Github地址:https://github.com/1234560o/Bert-model-code-interpretation.git
Contents
- 前言
- 模型输入
- Padding_Mask
- attention_layer
- transformer_model
- Bert_model class
- 后续
前言
关于Bert模型的基本内容这里就不讲述了,可参考其它文章,这里有一个收集了很多讲解bert文章的网址:
http://www.52nlp.cn/bert-paper-论文-文章-代码资源汇总
与大多数文章不同的是,本文主要是对Bert模型部分的源码进行详细解读,搞清楚数据从Bert模型输入到输出的每一步变化,这对于我们理解Bert模型、特别是改造Bert是具有极大帮助的。需要注意的是,阅读本文之前,请先对Transformer、Bert有个大致的了解,本文直接讲述源码中的数据运算细节,并不会涉及一些基础内容。当然,我们还是先来回顾下Bert模型结构:
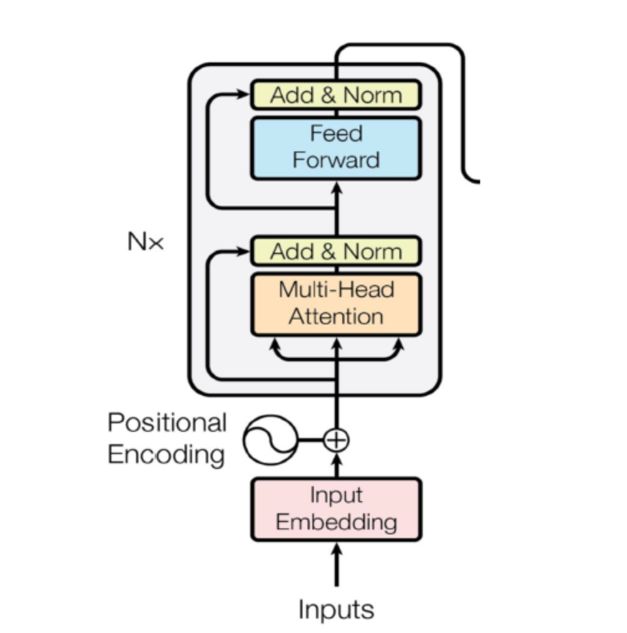
Bert模型采用的是transformer的encoder部分(见上图),不同的是输入部分Bert增加了segment_embedding且模型细节方面有些微区别。下面直接进入Bert源码解析。Bert模型部分源码地址:
https://github.com/google-research/bert/blob/master/modeling.py。
模型输入
Bert的输入有三部分:token_embedding、segment_embedding、position_embedding,它们分别指得是词的向量表示、词位于哪句话中、词的位置信息:
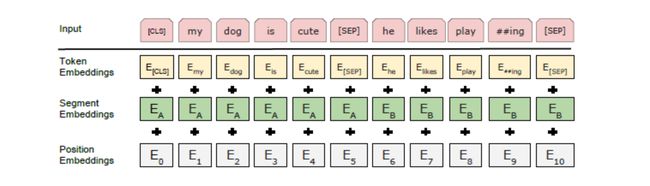
Bert输入部分由下面两个函数得到:
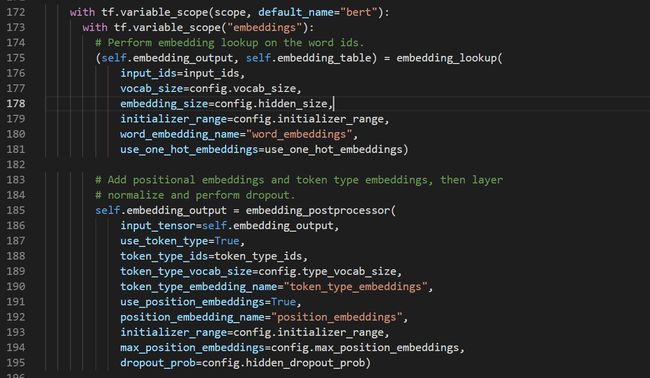
embedding_lookup得到token_embedding,embedding_postprocessor得到将这三个输入向量相加的结果,注意embedding_postprocessor函数return最后结果之前有一个layer normalize和droupout处理:

Padding_Mask
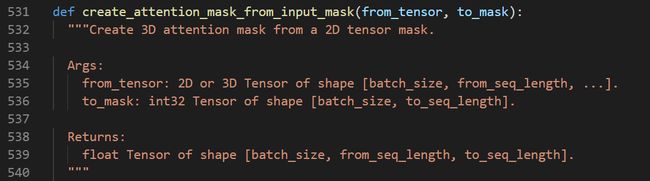
由于输入句子长度不一样,Bert作了填充处理,将填充的部分标记为0,其余标记为1,这样是为了在做attention时能将填充部分得到的attention权重很少,从而能尽可能忽略padding部分对模型的影响:

