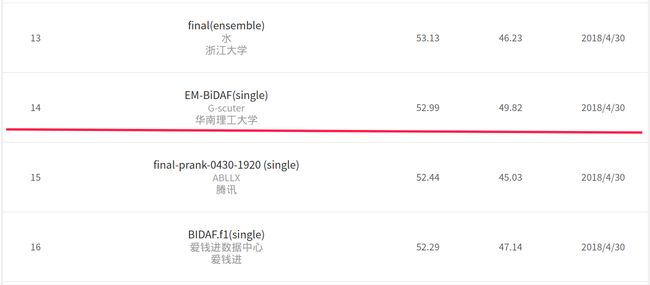
比赛最终以Rough-L第14名,BLEU第6名的结果结束,虽然有很多想法和改进没有来得及实现,但毕竟是第一次参赛,相信之后会越来越好。
Step0:了解比赛,掌握数据形式
题目背景:
官方给出解释:
对于给定问题q及其对应的文本形式的候选文档集合D=d1, d2, ..., dn,要求参评阅读理解系统自动对问题及候选文档进行分析, 输出能够满足问题的文本答案a。目标是a能够正确、完整、简洁地回答问题q。
个人详细解释:
语料库包含很多问题
对于每个问题,语料库中对应几篇文档和该问题的标准答案。
文档来自百度搜索、百度知道的结果,文档分标题和内容。文档的标题和询问的问题相似,而内容则是和问题答案相关的内容。
问题的标准答案参考给出的文档由人工提取而成。(非完全抽取式,会有些许不同)。
我们要做的就是根据给出的几篇文档,回答问题的答案,根据我们给出的答案和他们给出的标准答案的相似度进行评分。
评分机制:
Rough-L:相同最大子串(考虑顺序)
BLEU-4:预测答案和实际答案共同出现的词数(无顺序)
评分以Rough-L为主,Rough-L相同以BLEU-4排名
在对比赛形式和目标有了了解之后,下一步还要看官方给出的数据和代码,包括训练、验证、测试集数据,预处理的代码等。不过介于这是第一个比赛,经验不足,这一步笔者是在往baseline里面加代码的时候才做的,导致很大一段时间对数据细节不了解。
介于官方有给出了预处理之后的数据集,我们在这次比赛中直接使用了他们处理的数据集,没有自行对原数据集进行处理。但是后来发现预处理中间其实大有可为,对最终表现也有些影响,不过那时已经接近比赛尾声,我们只好作罢。
Step1: 阅读论文,了解state-of-art models
头两个星期的预备阶段用于看已有模型的论文和代码,因为百度提供了两个baseline系统:BIDAF和Match-LSTM,所以我们也主要看这两个baseline的论文,再参考先前排行榜中排名靠前且开源的微软r-net。通过这些已有的较为流行的模型,我对解决阅读理解的流程和阶段有了初步的认识。
阅读理解模型基本分为编码、聚合、匹配、抽取四个模块:
- 编码阶段将分好词的问题和文章分别转换成词向量,可以使用已有的词向量导入,也可以随机初始化,而后根据结果反向传播训练
- 聚合阶段仍然是分别处理文章和问题,通过如双向LSTM让每个词获得上下文的信息
- 匹配阶段则是将问题和文章进行交互,文章的每个词都和整个问题进行聚合,以此让每个词结合问题信息,由此得到已知问题的文章编码。也有模型进行双向的匹配,即获得已知文章的问题编码和已知问题的文章编码两种编码,而后再聚合。理论上这个阶段到这里就结束了,但是据r-net的文章提出,通过rnn的文章编码只能获得有限的上下文信息,而答案的抽取范围可能很长,因此在匹配之后通常会再加上一次聚合,让已知问题的文章编码获得自身较远距离的上下文信息。
- 抽取阶段则是进行答案的抽取。在M-LSTM的论文中提到两种模型:sequence model和boundary model,sequence model不考虑词语的连续性问题,将答案词语逐个逐个抽取而后拼接起来。而boundary model仅选择答案的起始和终止位置,中间的均作为答案,而实验表明boundary模型不仅简单而且效果更好,在其它的模型中也直接沿用了boundary模型。在此次比赛中,我们做的同样是答案抽取的形式。对于有些难度较大的数据集(如微软的MS-MARCRO),答案除了部分来自给定的文章外,还需要推理及自行生成,那么抽取阶段还需要做额外的工作。如s-net 中介绍的 extraction-then-synthesis framework。
