1. 论文相关
CVPR2019
基于局部描述子的图像到类度量的小样本学习

2.摘要
2.1 摘要
图像分类中的小样本学习是指在每一类训练样本较少的情况下,学习一个分类器对图像进行分类。最近的工作已经取得了很好的分类性能,其中通常使用基于图像级特征的度量。在这篇文章中,我们认为,在这样一个水平上的措施可能不够有效,因为小样本学习的例子很少。相反,我们认为应该采用基于局部描述符的图像到类度量(image-to-class measure),这是因为它在局部不变特征的全盛时期(heydays)取得了惊人的成功。具体地说,我们在最近几次训练机制(episodic training mechanism,)的基础上,提出了一种深度最近邻神经网络(Deep Nearest Neighbor Neural Network,简称DN4),并对其进行端到端的训练。它与文献的主要区别在于用基于局部描述符的图像到类度量代替了最后一层基于图像级特征的度量。此措施通过卷积特征映射深层局部描述子的k近邻搜索。所提出的DN4不仅学习了图像到类度量的最优深层局部描述符,而且由于视觉模式在同一类图像中的可交换性,在实例不足的情况下利用了这种度量的更高效率。我们的工作创造了一个简单,有效,计算效率高的框架,用于小样本学习。对基准数据集的实验研究始终显示出其相对于相关技术的优越性,最大的绝对改进是17%,相对第二好的方案。源代码可以从网址:https://github.com/WenbinLee/DN4.git。
2.2 主要贡献
这项工作提供了两个关键的见解。首先,将图像的局部特征归纳为紧凑的图像级表示可能会丢失相当多的判别信息。当训练实例数量较少时,它将无法恢复。其次,在这种情况下,如果使用图像对图像的度量,直接使用这些局部特征进行分类将不起作用。相反,一个图像到类的度量应该采取,利用这样一个事实,一个新的图像可以粗略地“组成”使用在同一类的其他图像。以上两个见解启发我们回顾现有的几种方法在小样本学习中的分类方法,并重新思考NBNN方法,以深入学习这一任务。
具体地说,我们开发了一种新的深度最近邻神经网络(简称DN4),用于小样本学习。它遵循最近的阶段性训练机制,完全可以端到端训练。它与现有的相关方法的主要区别在于它用局部描述符为基础的图像到类的度量代替了在最终层中的基于图像级特征的度量。与NBNN[1]类似,该测度是通过局部描述符上的最近邻搜索来计算的,不同的是这些描述符现在是通过卷积神经网络进行深入训练的。训练后,将所提出的网络应用于新的小样本学习任务是简单的,包括局部描述符提取和最近邻搜索。有趣的是,在计算方面,每个类的例子的缺乏现在证明是一个“优势”,这使得NBNN对于小样本学习更有吸引力。它减少了从大量的局部描述符中寻找最近邻的计算量,这是NBNN在大规模图像分类中较不受欢迎的一个因素。
在多个基准数据集上进行了实验,比较了所提出的DN4与原NBNN及相关的最新方法在小样本学习任务中的性能。提出的方法再次证明了令人惊讶的成功。将minimagenet上的1-shot and 5-shot精度分别从50.44%提高到51.24%和66.53%提高到71.02%。特别是在细粒度数据集上,它比次优方法获得了17%的最大绝对改进。
2.3 相关工作
(1)
(2)
3.提出的方法
3.1. 问题表述
3.2. NBNN方法的动机
这项工作很大程度上受到了[1]中朴素贝叶斯最近邻(NBNN)方法的启发。NBNN的两个关键观察结果如下所述,我们证明它们直接适用于小样本学习。
首先,对于图像分类中的(当时流行的)特征袋模型(bag-of-features model),通常将局部不变特征量化为可视词,以生成词在图像中的分布(例如,通过和池获得的直方图)。在文献[1]中观察到,由于量化误差,这样的图像级表示可以显著地丢失判别信息。如果有足够的训练样本,后续的学习过程(例如,通过支持向量机)可以从这种损失中恢复,仍然显示出令人满意的分类性能。然而,当训练样本不足时,这种损失是不可恢复的,导致分类不良。
小样本学习比NBNN更受例子稀缺性的影响。现有的方法通常将最后的卷积特征图(例如,通过全局平均池或完全连接层)汇集到最终分类的图像级表示。在这种情况下,这样的信息丢失也会发生,并且是不可恢复的。