attention_layer
为了方便分析数据流,对张量的维度作如下简记:
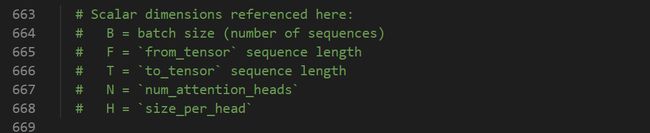
做了该简记后,经过词向量层输入Bert的张量维度为[B, F, embedding_size],attention_mask维度为[B, F, T]。由于在Bert中是self-attention,F和T是相等的。接下来我详细解读一下attention_layer函数,该函数是Bert的Multi-Head Attention,也是模型最为复杂的部分。更详细的代码可以结合源码看。在进入这部分之前,也建议先了解一下2017年谷歌提出的transformer模型,推荐Jay Alammar可视化地介绍Transformer的博客文章The Illustrated Transformer ,非常容易理解整个机制。而Bert采用的是transformer的encoding部分,attention只用到了self-attention,self-attention可以看成Q=K的特殊情况。所以attention_layer函数参数中才会有from_tensor,to_tensor这两个变量,一个代表Q,另一个代表K及V(这里的Q,K,V含义不作介绍,可参考transformer模型讲解相关文章)。
atterntion_layer函数里面首先定义了函数transpose_for_scores:
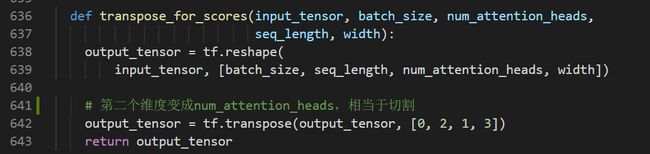
该函数的作用是将attention层的输入(Q,K,V)切割成维度为[B, N, F 或T, H]。了解transformer可以知道,Q、K、V是输入的词向量分别经过一个线性变换得到的。在做线性变换即MLP层时先将input_tensor(维度为[B, F, embedding_size])reshape成二维的(其实源码在下一个函数transformer_model中使用这个函数传进去的参数已经变成二维的了,这一点看下一个函数transformer_model可以看到):

接下来就是MLP层,即对输入的词向量input_tensor作三个不同的线性变换去得到Q、K、V,当然这一步后维度还需要转换一下才能得到最终的Q、K、V:
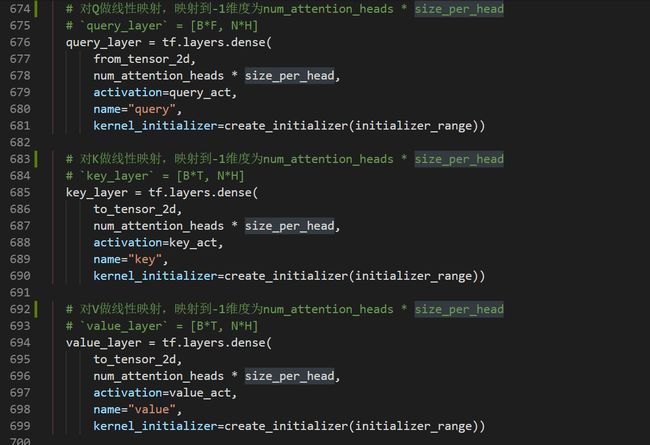
MLP层将[B * F, embedding_size]变成[B * F, N * H]。但从后面的代码(transformer_model函数)可以看到embedding_size等于hidden_size等于N * H,相当于这个MLP层没有改变维度大小,这一点也是比较难理解的:
