6.1 基本原理
MemTable是内存表,在LevelDB中最新插入的数据存储于内存表中,内存表大小为可配置项(默认为4M)。当MemTable中数据大小超限时,将创建新的内存表并将原有的内存表Compact(压缩)到SSTable(磁盘)中。
MemTable* mem_; //新的内存表
MemTable* imm_; //待压缩的内存表
MemTable内部使用了前面介绍的SkipList做为数据存储,其自身封装的主要目的如下:
- 以一种业务形态出现,即业务抽象。
- LevelDB是Key-Value存储系统,而SkipList为单值存储,需执行用户数据到SkipList数据的编解码处理。
- LevelDB支持插入、删除动作,而MemTable中删除动作将转换为一次类型为Deletion的添加动作。
6.2 业务形态
MemTable做为内存表可用于存储Key-Value形式的数据、根据Key值返回Value数据,同时需支持表遍历等功能。
class MemTable {
public:
......
// Returns an estimate of the number of bytes of data in use by this
// data structure.
//
// REQUIRES: external synchronization to prevent simultaneous
// operations on the same MemTable.
size_t ApproximateMemoryUsage(); //目前内存表大小
// Return an iterator that yields the contents of the memtable.
//
// The caller must ensure that the underlying MemTable remains live
// while the returned iterator is live. The keys returned by this
// iterator are internal keys encoded by AppendInternalKey in the
// db/format.{h,cc} module.
Iterator* NewIterator(); // 内存表迭代器
// Add an entry into memtable that maps key to value at the
// specified sequence number and with the specified type.
// Typically value will be empty if type==kTypeDeletion.
void Add(SequenceNumber seq, ValueType type, const Slice& key, const Slice& value);
// If memtable contains a value for key, store it in *value and return true.
// If memtable contains a deletion for key, store a NotFound() error
// in *status and return true.
// Else, return false.
//根据key值返回正确的数据
bool Get(const LookupKey& key, std::string* value, Status* s);
private:
~MemTable(); // Private since only Unref() should be used to delete it
......
};
这即所谓的业务形态:以一种全新的,SkipList不可见的形式出现,代表了LevelDB中的一个业务模块。
6.3 KV转储
LevelDB是键值存储系统,MemTable也被封装为KV形式的接口,而SkipList是单值存储结构,因此在插入、读取数据时需完成一次编解码工作。
如何编码?来看Add方法:
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, const Slice& value)
{
// Format of an entry is concatenation of:
// key_size : varint32 of internal_key.size()
// key bytes : char[internal_key.size()]
// value_size : varint32 of value.size()
// value bytes : char[value.size()]
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + 8;
//总长度:
const size_t encoded_len =
VarintLength(internal_key_size) + internal_key_size +
VarintLength(val_size) + val_size;
char* buf = arena_.Allocate(encoded_len);
//1. Internal Key Size
char* p = EncodeVarint32(buf, internal_key_size);
//2. User Key
memcpy(p, key.data(), key_size);
p += key_size;
//3. Seq Number + Value Type
EncodeFixed64(p, (s << 8) | type);
p += 8;
//4. User Value Size
p = EncodeVarint32(p, val_size);
//5. User Value
memcpy(p, value.data(), val_size);
assert((p + val_size) - buf == encoded_len);
table_.Insert(buf);
}
参数传入的key、value是需要记录的键值对,本文称之为User Key,User Value。
而最终插入到SkipList的数据为buf,buf数据和User Key、User Value的转换关系如下:
完整的记录由以下5部分组成:
- Part1: internal key size = user key size + 8。user key size为part2大小,表明用户输入的key值大小;8字节为part 3大小,由Seq Number和Value Type组成。
- Part2:user key。用户输入的key值。
- Part3:seq number << 8 | value type。Seq Number在LevelDB中代表版本号,每一次数据更新版本号增加。Value Type代表操作类型,分为kTypeDeletion、kTypeValue两种,当数据插入时类型为kTypeValue,删除时类型为kTypeDeletion。
- Part4: user value size。用户输入的value值大小。
- Part5:user value。用户输入的value值。
解码处理和编码相反,来看:
bool MemTable::Get(const LookupKey& key, std::string* value, Status* s)
{
Slice memkey = key.memtable_key();
Table::Iterator iter(&table_);
//通过迭代器查找key值数据
iter.Seek(memkey.data());
if (iter.Valid()) {
// entry format is:
// klength varint32
// userkey char[klength - 8]
// tag uint64
// vlength varint32
// value char[vlength]
// Check that it belongs to same user key. We do not check the
// sequence number since the Seek() call above should have skipped
// all entries with overly large sequence numbers.