Step2 模型选择与改进
挑选Baseline System:
BIDAF与MLSTM区别:
BiDAF在Interaction 层中引入了双向注意力机制
首先计算一个原文和问题的 Alignment matrix,
基于该矩阵计算 Query2Context 和 Context2Query 两种注意力,
基于注意力计算 query-aware 的原文表示,
使用双向 LSTM 进行语义信息的聚合。另外,BIDAF Embed 层中混合了词级 embedding 和字符级 embedding(在百度提供的baseline中没有),词级 embedding 使用预训练的词向量进行初始化,而字符级 embedding 使用 CNN 进一步编码,两种 embedding 共同经过 2 层 Highway Network 作为 Encode 层输入。
通过实验对比,我们最终选择了效果更好的BIDAF作为baseline。
初期想法:
师兄从知识图谱体系结构的角度提出了智能补充疑问代词的思路,鉴于给出的问题有五分之二缺少疑问词,仅仅给出名词,如“xxx的价格”,他总结出三类问题所要问题:属性、行为和状态:
1. 属性是不变或变得很缓慢的知识,如姓名、性别等
2. 行为,行为包括原因、过程、对象、时间、地点、结果,如遇到xxx怎么办
3. 状态,状态是属性和行为考虑时间维度后的产物,如天气
但bidaf的Match层是类似于相似度计算,加上疑问代词后反而降低了相似程度导致表现变差。同时,为了补充疑问代词,我们将问题拆分为有无疑问代词两类,因此训练集的规模减小,而补充代词带来的价值填补不了本身数据小还做了切分的损失,由此我们放弃了这个想法。
模型改造:
架构上:end-to-end 到 非 end-to-end
一个问题,文档集中很可能会有多个答案,而它们彼此之间相互干扰,并且降低了神经网络的学习效果,而针对这种情况,我们并没有选择在一个问题对应的整个文档集的多篇文章中只抽取一个答案,而是每篇文章抽取一个答案,构成备选答案集,之后再从备选答案集中挑选最佳的作为我们的答案。在和其他队伍交流的过程中,我们注意到他们截取的答案常常出现不完整的情况,而我们采用这种架构抽取的答案则几乎不会出现。
对于单篇文章内答案的抽取:在一篇文章内同样可能会有多个地方可能作为答案,在使用boundary模型预测始末位置时,一旦这篇文章模型认为的最优答案和文章内其它答案的区分度不高(概率差没达到我们设定的阙值),那么我们就放弃在这篇文章中抽取答案。
由此,模型不再是end-to-end了,它的主要功能就是抽取备选答案集,而我们通过对比我们选出的答案和标准答案,据此更新参数,训练模型从单篇文章抽取答案的能力。
实现上
在实现方面,我们做了两点变化:
问题编码作为上文流入文章编码
第一点变化就是在编码层将问题编码作为文章上文流入文章编码。在百度知道中,大多数时候人们的回答不会正式到将问题也加入到答案里,但是问题的一部分也应该包含在答案里,如:
Q:中国第一个乒乓球大满贯是谁?
