SRA—>FASTQ—>BAM—>COUNTS 这几个步骤而已,中间穿插一些质控的手段,每个步骤选择好合适的软件即可。可以参考:一个植物转录组项目的实战 http://www.bio-info-trainee.com/2809.html
这是RNA-Seq 上游分析的大致流程,比对+定量。当然实验目的若只需要定量已知基因,也可以选择free-alignment 的流程工具如kallisto/Salmon/Sailfish,其优点是可用于RNA-seq的基因表达的快速定量,但是对于小RNA和表达量低的基因分析效果并不好(2018年刚发表的一篇文章对free-alignment 的工具进行了质量评估,doi: https://doi.org/10.1101/246967)。基于比对的流程,比对工具也有很多选择,如Hisat,STAR,Tophat(hista可以替代tophat),bowtie等, 还有据说速度超快的Subread。根据比对工具的选择,定量软件也可以配套选择,如
STAR/bowtie—RSEM;
Hisat —featureCounts/HTseq;
Subread—featureCounts。
由于后续要鉴定新的转录本,因此需要对转录本组装,组装可以选择cufflinks,或者stringtie。文章是用的Tophat+cufflinks。我的后续分析打算用Hisat2比对,stringtie组装,featureCounts定量,同时打算尝试下Subread+featureCounts的流程。
Hisat2+stringtie+featureCounts;
Subread+featureCounts。
SRA—>FASTQ
sra格式的数据需要先用fastq-dump转换, --split-3 表示双端测序,--gzip将生成的fastq文件压缩。
cd /pnas/fangxd_group/renyx/macaque/01rawdata
for ((i=230;i<=237;i++)) ;do /software/biosoft/software/sratoolkit.2.8.2-1-centos_linux64/bin/fastq-dump --split-3 --gzip SRR4042$i.sra;done
质控
mkdir QC
echo "fastqc started at $(date)" #输出运行时间
fastqc -o QC *gz
multiqc *fastqc.zip --ignore *.html
echo "fastqc finished at $(date)"
质控检测采用fastqc和multiqc联合使用, multiqc有利于多个样本同时展示质量检测结果。FastQC的检测报告左侧会给出测序质量的一个summary,通常并不是所有的检测项都会是绿色通过,会有一些警告和fail的项目。主要可以从Per base sequence quality 看一下测序碱基质量,Per sequence GC content 看一下GC含量,如果实际的GC含量(红线)出现双峰,且导致后期的序列比对很低时,需要引起注意,有可能是存在样品污染;再者就是看一下Adapter是否去除及去除的是否干净。这里的Adapter虽然显示通过,但是去除的并不干净,所以后续还会进一步去除Adapter。

去除接头和低质量值
Trimmomatic 支持多线程,处理数据速度快,主要用来去除 Illumina 平台的 fastq 序列中的接头,并根据碱基质量值对 fastq 进行修剪。软件有两种过滤模式,分别对应 SE 和 PE 测序数据,同时支持 gzip 和 bzip2 压缩文件。另外也支持 phred-33 和 phred-64 格式互相转化。
Trimmomatic 过滤步骤
Trimmomatic 过滤数据的步骤与命令行中过滤参数的顺序有关,通常的过滤步骤如下:
ILLUMINACLIP: 过滤 reads 中的 Illumina 测序接头和引物序列,并决定是否去除反向互补的 R1/R2 中的 R2, 该引物序列可以在Trimmomatic软件的安装目录下找到,双端通常选择TruSeq3-PE-2。
SLIDINGWINDOW: 从 reads 的 5’ 端开始,进行滑窗质量过滤,切掉碱基质量平均值低于阈值的滑窗。
MAXINFO: 一个自动调整的过滤选项,在保证 reads 长度的情况下尽量降低测序错误率,最大化 reads 的使用价值。
LEADING: 从 reads 的开头切除质量值低于阈值的碱基。
TRAILING: 从 reads 的末尾开始切除质量值低于阈值的碱基。