const char* entry = iter.key();
//1. 提取internal key size
uint32_t key_length;
const char* key_ptr = GetVarint32Ptr(entry, entry + 5, &key_length);
//2. 提取并比较user key值
if (comparator_.comparator.user_comparator()->Compare(
Slice(key_ptr, key_length - 8), key.user_key()) == 0)
{
//3. 提取Seq Number及Value Type
const uint64_t tag = DecodeFixed64(key_ptr + key_length - 8);
switch (static_cast(tag & 0xff)) {
case kTypeValue: {
//4. 提取user value size
//5. 提取user value
Slice v = GetLengthPrefixedSlice(key_ptr + key_length);
value->assign(v.data(), v.size());
return true;
}
//查找到一条已删除的记录,查找失败
case kTypeDeletion:
*s = Status::NotFound(Slice());
return true;
}
}
}
return false;
}
程序最开始获取memtable_key,通过Table::Iterator的Seek接口找到指定的数据,随后以编码的逆序提前User Value并返回。
这里有一个新的概念叫memtable_key,即memtable_key中的键值,它实际上是由表1中的Part1-Part3组成,memtable通过比较part1-part3中的内容判断键值是否相同。顺着Table的typedef看过来:
typedef SkipList Table;
比较器声明如下:
struct KeyComparator
{
const InternalKeyComparator comparator;
explicit KeyComparator(const InternalKeyComparator &c) : comparator(c) {}
int operator()(const char *a, const char *b) const;
};
SkipList通过()操作符完成键值比较:
int MemTable::KeyComparator::operator()(const char* aptr, const char* bptr)
const {
// Internal keys are encoded as length-prefixed strings.
Slice a = GetLengthPrefixedSlice(aptr);
Slice b = GetLengthPrefixedSlice(bptr);
return comparator.Compare(a, b);
}
此处提及的a、b键值即SkipList中使用的key,为表1中part1-part3部分。真正的比较由InternalKeyComparator完成:
int InternalKeyComparator::Compare(const Slice &akey, const Slice &bkey) const
{
// Order by:
// increasing user key (according to user-supplied comparator)
// decreasing sequence number
// decreasing type (though sequence# should be enough to disambiguate)
int r = user_comparator_->Compare(ExtractUserKey(akey), ExtractUserKey(bkey));
if (r == 0)
{
const uint64_t anum = DecodeFixed64(akey.data() + akey.size() - 8);
const uint64_t bnum = DecodeFixed64(bkey.data() + bkey.size() - 8);
if (anum > bnum)
{
r = -1;
}
else if (anum < bnum)
{
r = +1;
}
}
return r;
}
核心的比较分为两部分:User Key比较、Seq Number及Value Type比较。
- User Key比较由User Compactor完成,如果用户未指定比较器,系统将使用默认的按位比较器(BytewiseComparatorImpl)完成键值比较。
- Seq Number即版本号,每一次数据更新将递增该序号。当用户希望查看指定版本号的数据时,希望查看的是指定版本或之前的数据,故此处采用降序比较。
- Value Type分为kTypeDeletion、kTypeValue两种,实际上由于任意操作序号的唯一性,类型比较时非必须的。这里同时进行了类型比较也是出于性能的考虑(减少了从中分离序号、类型的工作)。
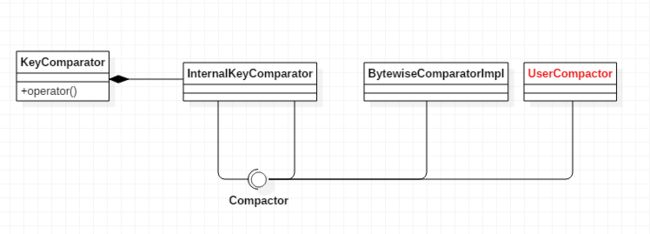
关于LevelDB的Comparator后文还会不断提到。
6.4 数据删除
客户端的删除动作将被转换为一次ValueType为Deletion的添加动作,Compact动作将执行真正的删除:
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key, const Slice& value)
ValueType定义如下:
// Value types encoded as the last component of internal keys.