其次,如文献[1]所进一步观察到的,利用两幅图像的局部不变特征,而不是它们的图像级表示,来度量一幅图像与另一幅图像之间的相似性进行分类,仍然会产生很差的结果。这是因为这样一个图像到图像的相似性并没有超出训练样本的范围。当训练样本数较少时,由于类内变化或背景杂波的影响,查询图像可能与同一类的任何训练样本不同。相反,应该使用图像到类的度量。具体来说,同一类训练样本的局部不变特征被收集到一个集合中。该度量评估查询图像的局部特征的接近度(例如,通过最近邻搜索)到每个类的池进行分类。
同样,这种观察也适用于小样本学习。本质上,上面的图像到类的度量打破了同一类中的训练图像的边界,并共同使用它们的局部特征来为类提供更丰富和更灵活的表示。如[1]所示,通过使用同一类中的其他图像片段(即,视觉模式在同一类中的图像之间的可交换性)可以大致“合成”新图像这一事实,可以证明该设置是合理的。
3.3. 提出的DN4框架
上述分析促使我们重新审视小样本学习中的最终分类方法,并重新考虑NBNN方法。由此提出了深度最近邻神经网络(简称DN4)的框架。
如图1所示,DN4主要由两部分组成:深度嵌入模块Ψ和图像到类的度量模块Φ(a deep embedding module和 an imageto-class measure module)。前者学习所有图像的深层局部描述。利用学习到的描述符,后者计算上述图像到类的度量。重要的是,这两个模块被集成到一个统一的网络中,并从头开始以端到端的方式进行训练。另外,请注意,设计的图像到类模块可以很容易地与任何深度嵌入模块一起工作。
深度嵌入模块(Deep embedding module)
模块Ψ学习查询和支持图像的特征表示。任何合适的CNN都可以使用。注意,Ψ只包含卷积层,没有全连接层,因为我们只需要深层的局部描述符来计算图像到类的度量。简言之,给定一幅图像X,Ψ(X)将是一个h×w×d的张量,它可以看作一组m(m=hw)个d维局部描述子:
其中是第i个深度局部描述符。在我们的实验中,给定一幅分辨率为84×84的图像,我们可以得到h=w=21和d=64。这意味着每幅图像 总的来说都有441个深度局部描述子。
图像到类模块(Image-to-Class module)
模块Φ使用一个类中所有训练图像的深层局部描述符来构造该类的局部描述符空间。在这个空间中,我们通过k-NN计算查询图像和这个类之间的图像到类的相似性(或距离),如[1]。
具体来说,通过模Ψ,给定的查询图像q将被嵌入为。对于每一个描述符,我们首先查找K最近邻居。然后计算与之间的相似度,并将相似度求和为图像与类之间的相似度。从数学上讲,图像到类的度量可以很容易地表示为:

其中cos(·)表示余弦相似性。当然也可以使用其他的相似性或距离函数。
注意,就计算效率而言,与文献[1]中的一般图像分类相比,图像到类度量似乎更适合于小样本分类。由于在小样本环境中训练样本的数量要少得多,从一个庞大的局部描述符池中搜索K-最近邻引起的NBNN中的主要计算问题现在已经被大大削弱。这使得所提出的框架具有计算效率。此外,与NBNN相比,它将更具前景,因为它得益于深度特征表示,而深度特征表示比NBNN中使用的手工特征强大得多。
最后,值得一提的是,DN4中的图像到类模块是非参数的。如果不考虑嵌入模Ψ,则整个分类模型是非参数的。由于非参数模型不涉及参数学习,因此参数化小样本学习方法(例如,在图像级表示上学习全连接层)中的过拟合问题也可以在一定程度上得到缓解。

3.4. 网络体系结构
为了与目前最先进的方法进行比较,我们采用了一种常用的四层卷积神经网络作为嵌入模块。它包含四个卷积块,每个卷积块由卷积层、批处理规范化层和Leaky ReLU层组成。此外,对于前两个卷积块,还分别附加2×2 max池化层。由于每个卷积层有64个3×3大小的滤波器,因此该嵌入网络被命名为Conv-64F。至于图像到类模块,唯一的超参数是参数k,这将在实验中讨论。
在每一次迭代的场景训练中,我们将一个支持集和一个查询图像输入到我们的模型中。通过嵌入模Ψ,我们得到了所有这些图像的深度局部表示。然后通过模块Φ,我们通过公式(2)计算出每个类之间的图像到类的相似度。对于C-way K-shot任务,我们可以得到一个相似度向量。对应于z的最大分量的类将是查询q的预测结果。
4. 实验结果
本部分的主要目的是研究两个有趣的问题:(1)基于非 episodic训练的NBNN的预训练深度特征对fewshot学习有何影响?(2)我们提出的DN4框架,即基于CNN的端到端幕式训练方式的NBNN,如何在少数镜头学习中发挥作用?