CROP: 从 reads 的末尾切掉部分碱基使得 reads 达到指定长度。
HEADCROP: 从 reads 的开头切掉指定数量的碱基。
MINLEN: 如果经过剪切后 reads 的长度低于阈值则丢弃这条 reads。
AVGQUAL: 如果 reads 的平均碱基质量值低于阈值则丢弃这条 reads。
TOPHRED33: 将 reads 的碱基质量值体系转为 phred-33。
TOPHRED64: 将 reads 的碱基质量值体系转为 phred-64。
参考:NGS 数据过滤之 Trimmomatic 详细说明
echo "trimmomatic cut adapters started at $(date)"
for i in {230..237}
do
java -jar /software/biosoft/software/Trimmomatic-0.36/trimmomatic-0.36.jar PE -threads 4 SRR4042$i\_1.fastq.gz SRR4042$i\_2.fastq.gz \
SRR4042$i\_paired_clean_R1.fastq.gz \
SRR4042$i\_unpair_clean_R1.fastq.gz \
SRR4042$i\_paired_clean_R2.fastq.gz \
SRR4042$i\_unpair_clean_R2.fastq.gz \
ILLUMINACLIP:/software/biosoft/software/Trimmomatic-0.36/adapters/TruSeq3-PE-2.fa:2:30:10:1:true \
LEADING:3 TRAILING:3 SLIDINGWINDOW:4:20 MINLEN:50 TOPHRED33
done
mv *_paired_clean* ../02clean_data/
echo "trimmomatic cut adapters finished at $(date)"
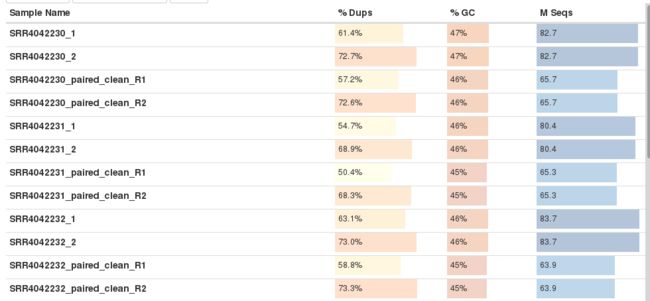
质控前后的结果
Hisat2 比对+featureCounts定量
Hisat2 比对,首先用hisat2-build 构建index,然后比对,输出sam格式,再用samtools将sam转为bam格式,并排序构建索引。
featureCounts 目前已经整合在subread,subread是一个综合的软件,还包括比对的工具和对应的R包, featrueCounts的定量效果和HTSeq差不多,但是featureCounts的优点非常快!
featureCounts下载
二进制版本的软件解压即可使用
#下载subread
wget https://sourceforge.net/projects/subread/files/subread-1.5.3/subread-1.5.3-Linux-x86_64.tar.gz
tar zxvf subread-1.5.3-Linux-x86_64.tar.gz
常用参数说明:
-p 针对paired-end数据
-T 多线程数
-t 默认将exon作为一个feature
-g 默认是gene_id,从注释文件中提取Meta-features信息用于read count
-a 基因组注释文件,默认是gtf
-o 输出文件
(PS:存储不够了,后续选择两组数据做流程分析。)
echo "hisat2 started at $(date)"
#make index
cd /pnas/fangxd_group/renyx/macaque/00ref
hisat2-build -p 8 Macaca_mulatta.Mmul_8.0.1.dna.toplevel.fa maca_index
#alignment
for i in {230..231}
do
hisat2 -t -x 00ref/maca_index -1 02clean_data/SRR4042$i\_paired_clean_R1.fastq.gz \
-2 02clean_data/SRR4042$i\_paired_clean_R2.fastq.gz \
-S 03align_out/SRR4042$i\.sam
done
#covert to bam, and sort bam
for i in {230..231}
do
samtools view -Sb SRR4042$i\.sam > SRR4042$i\.bam
samtools sort SRR4042$i\.bam -o SRR4042$i\_sorted.bam