// DO NOT CHANGE THESE ENUM VALUES: they are embedded in the on-disk
// data structures.
enum ValueType {
kTypeDeletion = 0x0, //Deletion必须小于Value,查找时按顺序排列
kTypeValue = 0x1
};
Get时如查找到符合条件的数据为一条删除记录,查找失败。此部分可参见前文的MemTable::Get代码。
6.5 性能优化--编码
关于MemTable的内容前面已经讲的差不多了,但不知道读者有没有注意到这几个函数:
VarintLength
EncodeVarint32
EncodeFixed64
GetVarint32Ptr
DecodeFixed64
GetLengthPrefixedSlice。
这些都是用来做数据的编解码的,这些函数均被定义在coding.h中,家族成员也不少:
// Standard Put... routines append to a string
extern void PutFixed32(std::string* dst, uint32_t value);
extern void PutFixed64(std::string* dst, uint64_t value);
extern void PutVarint32(std::string* dst, uint32_t value);
extern void PutVarint64(std::string* dst, uint64_t value);
extern void PutLengthPrefixedSlice(std::string* dst, const Slice& value);
// Standard Get... routines parse a value from the beginning of a Slice
// and advance the slice past the parsed value.
extern bool GetVarint32(Slice* input, uint32_t* value);
extern bool GetVarint64(Slice* input, uint64_t* value);
extern bool GetLengthPrefixedSlice(Slice* input, Slice* result);
// Pointer-based variants of GetVarint... These either store a value
// in *v and return a pointer just past the parsed value, or return
// NULL on error. These routines only look at bytes in the range
// [p..limit-1]
extern const char* GetVarint32Ptr(const char* p,const char* limit, uint32_t* v);
extern const char* GetVarint64Ptr(const char* p,const char* limit, uint64_t* v);
// Returns the length of the varint32 or varint64 encoding of "v"
extern int VarintLength(uint64_t v);
// Lower-level versions of Put... that write directly into a character buffer
// REQUIRES: dst has enough space for the value being written
extern void EncodeFixed32(char* dst, uint32_t value);
extern void EncodeFixed64(char* dst, uint64_t value);
// Lower-level versions of Put... that write directly into a character buffer
// and return a pointer just past the last byte written.
// REQUIRES: dst has enough space for the value being written
extern char* EncodeVarint32(char* dst, uint32_t value);
extern char* EncodeVarint64(char* dst, uint64_t value);
// Lower-level versions of Get... that read directly from a character buffer
// without any bounds checking.
inline uint32_t DecodeFixed32(const char* ptr) ...
inline uint64_t DecodeFixed64(const char* ptr) ...
// Internal routine for use by fallback path of GetVarint32Ptr
extern const char* GetVarint32PtrFallback(const char* p,
const char* limit,
uint32_t* value);
inline const char* GetVarint32Ptr(const char* p,
const char* limit,
uint32_t* value) ...
大体上可按如下两个维度划分:
- 按编解码维度划分为put、get及encode、decode。
- 按数据处理维度划分为variant(变长)、fixed(定长)。
编解码属于coding的基本职责,那么将32、64字节的数据分为变长、定长处理又是为何呢?我们知道,每增加一个维度代码的复杂度也得到了相应的增加。编码的本质不应是处理本质复杂度吗?
其实,单单从功能上讲,变长、定长确实是不需要的,之所以作者要这么做仅仅是出于性能考虑。计算机处理速度上,CPU>Memory>IO,通过CPU的计算减少对内存的访问、减少对IO的访问对性能提升是极有帮助的。
LevelDB此处的variant处理方式和protobuf类似,引用Google Protocol Buffer 的使用和原理中的文字:
Varint 是一种紧凑的表示数字的方法。它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。
从统计的角度来说,一般不会所有的消息中的数字都是大数,因此大多数情况下,采用 Varint 后,可以用更少的字节数来表示数字信息。
下面就详细介绍一下 Varint。Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010
EncodeVarint32实现如下:
char *EncodeVarint32(char *dst, uint32_t v)
{
// Operate on characters as unsigneds
unsigned char *ptr = reinterpret_cast(dst);
static const int B = 128;
if (v < (1 << 7))
{
*(ptr++) = v;
}
else if (v < (1 << 14))
{
*(ptr++) = v | B;
*(ptr++) = v >> 7;
}
else if (v < (1 << 21))
{
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = v >> 14;
}
else if (v < (1 << 28))
{
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = (v >> 14) | B;
*(ptr++) = v >> 21;
}
else
{
*(ptr++) = v | B;
*(ptr++) = (v >> 7) | B;
*(ptr++) = (v >> 14) | B;
*(ptr++) = (v >> 21) | B;
*(ptr++) = v >> 28;
}
return reinterpret_cast(ptr);
}
6.6 总结
MemTable是数据存储的内存态的一种说法,它是数据存储的源头,数据从MemTable转到Imutable MemTable再持久化到SSTable。
其中,Imutable MemTable在结构上和MemTable完全一致,只不过是从MemTable到SSTable之间的一个过渡形态而已,下文着重讲解SSTable。
转载请注明:【随安居士】http://www.jianshu.com/p/23c552bac46d