基于深度学习的单目深度估计在近几年是比较热门的研究方向之一,MIT的Diana Wofk等人在ICRA 2019上提出了一种用于嵌入式系统的深度估计算法FastDepth,在保证准确率的情况下,大大提高了模型的计算效率。
论文:FastDepth: Fast Monocular Depth Estimation on Embedded Systems
Offical Pytorch:https://github.com/dwofk/fast-depth
方法
模型
模型的整体结构比较简单,采用了Encoder-Decoder的架构。Encoder部分采用了MobileNet模型提取到7x7x1024的特征;Decoder部分采用了5次上采样,中间三次上采样结果通过Skip Connections的方法分别与Encoder部分的特征进行了特征融合,为了减小上采样部分的通道特征,还使用了5x5的卷积来降维;最后使用1*1的卷积得到深度图。
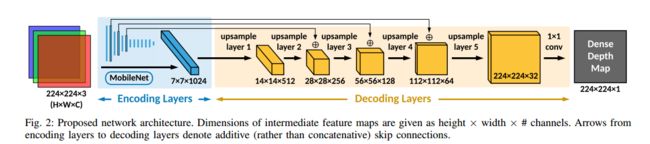
Model
使用Keras实现基本的FastDepth模型:
from keras.layers import Conv2D, UpSampling2D, SeparableConv2D, BatchNormalization, Activation, add
from keras.models import Model
from keras.applications.mobilenet import MobileNet
class FastDepth:
def __init__(self):
self.build_net()
def _SDWConv(self, filtres, kernel):
def f(x):
x = SeparableConv2D(filtres, kernel, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
return x
return f
def _encoder(self):
self.MN = MobileNet(input_shape=(224, 224, 3),
weights=None,
include_top='False')
# 7*7*1024
latent = self.MN.get_layer('conv_pw_13_relu').output
return latent
def _decoder(self, x):
# 14*14*512
x1 = self._SDWConv(512, (5, 5))(x)
x1 = UpSampling2D()(x1)
# 28*28*256
x2 = self._SDWConv(256, (5, 5))(x1)
x2 = UpSampling2D()(x2)
s2 = self.MN.get_layer('conv_pw_5_relu').output
x2 = add([x2, s2])
# 56*56*128
x3 = self._SDWConv(128, (5, 5))(x2)
x3 = UpSampling2D()(x3)
s3 = self.MN.get_layer('conv_pw_3_relu').output
x3 = add([x3, s3])
# 112*112*64
x4 = self._SDWConv(64, (5, 5))(x3)
x4 = UpSampling2D()(x4)
s4 = self.MN.get_layer('conv_pw_1_relu').output
x4 = add([x4, s4])
# 224*224*32
x5 = self._SDWConv(32, (5, 5))(x4)
x5 = UpSampling2D()(x5)
return x5
def build_net(self):
latent = self._encoder()
out = self._decoder(latent)
out_dense = Conv2D(1, (1, 1))(out)
self.model = Model(inputs=self.MN.input, outputs=out_dense)
if __name__ == '__main__':
net = FastDepth()
net.model.summary()
Decoder部分的结构如下所示:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
省略MobileNet...
__________________________________________________________________________________________________
conv_pw_13_relu (ReLU) (None, 7, 7, 1024) 0 conv_pw_13_bn[0][0]
__________________________________________________________________________________________________
separable_conv2d_3 (SeparableCo (None, 7, 7, 512) 550400 conv_pw_13_relu[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 7, 7, 512) 2048 separable_conv2d_3[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 7, 7, 512) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
up_sampling2d_3 (UpSampling2D) (None, 14, 14, 512) 0 activation_1[0][0]
__________________________________________________________________________________________________
separable_conv2d_4 (SeparableCo (None, 14, 14, 256) 144128 up_sampling2d_3[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 14, 14, 256) 1024 separable_conv2d_4[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 14, 14, 256) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