samtools index SRR4042$i\_sorted.bam
rm *sam
done
echo "hisat2 finished at $(date)"
#featureCounts定量
cd /pnas/fangxd_group/renyx/macaque/
featureCounts=/pnas/fangxd_group/renyx/software/subread-1.5.3-Linux-x86_64/bin/featureCounts
$featureCounts -p -T 6 -t exon -g gene_id -a 00ref/Macaca_mulatta.Mmul_8.0.1.91.gtf \
-o 05featurecount_out/counts.txt 03align_out/hisat2_mapping/*sorted.bam
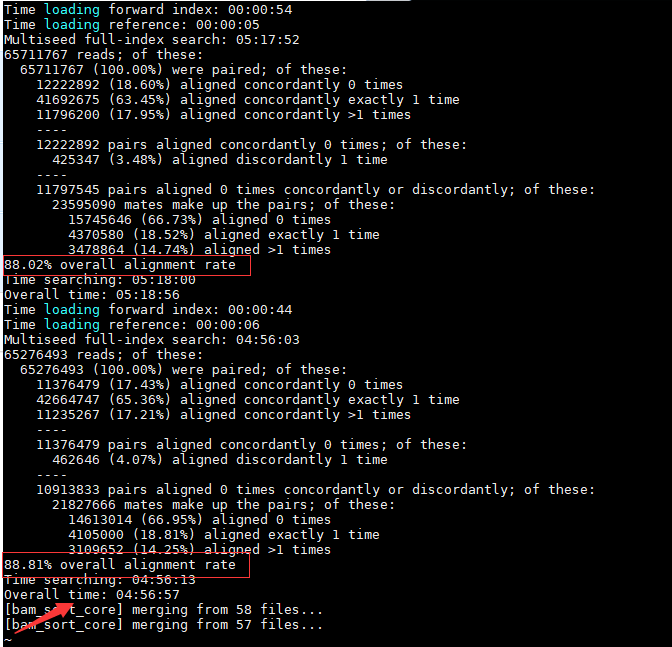
Hisat2的比对结果:
SRR4042230和SRR4042231的比对率分别为88.02%和88.81%,总比对时间将近5小时。
featureCounts结果产生两个文件:
hisat_counts.txt.summary包含一些基本的统计信息。

hisat_counts.txt
包含8列信息,分别是Geneid;Chr 染色体号,这里会显示多个数目;Start; End; Strand; Length; 第7列和第8列显示的是Counts数。

subread 比对+定量
#make subread index
echo "subread started at $(date)"
buildindex=/pnas/fangxd_group/renyx/software/subread-1.5.3-Linux-x86_64/bin/subread-buildindex
cd /pnas/fangxd_group/renyx/macaque/00ref
$buildindex -o maca Macaca_mulatta.Mmul_8.0.1.dna.toplevel.fa
#alignment
subjunc=/pnas/fangxd_group/renyx/software/subread-1.5.3-Linux-x86_64/bin/subjunc
subjunc_maca_index=/pnas/fangxd_group/renyx/macaque/00ref/maca
cd /pnas/fangxd_group/renyx/macaque/
for i in {230..231}
do
$subjunc -T 5 -i $subjunc_maca_index -r 02clean_data/SRR4042$i\_paired_clean_R1.fastq.gz -R 02clean_data/SRR4042$i\_paired_clean_R2.fastq.gz -o 03align_out/subread_mapping/SRR4042$
done
#counts expre
featureCounts=/pnas/fangxd_group/renyx/software/subread-1.5.3-Linux-x86_64/bin/featureCounts
$featureCounts -p -T 6 -t exon -g gene_id -a 00ref/Macaca_mulatta.Mmul_8.0.1.91.gtf \
-o 05featurecount_out/subread_counts.txt 03align_out/subread_mapping/*_subjunc.bam
echo "subread finished at $(date)"
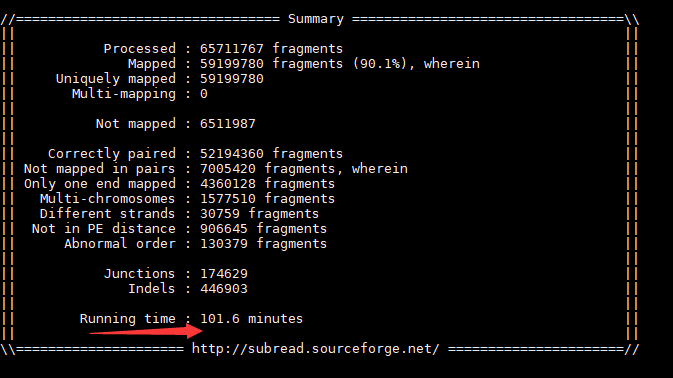

可以看出subjunc比对不到2小时,比hisat2快3个多小时。
提取counts
根据第1列是Geneid,第7,8列是counts数,用awk提取出geneID和counts。
awk -F '\t' '{print $1,$7,$8}' OFS='\t' hisat_counts.txt >hisat_matrix.out
awk -F '\t' '{print $1,$7,$8}' OFS='\t' subread_counts.txt >subread_matrix.out
参考资料:
一个植物转录组项目的实战
史上最快的转录组流程-subread
转录组定量-FEATURECOUNTS