正则表达式符号与方法



符号.是一个占位符
import re
# .的使用举例
a = 'xy123'
b = re.findall('x.',a)
print b
输出:xy
符号*匹配前一个字符0次或无限次
#*的使用举例
a = 'xyxy123'
b = re.findall('x*',a)
print b
输出:['x', '', 'x', '', '', '', '', '']
符号?匹配前1个字符0次或1次
#?的使用举例
a = 'xy123'
b = re.findall('x?',a)
print b
输出:['x', '', '', '', '', '']
.:贪心算法
.?:非贪心算法
# .*的使用举例
secret_code = 'hadkfalifexx|xxfasdjifja134xxlovexx23345sdfxxyouxx8dfse'
b = re.findall('xx.*xx',secret_code)
print b
输出:['xx|xxfasdjifja134xxlovexx23345sdfxxyouxx']
# .*?的使用举例
c = re.findall('xx.*?xx',secret_code)
print c
输出:['xx|xx', 'xxlovexx', 'xxyouxx']
# 使用括号与不使用括号的差别
# 返回()内的数据
d = re.findall('xx(.*?)xx',secret_code)
print d
for each in d:
print each
�输出:['|', 'love', 'you']
|
love
you
. 无法处理换行符
s = '''sdfxxhello
xxfsdfxxworldxxasdf'''
d = re.findall('xx(.*?)xx',s)
print d
输出:['fsdf']
# re.S的作用使 . 包括\n
s = '''sdfxxhello
xxfsdfxxworldxxasdf'''
d = re.findall('xx(.*?)xx',s,re.S)
print d
输出:['hello\n', 'world']
对比findall与search的区别
s2 = 'asdfxxIxx123xxlovexxdfd'
f = re.search('xx(.*?)xx123xx(.*?)xx',s2).group(1) #输出:I
# f = re.search('xx(.*?)xx123xx(.*?)xx',s2).group(2) #输出:love
print f
#finall
f2 = re.findall('xx(.*?)xx123xx(.*?)xx',s2)
print f2[0][1] #输出love

sub使用举例:
实战——制作文本爬虫

目标
目标网站右键打不开,换一个http://wiki.jikexueyuan.com/
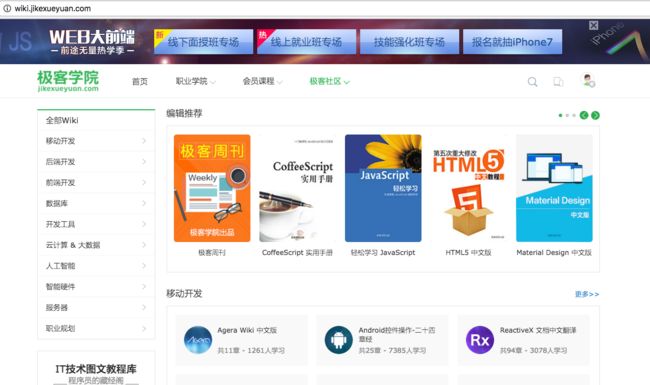
极客学院Wiki
找到图片,右键检查
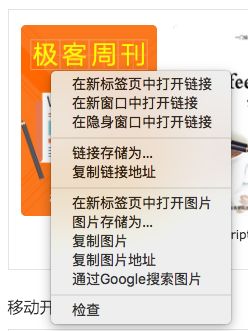

找到对应代码
在页面源代码搜索class="imgbox"