(1)How does the pre-trained deep features based NBNN without episodic training perform on the fewshot learning?
(2)How does our proposed DN4 framework,i.e., a CNN based NBNN in an end-to-end episodic training manner, perform on the few-shot learning?
4.1. 数据集集合
我们在以下四个基准数据集上进行了所有实验。
miniImageNet
作为ImageNet[15]的一个小版本,这个数据集[22]包含100个类,每个类600个图像,每个图像的分辨率为84×84。在[14 ]中使用的分裂之后,我们分别采用64, 16和20类进行训练(辅助)、验证和测试。
Stanford Dogs
该数据集[7]最初用于细粒度图像分类任务,包括120个犬种(类),共20580幅图像。在这里,我们在这个数据集上进行细粒度的少镜头分类任务,分别进行70, 20个和30个类的训练(辅助)、验证和测试。
Stanford Cars
该数据集[10]也是细粒度分类任务的基准数据集,由196类汽车组成,共有16185幅图像。类似地,这个数据集中的130, 17个和49个类被划分为训练(辅助)、验证和测试。
CUB-200
这个数据集[23]包含来自200种鸟类的6033幅图像。以同样的方式,我们选择130, 20和50类训练(辅助),验证和测试。
对于最后三个细粒度数据集,这些数据集中的所有图像都被调整为84×84的minimagenet。
4.2. 实验装置
所有的实验都是围绕着对上述数据集进行的C-wayK-shot分类任务进行的。具体来说,将对所有这些数据集执行5-way 1-shot and 5-shot分类任务在训练过程中,我们随机抽取30万episode样本,采用episode训练机制对所有模型进行训练。在每一episode中,除了每个类中的支持图像(shot)之外,还将从每个类中分别选择15个和10个查询图像用于1-shot和5-shot设置。换句话说,对于一个5-way 1-shot任务,在一个训练集中将有5个支持图像和75个查询图像。为了训练我们的模型,我们采用Adam算法[8],初始学习率为,每100000个episode减少一半。
在测试过程中,我们从测试集中随机抽取600个episode样本,以前1名的平均准确度作为评价标准。这个过程将重复五次,并报告最终的平均精度。此外,还报告了95%置信区间。值得注意的是,我们所有的模型都是以端到端的方式从头开始训练的,在测试阶段不需要微调。
4.3. 比较方法
基线方法
为了说明上述数据集的基本分类性能,我们实现了一个基线方法。特别地,我们采用基本的嵌入网络CON-64 F和附加三个FC层来在相应的训练(辅助)数据集上训练分类网络。在测试过程中,我们使用这个预先训练好的网络从最后一个FC层提取特征,并使用a-NN分类器得到最终的分类结果。此外,为了回答第4节开头的第一个问题,我们使用从上述k-NN(深度全局特征)方法截断的预训练Conv-64F重新实现了NBNN算法[1]。这种新的NBNN算法使用深度局部描述符而不是手工创建的描述符(即SIFT),称为NBNN(深度局部特征)。
基于度量学习的方法
由于我们的方法属于度量学习分支,因此我们主要将我们的模型与四个最新的基于度量学习的模型进行比较,这些模型包括匹配网络FCE[22]、原型网络[17]、关系网络[25]和图神经网络(GNN)[4]。请注意,我们使用Conv-64F作为其嵌入模块重新运行GNN模型,因为原始GNN采用不同的嵌入模块Conv-256F,它也有四个卷积层,但对应层分别有64、96、128和256个滤波器。此外,我们通过相同的5-way训练设置重新运行原型网,而不是原始工作中的20路训练设置,以便进行公平的比较。