up_sampling2d_4 (UpSampling2D) (None, 28, 28, 256) 0 activation_2[0][0]
__________________________________________________________________________________________________
add_2 (Add) (None, 28, 28, 256) 0 up_sampling2d_4[0][0]
conv_pw_5_relu[0][0]
__________________________________________________________________________________________________
separable_conv2d_5 (SeparableCo (None, 28, 28, 128) 39296 add_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 28, 28, 128) 512 separable_conv2d_5[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 28, 28, 128) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
up_sampling2d_5 (UpSampling2D) (None, 56, 56, 128) 0 activation_3[0][0]
__________________________________________________________________________________________________
add_3 (Add) (None, 56, 56, 128) 0 up_sampling2d_5[0][0]
conv_pw_3_relu[0][0]
__________________________________________________________________________________________________
separable_conv2d_6 (SeparableCo (None, 56, 56, 64) 11456 add_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 56, 56, 64) 256 separable_conv2d_6[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 56, 56, 64) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
up_sampling2d_6 (UpSampling2D) (None, 112, 112, 64) 0 activation_4[0][0]
__________________________________________________________________________________________________
add_4 (Add) (None, 112, 112, 64) 0 up_sampling2d_6[0][0]
conv_pw_1_relu[0][0]
__________________________________________________________________________________________________
separable_conv2d_7 (SeparableCo (None, 112, 112, 32) 3680 add_4[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 112, 112, 32) 128 separable_conv2d_7[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 112, 112, 32) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
up_sampling2d_7 (UpSampling2D) (None, 224, 224, 32) 0 activation_5[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 224, 224, 1) 33 up_sampling2d_7[0][0]
==================================================================================================
Total params: 3,981,825
Trainable params: 3,957,953
Non-trainable params: 23,872
__________________________________________________________________________________________________
网络裁剪
为了减小模型体积,提高运算效率,使得模型更适用于嵌入式设备,使用NetAdapt算法对FastDepth进行了裁剪。
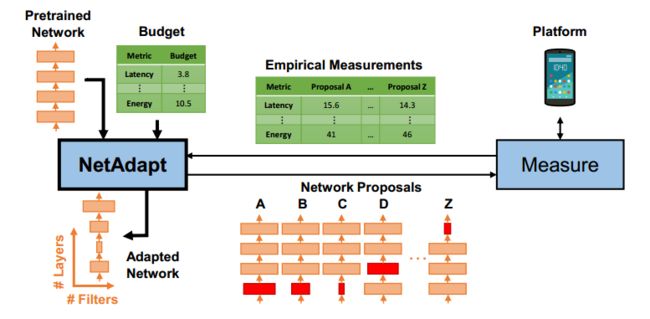
NerAdapt
实验结果
模型在NYU Depth V2 dataset上进行了训练,基本实验结果如下图所示。可以看出论文提出的FastDepth算法相较当前准确率最高的算法低了4%,但是运算速度有着大幅提升,因此特别适用于嵌入式设备。
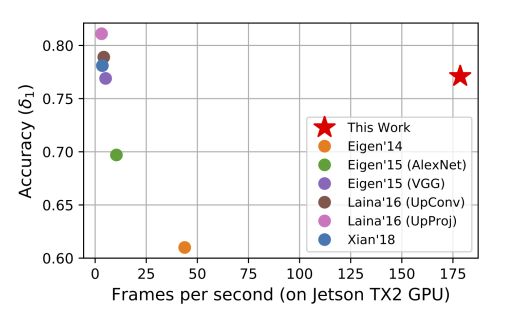
GPU
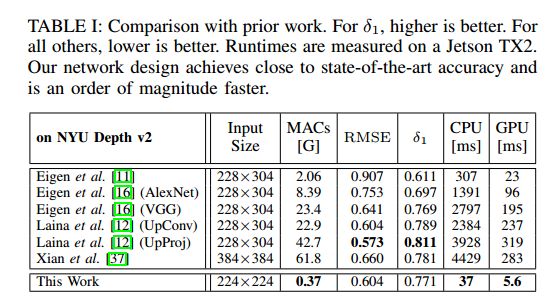
error.png
下图是深度估计的可视化效果:
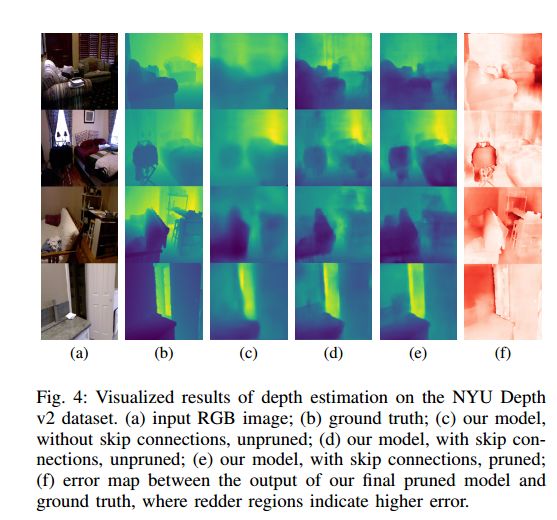
vis
下图是不同方法下Encoder和Decoder部分的运算效率和准确率,可以看出论文提出的方法运算速度非常快,而且Depthwise、Skip Connections和网络裁剪这三个技巧可以大幅提高运算效率而且对准确率的影响比较小。

speed