选择这一部分,源代码复制到source.txt

picdownloader.py
#!/usr/bin/python
#-*- coding:utf-8 -*-
import re
import requests
#读取源代码文件
f = open('source.txt','r')
html = f.read()
f.close()
#匹配图片网址
pic_url = re.findall('img src="(.*?)" alt=',html,re.S)
i = 0
for each in pic_url:
print 'now downloading : ' + each
pic = requests.get(each)
fp = open('pic\\' + str(i) + '.jpg','wb')
fp.write(pic.content)
fp.close()
i += 1
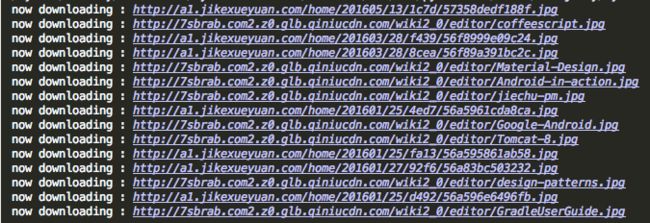
picdownloader.py运行效果
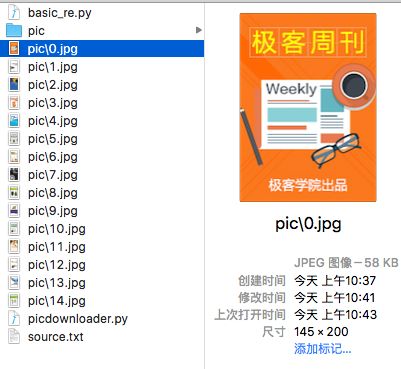
成功保存了图片
手工找到页面再下载显得有点low:修改代码使�其自动获取源代码
#!/usr/bin/python
#-- coding:utf-8 --
import re
import requests
import urllib2
#读取源代码文件
#f = open('source.txt','r')
url = 'http://wiki.jikexueyuan.com/'
response = urllib2.urlopen(url)
htmls = response.read()
#匹配图片网址
#由于是下载整个页面,所以原来的正则表达式会匹配更多的内容
#所以采用先抓大再抓小,把范围缩小~
picsurl = re.findall('(.*?) ',htmls,re.S)
#findall返回的是一个列表,需要将列表再次弄成一个string,逐个写入一个txt
f = open('url.txt','wb')
for i in picsurl:
f.write(i)
f.close()
ff = open('url.txt','r')
html = ff.read()
ff.close()
#这代码写得确实有点烂。。。。
pic_url = re.findall('img src="(.*?)" alt=',html,re.S)
i = 0
for each in pic_url:
print 'now downloading : ' + each
pic = requests.get(each)
fp = open('pic\\' + str(i) + '.jpg','wb')
fp.write(pic.content)
fp.close()
i += 1
效果同上
换个网站试试
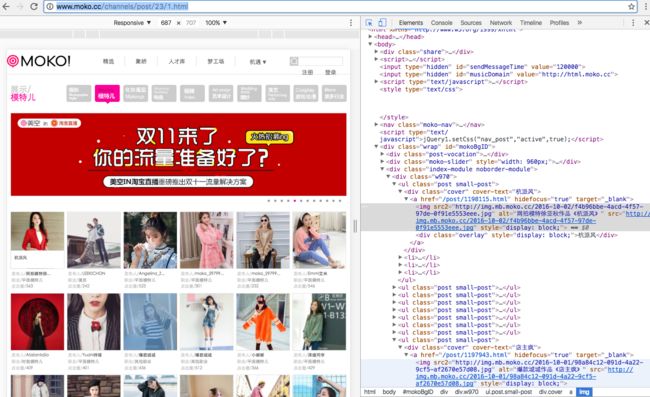
【美空模特频道】
#!/usr/bin/python
#-*- coding:utf-8 -*-
import re
import requests
import urllib2
#读取源代码文件
url = 'http://www.moko.cc/channels/post/23/1.html'
response = urllib2.urlopen(url)
htmls = response.read()
#匹配图片网址
pic_url = re.findall('img src2="(.*?)" alt=',htmls,re.S)
i = 0
for each in pic_url:
print 'now downloading : ' + each
pic = requests.get(each)
fp = open('picmoko\\' + str(i) + '.jpg','wb')
fp.write(pic.content)
fp.close()
i += 1


jkxyclass Finder
把第一页的48张封面图给爬下来了~
实战——处理文本
准备下个电视剧,用mac的浏览器打开了一个页面
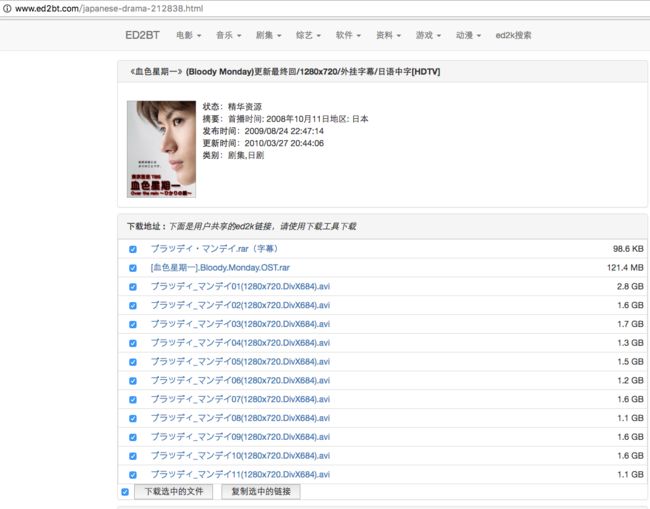
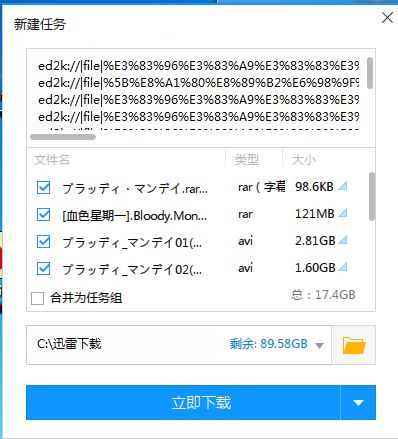
《血色星期一》(Bloody Monday)更新最终回-1280x720-外挂字幕-日语中字[HDTV]
然而mac没有装迅雷,都是用虚拟机里面的破解版迅雷下载的。
这个时候直接点页面就尴尬了,无法调用迅雷
右键看了看,页面源代码

view-source.www.ed2bt.com-japanese-drama-212838.html Google Chrome
发现ed2k链接都在里面,一看就可以用正则表达式处理一下,然后复制到虚拟机的迅雷里面创建任务
将部分页面源代码复制保存到test111.txt
# -*- coding:utf-8 -*-
#test111.py
__author__ = 'jerry'
import re
f = open('test111.txt','r')
html = f.read()
f.close()
web = re.findall('href="(.*?)">',html,re.S)
i=0
while i<13:
print web[i]
i+=1

输出结果
复制到虚拟机的迅雷里面创建任务