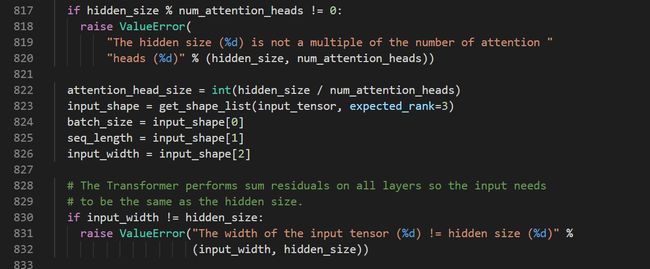
之后,代码通过先前介绍的transpose_for_scores函数得到Q、K、V,维度分别为[B, N, F, H]、[B, N, T, H]、[B, N, T, H]。不解得是,后面的求V代码并不是通过transpose_for_scores函数得到,而是又把transpose_for_scores函数体再写了一遍。
到目前为止Q、K、V我们都已经得到了,我们再来回顾一下论文“Attention is all you need”中的attention公式:
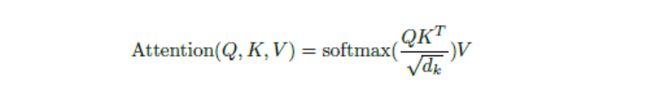
下面这部分得到的attention_scores得到的是softmax里面的部分。这里简单解释下tf.matmul。这个函数实质上是对最后两维进行普通的矩阵乘法,前面的维度都当做batch,因此这要求相乘的两个张量前面的维度是一样的,后面两个维度满足普通矩阵的乘法规则即可。细想一下attention的运算过程,这刚好是可以用这个矩阵乘法来得到结果的。得到的attention_scores的维度为[B, N, F, T]。只看后面两个维度(即只考虑一个数据、一个attention),attention_scores其实就是一个attention中Q和K作用得到的权重系数(还未经过softmax),而Q和K长度分别是F和T,因此共有F * T个这样的系数:

那么比较关键的一步来了——Mask,即将padding部分“mask”掉(这和Bert预测词向量任务时的mask是完全不同的,详情参考相关文章,这里只讨论模型的详细架构):
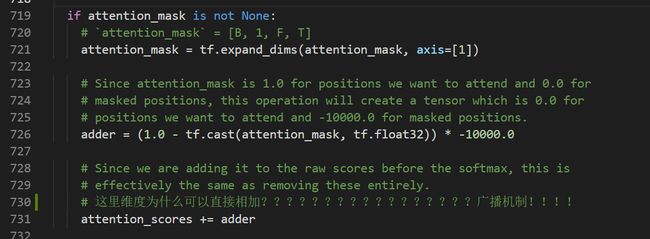
我们在前面步骤中得到的attention_mask的维度为[B, F, T],为了能实现矩阵加法,所以先在维度1上(指第二个维度,第一个维度axis=0)扩充一维,得到维度为[B, 1, F, T]。然后利用python里面的广播机制就可以相加了,要mask的部分加上-10000.0,不mask的部分加上0。这个模型的mask是在softmax之前做的,至于具体原因我也不太清楚,还是继续跟着数据流走吧。加上mask之后就是softmax,softmax之后又加了dropout:
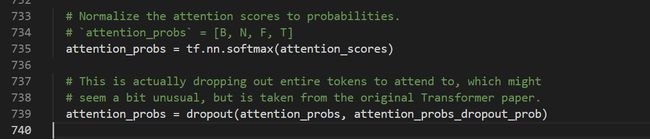
再之后就是softmax之后的权重系数乘上后面的V,得到维度为[B, N, F, H],在维度为1和维度为2的位置转置一下变成[B, F, N, H],该函数可以返回两种维度的张量:
- [B * F, N * H](源码中注释H变成了V,这一点是错误吗?还是我理解错了?)