基于元学习的方法
除了基于metric learning的模型外,本文还选取了五种最新的基于元学习的模型作为参考。这些模型包括元学习者LSTM[14]、模型不可知元学习(MAML)[3]、简单神经注意学习器(SNAIL)[13]、MM网[2]和动态网[5]。由于SNAIL采用了更复杂的ResNet-256F(ResNet[6]的较小版本)作为嵌入模块,因此我们将根据附录中提供的Conv-32F报告其结果,以便进行公平比较。请注意,Conv-32F与Conv-64F具有相同的体系结构,但是每个卷积层有32个滤波器,这也被元学习器LSTM和MAML用来减少过度拟合。
4.4. 小样本分类
在minimagenet上完成了一般的小样本分类任务。结果如表1所示,其中超参数设置k为3。从表1中可以看到,NBNN(Deep local features)比k-NN(Deep global features)能获得更好的结果,甚至比匹配网络FCE、元学习器LSTM和SNAIL(Conv-32F)还要好。这不仅验证了局部描述子的性能优于图像级特征(即-NN使用的FC层特征),而且也说明了图像到类的度量是非常有前途的。然而,NBNN(Deep local features)与目前最先进的原型网络、关系网络和GNN相比仍有较大的性能差距。究其原因,NBNN(Deep local features)作为一种懒惰的学习算法,既没有训练阶段,又缺乏episodic training。到目前为止,第一个问题已经得到了回答。
相反,我们提出的DN4将图像到类度量嵌入到一个深度神经网络中,通过采用episodic训练,可以联合学习深度局部描述子,确实取得了较好的效果。与基于度量学习的模型相比,我们的DN4(Conv64F)在5-way 1-shot分类任务中分别比匹配网FCE、GNN(Conv-64F)、原型网(即通过5-way 训练设置)和关系网提高了7.68%、2.22%、2.79%和0.8%。在5-way 5-shot分类任务中,我们甚至可以得到15.71%,7.52%,4.49%和5.7%的显著改进。原因是这些方法通常使用的图像级特征数量太少,而我们的DN4采用的是可学习的深层局部描述符更丰富,尤其是在5-shot的情况下。另一方面,局部描述子具有可交换性,使得基于局部描述子的类的分布比基于图像级特征的类的分布更为有效。因此,第二个问题也可以回答。
为了全面了解小样本学习领域,我们还报告了最新的基于元学习的方法的结果。我们可以看到,我们的DN4仍然与这些方法竞争。特别是在5-way 5-shot设置中,我们的DN4分别比SNAIL(Conv-32F)、元学习器LSTM、MAML和MM网提高了15.82%、10.42%、7.91%和4.05%。对于两阶段模型DynamicNet,在进行小样本训练之前,它会预先训练所有类的模型,而我们的DN4则不会。更重要的是,我们的DN4只有一个单一的统一网络,这比这些基于元学习的方法简单得多,并且有额外的复杂的内存寻址架构。

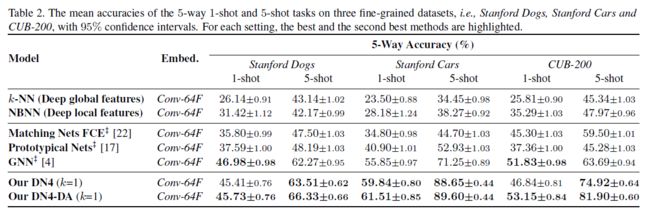
4.5. 细粒度小样本分类(Finegrained Fewshot Classification)
除了一般的小样本分类外,我们还对斯坦福狗、斯坦福汽车和CUB-200三个细粒度数据集进行了细粒度的小样本分类。在这三个数据集上实现了两个基线模型和三个最先进的模型,即k-NN(深度全局特征)、NBNN(深度局部特征)、匹配网络FCE[22]、原型网络[17]和GNN[4]。结果见表2。一般来说,由于细粒度数据集的类间变化较小,类内变化较大,细粒度的小样本分类任务比一般分类任务更具挑战性。通过比较表1和表2中相同方法的性能可以看出这一点。在细粒度数据集上,k-NN(Deep global features)、NBNN(Deep local features)和原型网络的性能比minimagenet差。还可以观察到,NBNN(Deep local features)的性能始终优于k-NN(Deep global features)。