A1:刘国梁。
A2:中国第一个乒乓球大满贯是刘国梁。
A3:中国第一个乒乓球大满贯。
人们通常只会回答A1这样的答案,虽然最正式的答案是A2。而把问题作为上文流入文章编码,则相当于自动将A1变成A2,很大程度上强化了文章对问题的匹配程度。
加入self-matching层
如同r-net和上文中提到的,理论上聚合层已经聚合了足够的上下文信息,但实际上它只能获取有限的上下文,由此我们加入了r-net中的核心:self-matching层,用来在文章和问题匹配之后,强化文章内部的信息交互。而这里,也是我首次参与到代码实现的部分。
虽然笔者之前接触过tensorflow,但都是照着文档,照着书打代码,到了实际实现论文的算法时可就懵了,但是想来这么优秀的模型应当会有人去把它实现了吧,为了达到更好的效果同时也尽量减少重复造轮子,于是笔者在github上找到了几个基于tensorflow实现的r-net,在照着论文把他们的代码啃完之后,花了些功夫把其中的self-matching层结合进了我们的模型了,然而却始终在reshape的调用上出错,查找了各种解决方案后无果。
考虑到维度的升降问题是无法避免的,开源的使用reshape无法正常运行,而baseline能够正常运行,它们的实现区别在哪里呢?想到这点,笔者又返回去看baseline的代码并将它和开源代码对比起来看,由此发现了区别:开源代码中使用tf.variable显式定义了各种需要训练的参数,而在baseline中使用了layer的fully_connected让tensorflow自行根据输入的size设置参数的shape,而后自行完成乘、加的运算,就无需调用reshape函数手动调整维度,更不会遇到维度无法整除的问题了。
随后,笔者照着baseline实现BIDAF那样,根据r-net中self-matching的公式将self-matching实现了出来。不得不承认,哪怕把r-net的论文看了好几遍,但在实现的时候才发现,自己还有好多的细节并没有掌握,文章中可能只是在公式下面短短的一句话,却是指向上一阶段一系列公式的"指针",而忽略了这句话就会使得变量对应不上。
虽然这一系列过程很累也很恼人,但看到代码最终成功运行并在服务器上跑起来,成就感还是相当足的。遗憾的是,这一层的加入对于模型的表现没有太大的提升。
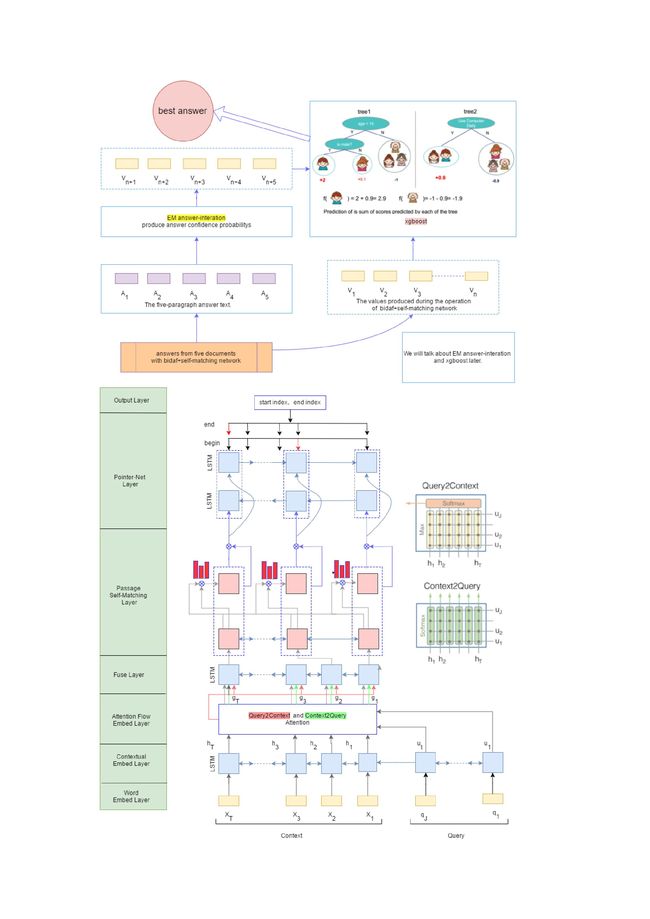
答案抽取1: EM算法
起初,我们使用EM算法,通过让备选答案集彼此交互信息,选出共性最大的答案作为最佳答案,但发现效果并不好,并且没有考虑到很多特征,由此仅作为一个额外的特征导入xgboost中。
EM算法作为无监督算法,目的在于在没有标签的情况下,让备选答案集彼此间投票。基本思想是:首先将设置所有答案的可信度都一样,出现在越多答案中的词可信度越高(通过引入信息熵降低常用词的价值),而这些词会反过来增加某些答案的可信度,答案的可信度调整之后,在可信度高的答案的词语可信度增加,由此双方不断加强,最终选出最佳答案。
这个算法在备选答案越多的情况下表现会越好,此次我们的备选答案最多有五个,虽然取得了不错的效果但还需要更好的表现。此外,最佳答案通过这个算法选取仅考虑了答案之间的交互,省略了很多特征,如答案和问题的匹配程度、答案长度、和问题的编辑距离等等。
考虑到这是在五个答案中选择一个最佳答案,把这视作一个五分类问题,起初笔者对视作五分类问题有疑惑,因为笔者认为答案和标号之间没有联系,可以随意更换。但实际上,数据的来源是百度搜索和百度知道,搜索引擎通常会将最匹配问题的结果放在第一位,同样的,备选答案之间也有顺序,直接将第一个答案作为选出答案的分数比起随机选择或者把最后一个作为答案的分数高得多。
在对主流模型进行实验挑选过后,我们最终选定了在kaggle中大放异彩,速度和准确率均高的xgboost。