- [B, F, N * H]
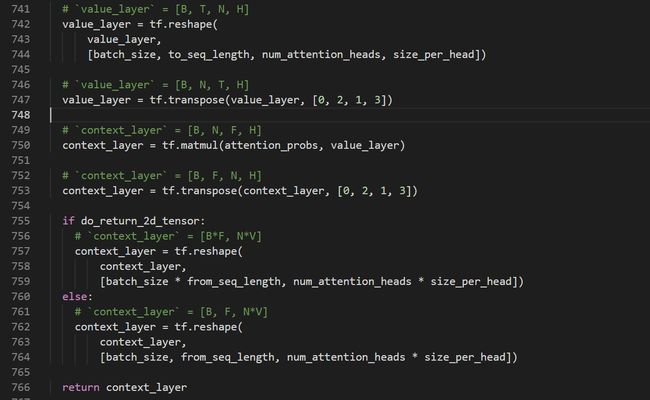
至此,我将bert模型中最为复杂的Multi-Head Attention数据变化形式讲解完了。下一个函数transformer_model搭建Bert整体模型。
transformer_model
下面我对transformer_model这个函数进行解析,该函数是将Transformer Encoded所有的组件结合在一起。 很多时候,结合图形理解是非常有帮助的。下面我们先看一下下面这个盗的图吧(我们把这个图的结构叫做transformer block吧):
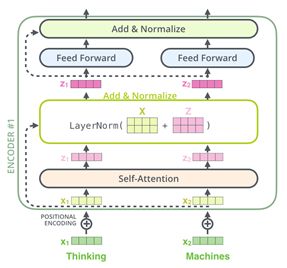
整个Bert模型其实就是num_hidden_layers个这样的结构串连,相当于有num_hidden_layers个transformer_block。而self-attention部分在上个函数已经梳理得很清楚了,剩下的其实都是一些熟悉的组件(残差、MLP、LN)。transformer_model先处理好输入的词向量,然后进入一个循坏,每个循坏就是一个block:
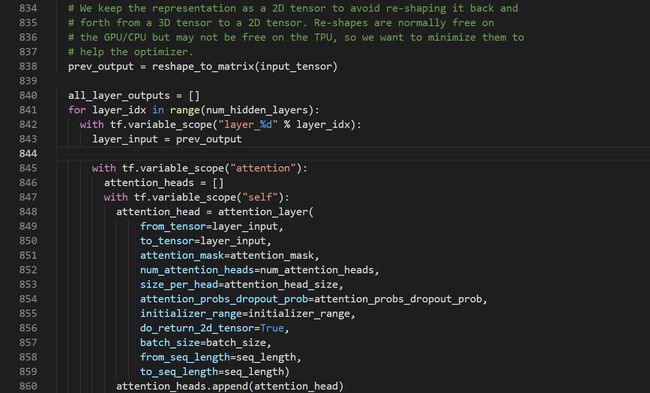
上面的截图并未包括所有的循环代码,我们一步步来走下去。显然,代码是将上一个transformer block的输出作为下一个transformer block的输入。那么第一个transformer block的输入是什么呢?当然是我们前面所说的三个输入向量相加得到的input_tensor。至于每个block维度是否对得上,计算是否准确,继续看后面的代码就知道了。该代码中还用了变量all_layer_outputs来保存每一个block的输出结果,设置参数do_return_all_layers可以选择输出每个block的结果或者最后一个block的结果。transformer_model中使用attention_layer函数的输入数据维度为二维的([B * F或B * T, hidden_size])。详细看attention_layer函数时是可以输入二维张量数据的:
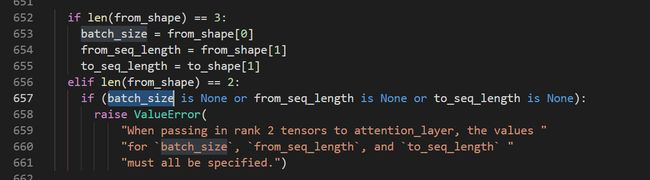
至于下面这部分为什么会有attention_heads这个变量,原因我也不知道,仿佛在这里是多此一举,源码中的解释如下:
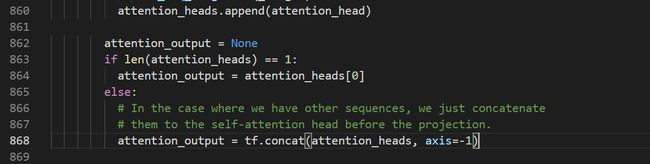
我们再回顾一下上一个函数attention_layer,return的结果维度为[B * F, N * H]或[B, F, N * H]。注意这里面使用的attention_layer函数do_return_2d_tensor参数设置为True,所以attention_output的维度为[B * F, N * H]。然后再做一层MLP(该层并没改变维度,因为hidden_size=N * H)、dropout、layer_norm:
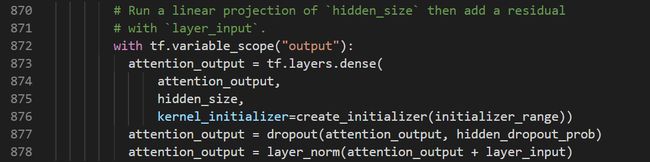
此时attention_output的维度还是[B * F, N * H或hidden_size]。由上面的图可以接下来是继续MLP层加dropout加layer_norm,只不过该层MLP的神经元数intermediate_size是一个超参数,可以人工指定:
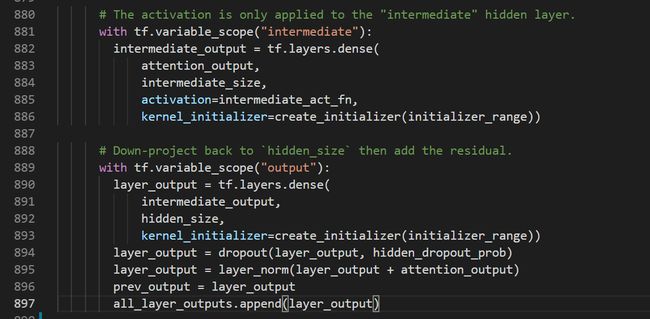
由上面截图的代码可知接下来做了两层MLP,维度变化[B * F, hidden_size]到[B * F, intermediate_size]再到[B * F, hidden_size],再经过dropout和layer_norm维度大小不变。至此,一个transformer block已经走完了。而此时得到的layer_out将作为下一个block的输入,这个维度与该模型第一个block的的输入是一样的,然后就是这样num_hidden_layers次循环下去得到最后一个block的输出结果layer_output,维度依旧为[B * F, hidden_size]。
return的时候通过reshape_from_matrix函数把block的输出变成维度和input_shape一样的维度,即一开始词向量输入input_tensor的维度([batch_size, seq_length, hidden_size])

Bert_model class
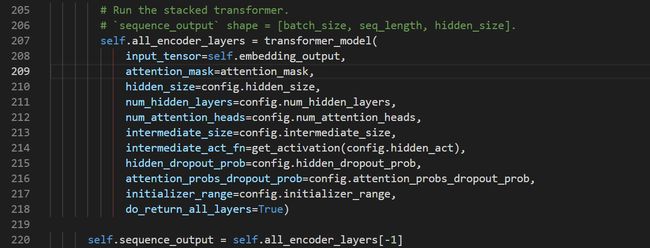
为了方便训练,模型的整个过程都封装在Bert_model类中,通过该类的实例可以访问模型中的结果。详细的过程见代码。上述几个函数梳理之后便没什么复杂的了,只是把内容整合在一起了。self.all_encoder_layers是经过transformer_model函数返回每个block的结果,self.sequence_output得到最后一个维度的结果,由上面的分析知维度为[Batch_szie, seq_length, hidden_size],这和一开始词向量的维度是一样的,只不过这个结果是经过Transformer Encoded提取特征之后的,包含重要的信息,也是Bert想得到的结果:
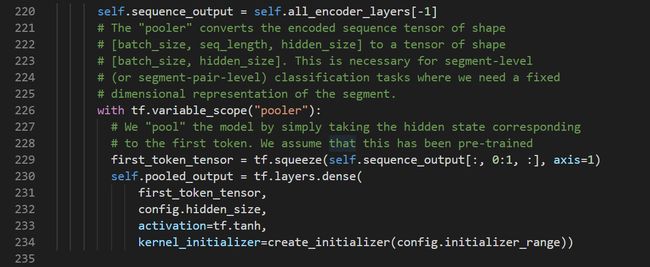
在这一步之后,该类用成员变量self.pooled_output保存第一个位置再经过一个MLP层的输出结果。熟悉数据输入形式的可以知道,这个位置是[CLS],该位置的输出在Bert预训练中是用来判断句子上下文关系的:
这里保存该结果除了可以用于Bert预训练,还可以微调Bert用于分类任务,详细可参考:
https://www.jianshu.com/p/22e462f01d8c
后续
文中可能存在不少笔误或者理解不正确的表达不清晰地方敬请谅解,非常欢迎能提出来共同学习。