由于细粒度任务的类间变化很小,我们为DN4选择k=1以避免引入噪声视觉模式。从表2可以看出,我们的DN4在5-shot设置下对这些数据集的性能出奇地好。特别是在斯坦福汽车上,我们的DN4比第二好的方法(即GNN)获得了最大的绝对改进,提高了17%。在1-shot设置下,我们的DN4表现不如5-shot设置。关键原因在于我们的模型依赖于最近邻算法,这是一种懒惰的学习算法,其性能在很大程度上取决于样本数。这一特性如表5所示,即DN4的性能随着样本数(the number of shots)的增加而越来越好。另一个原因是这些细粒度数据集不够大(例如,CUB-200只有6033幅图像),导致在训练深层网络时过度拟合。为了避免过度拟合,我们通过裁剪和水平翻转随机执行训练(辅助)集上的数据增强。然后,我们在这些扩充数据集上重新训练我们的模型,即DN4-DA,但在原始测试集上进行测试。可以看出,我们的DN4-DA在1-shot和5-shot两种情况下都能获得几乎最好的结果。细粒度的识别在很大程度上依赖于细微的局部视觉模式,并且它们可以被模型中强调的可学习的深层局部描述符自然捕获。
4.6. 讨论
消融研究(Ablation study)
为了进一步验证图像到类度量比图像到图像度量更有效,我们通过开发两个DN4图像到图像(简称IoI)变体来进行消融研究。具体地说,第一个变体DN4-IoI-1将图像的所有局部描述符连接为高维(h×w×d)特征向量,并使用图像到图像的度量。至于第二个变体(简称DN4-IoI-2),它保留了像DN4这样的本地描述符,而没有连接。DN4-IoI-2和DN4的唯一区别是DN4-IoI-2限制在每个单独的支持图像中搜索查询图像的本地描述符的k-NN,而DN4可以从一个完整的支持类中搜索。在1-shot设置下,DN4-IoI-2和DN4是同一的(identical)。两个变体仍然采用k-NN查找,对于1-shot和5-shot分别采用k=1和k=3。
miniImageNet的结果如表3所示。如图所示,DN4-IoI-1通过将连接的全局特征与图像到图像度量一起使用,显然表现最差。相比之下,DN4-IoI-2在1-shot和5-shot任务中都表现出色,这证明了局部描述符的重要性和可交换性(在一个图像中)。值得注意的是,DN4在5-shot任务中优于DN4-IoI-2,这表明在类中利用视觉模式的可交换性确实有助于获得性能。


骨干网的影响(Influence of backbone networks)
除了常用的Conv-64F外,我们还使用了另一个更深层次的嵌入模块,即SNAIL[13]使用的ResNet-256F和Dynamic Net[5],来评估我们的模型。ResNet-256F的细节可以参考SNAIL[13]。以ResNet-256F为嵌入模块,DN4对5-way 1-shot任务的准确率达到52.44±0.80%,对5-way 5-shot任务的准确率达到72.53±0.62%。如图所示,在骨干网较深的情况下,DN4的性能优于浅层Conv-64F。此外,当使用与嵌入模块相同的ResNet-256F时,我们的DN4(ResNet-256F)比动态网络(ResNet-256F)的性能提高了2.4%(即,70.13 ± 0.68%)在5-shot设置下(见表1)。
邻居的影响(Influence of neighbors)