答案抽取2:Xgboost
要使用xgboost训练首先得构造训练数据
答案的标签生成方面,我们通过对比五个答案和标准答案的rough-l值高低,选出最高分答案的索引作为标签。
特征选择方面,除了先前提到的em分数、答案长度、问题长度、答案和问题的编辑距离外,我们还将神经网络中经过各个层之后答案编码向量同样作为特征。
有了特征有了训练数据,接下来就是调参了。而这对于模型最终的分数也有相当大的影响。
以下就是我们的成品模型了:
Step3 调参
改造好模型之后,参数调整这里同样大有可为,而因为服务器性能有限,训练前面的神经网络一次就需要四天的时间,因此我们将重心放在了xgboost的参数调整上。
此时到了比赛结束前两天,我也将几乎所有的时间集中到了这里。先前在实现了self-matching之后,笔者花了一段时间了解了决策树、随机森林,从基本思想到公式推导,而后再了解xgboost这个相当优秀的实现,着实拓宽了眼界。
在翻阅了各种xgboost调参的教程后,对参数调整的顺序和大致范围有了基本的了解,为了不陷入手动调参的"悲惨境地",考虑到我们既然是学计算机、学软件的,那大部分事情应当自动化让计算机完成,于是搜索并发现了gridCV这一神函数,通过自动排列组合我们选定的参数,调用xgboost并返回分数和参数组合排名,我们只需要大致选定参数范围,而后交给它去排列组合并返回结果,不过限于服务器性能,我们还是需要谨慎考虑选用的训练集规模、各种参数的间隔、排列组合的个数等等因素,着实耗费了不少精力,不过也显著将得分提了2-3个点。
未来改进点与赛后感想
改进:
- 用预先训练好的词向量代替随机初始化词向量进行训练
- 不用xgboost抽取答案,改用更适合该模型的神经网络:xgboost使用的是答案抽取过程的伴生向量,还是没有办法很好的代表问题和答案之间的特征,而采用神经网络重新对候选答案集进行编码、匹配、融合、解码会提高表现。
- 单篇文章抽取答案前先通过self-match交互其他文章信息(需要试试使用词级、句子级、段落级还是文章级别的向量进行交互)
- 加强数据预处理,清洗噪音消息和html标签
- 有无疑问代词的优化
- EM算法嵌入同义词典:当前的EM算法使用的是词语是否相等的完全匹配,而加了同义词典之后,不同句子内的同义词彼此之间也能提升可信度。
- 使用dropout:让模型按照一定概率把神经网络单元暂时从网络中丢弃,不仅提高训练速度而且提高泛化能力
- 字符级别词嵌入:为模型提供更多特征
- 随机丢弃词:来自中大苏剑林苏神的建议,直接随机去掉文章或问题的词或者将词向量置为0。不使用dropout,因为dropout使用了缩放会影响到词向量。
- pointer-net开始和终止概率的调整:使用加减乘除、平方等等对概率的计算进行调整,同样是来自苏神的建议,不过限于时间、机器性能和经验原因,这次比赛没来得及使用上。
感想
首次参加机器学习方面的比赛,虽然不对名次什么的抱有太大期望,不过在报名的八百多支队伍,一百多份提交中排名14还是着实令人开心的(虽然大部分都是师兄的功劳)。
这次比赛给我带来最大的收获就是眼界的拓宽,而且让我对自然语言处理中阅读理解这个领域有了基本的了解,对于之后的学习也是相当有帮助的,之前再怎么学,也不过是照着书、照着教程打,没有实际应用,因此也没有真正掌握这些知识的实感。在参赛的过程中,从了解目标、了解模型、了解数据再到实地修改代码、改造模型、调整参数,当这么一个完整的流程走下来之后,感觉成长了不少呢。
非常感谢极天信息给我这样一个机会,以小白的状态参加到比赛中,也感谢容福炬师兄在比赛过程中对我的指导。
源代码
比赛中使用的神经网络部分和xgboost调参部分的代码可以在我的github仓库中看到。
欢迎关注我的公众号【AI实战派】

我的个人博客:Zedom1.top