在“图像到类”模块中,我们需要为查询图像的每个本地描述符在一个支持类中找到k-最近的邻居。接下来,我们测量查询图像和特定类之间的图像到类的相似性。因此,如何选择合适的超参数k是一个关键。为此,我们在minimagenet上通过改变∈{1,3,5,7}的值来执行5-way 5-shot任务,并将结果显示在表4中。可以看出,k的值对性能有轻微的影响。因此,在我们的模型中,k应该根据具体的任务来选择。
样本的影响(Influence of shots)

episodic训练机制(episodic training mechanism)是目前流行的小样本学习方法。基本规则是训练与测试的匹配条件。这意味着,在训练阶段,shot和way的值应与测试阶段一致。换言之,如果我们想执行一个5-way 1-shot任务,那么在训练阶段应该保持相同的5-way 1-shot设置。然而,在实际的训练阶段,我们仍然需要了解不匹配条件,即匹配条件下和过匹配条件下的影响。我们发现过匹配条件比匹配条件能获得更好的性能,并且比欠匹配条件要好得多。
基本上,对于欠匹配条件,我们在训练阶段使用较少的样本,反之,对于过匹配条件使用较多的样本。我们确定了way的数量,但在训练期间改变了样本的数量,以学习几种不同的模式。然后,我们在不同的shot设置下测试这些模型,其中shot的数量是变化的,但是方式的数量是固定的。使用我们的DN4在miniImageNet上执行5-way K-shot (K = 1, 2, 3, 4, 5)任务。结果见表5,其中对角线上的条目是匹配条件的结果。上三角中的结果是在匹配条件下的结果。此外,下三角形包含过度匹配条件的结果。可见,下三角的结果比上三角的好,对角线的结果比上三角的好。这正好证实了我们上面所说的。值得一提的是,如果我们使用一个5-shot训练模型,并在1-shot任务上进行测试,我们可以获得53.85%的准确率。这一结果在本课题中是相当高的,并且在匹配条件下,比用我们的DN4在1-shot训练模型得到的51.24%要好得多。
可视化(Visualization)
在miniImageNet上,我们将通过NBNN(深度局部特征)和DN4学习到的相似性矩阵可视化为5-way 5-shot设置。它们都是基于图像到类度量的模型。我们从每个类中选择20个查询图像(总共100个查询图像),计算每个查询图像与每个类之间的相似度,并可视化5×100相似度矩阵。
从图2可以看出,DN4的结果比NBNN的结果更接近实际情况,这说明端到端的方式更有效。

运行时(Runtime)
虽然NBNN在文献[1]中有成功的表现,但它并没有流行起来。一个关键的原因是最近邻搜索的计算复杂度高,特别是在大规模的图像分类任务中。幸运的是,在小样本设置下,我们的框架可以在不受计算问题影响的情况下享受NBNN的优异性能。通常,在5-way 1-shot或5-shot任务的训练期间,一集(批)(episode (batch))时间为0.31s或0.38s,在单个Nvidia GTX 1080Ti GPU和单个Intel i7-3820 CPU上有75或50个查询图像。在测试过程中,效率会更高,一episode只需要0.18秒。此外,通过优化并行实现可以进一步提高模型的效率。
5. 结论
本文对基于局部描述子的图像到类的度量方法进行了研究,提出了一种简单有效的深最近邻神经网络(DN4)用于小样本学习。我们强调并验证了可学习的深层局部描述子的重要性和价值,这些描述子比图像级特征更适合于小样本问题,并且能够很好地提高分类性能。我们还验证了由于视觉模式在类内的可交换性,图像到类度量优于图像到图像度量。
参考资料
[1] 英伟达最新图像转换神器火了!试玩开放,吸猫爱好者快来
[2] # StarGAN论文及代码理解
[3] starGAN 论文学习
论文下载
[1] Revisiting Local Descriptor based Image-to-Class Measure
for Few-shot Learning
代码
[1] # WenbinLee/DN4