前言:
昨天,在文章:终于等到你:CYQ.Data V5系列 (ORM数据层,支持.NET Core)最新版本开源了 中,
不小心看到一条留言:
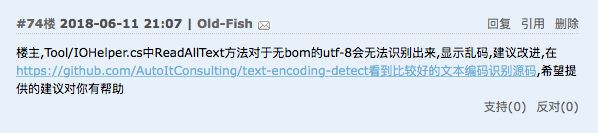
然后就去该地址看了一下,这一看,顺带折腾了一天。
今天,就和大伙分享下折腾的感觉。
在该开源地址中,代码有C++和C#两个版本,编码的整体风格倾向与于C++。
主要的时间,花了在对于检测无BOM的部分,顺带重温了各种编码的基础。
建议在看此文之前,先了解下编码、和BOM的概念。
有BOM的编码检测
对于一个文件,或者字节流,就是一堆二进制:
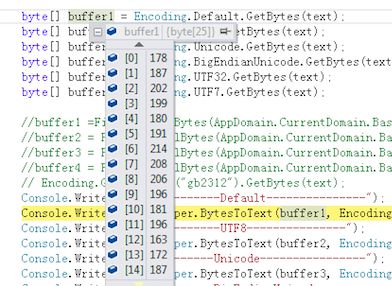
如果传输的过程,有指定BOM,就是前面两三个字节是固定的255,254之类的,那么解码起来就很简单了。
像之前IOHelper内部读文件的代码是这么写的:
////// 先自动识别UTF8,否则归到Default编码读取 /// /// public static string ReadAllText(string fileName) { return ReadAllText(fileName, DefaultEncoding); } public static string ReadAllText(string fileName, Encoding encoding) { try { if (!File.Exists(fileName)) { return string.Empty; } Byte[] buff = null; lock (GetLockObj(fileName.Length)) { if (!File.Exists(fileName))//多线程情况处理 { return string.Empty; } buff = File.ReadAllBytes(fileName); } if (buff.Length == 0) { return ""; } if (buff[0] == 239 && buff[1] == 187 && buff[2] == 191) { return Encoding.UTF8.GetString(buff, 3, buff.Length - 3); } else if (buff[0] == 255 && buff[1] == 254) { return Encoding.Unicode.GetString(buff, 2, buff.Length - 2); } else if (buff[0] == 254 && buff[1] == 255) { if (buff.Length > 3 && buff[2] == 0 && buff[3] == 0) { return Encoding.UTF32.GetString(buff, 4, buff.Length - 4); } return Encoding.BigEndianUnicode.GetString(buff, 2, buff.Length - 2); } return encoding.GetString(buff); } catch (Exception err) { Log.WriteLogToTxt(err); } return string.Empty; }
代码说白了,就是检测BOM头,然后识别编码,用对应的编码解码。
测试的结果:
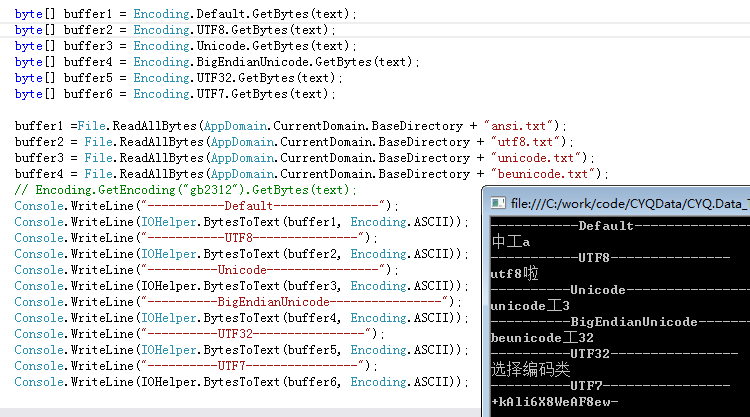
中文都能正确显示。
windows下文本的另存为只有:ANSI、UTF8、Unicode(UTF16LE)、BigEndianUnicode(UTF16BE)。
这四种有BOM的都是轻松检测了。
那如果文件或字节没有BOM头呢?如果用默认的编码,由有一定概率会乱码。
无BOM的编码检测
如果一堆字节流,没有指定BOM,就要分析出编码类型,还是挺有难度的。
这需要对各种编码的规则有一定的熟悉度。
先看看网友给出的Github上的 原始源码:
public Encoding DetectEncoding(byte[] buffer, int size)
{
// First check if we have a BOM and return that if so
Encoding encoding = CheckBom(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
// Now check for valid UTF8
encoding = CheckUtf8(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
// Now try UTF16
encoding = CheckUtf16NewlineChars(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
encoding = CheckUtf16Ascii(buffer, size);
if (encoding != Encoding.None)
{
return encoding;
}
// ANSI or None (binary) then
if (!DoesContainNulls(buffer, size))
{
return Encoding.Ansi;
}
// Found a null, return based on the preference in null_suggests_binary_
return _nullSuggestsBinary ? Encoding.None : Encoding.Ansi;
}
代码流程(和内涵)翻译下来是这样的:
1、检测BOM头,这个很Easy。 2、检测UTF8编码(这个还是很有创意的),如果编码的规则完全符合UTF8,则认为是UTF8。 3、检测字节中是否有换行符(根据换行符中的0的位置,区分是Utf16的BE大尾还是LE小尾)。 这个概率要看字节抽样的长度,带不带换行符。 4、检测字节中,单偶数出现的0的概率,设定了一个期望值来预判(对于中文而言,基本没用),大概是老外写的,只根据英文情况分析的概率。 5、检测字节中,有没有出现0,如果没有,返回系统默认编码(不同系统环境编码是不同的)。
首先,不得不说,原作者还是有一定想法的。
虽然代码中除了UTF8按规则写的分析外,其它的都无法代入中文环境里通过。
但至少思路上,就能得到不少启发。
于是,坑了我大半天,进行重写,改造,代入中文环境测试。
无BOM代码检测的改造过程:
改造后的代码流程是这样的:
public Encoding DetectWithoutBom(byte[] buffer, int size) { // Now check for valid UTF8 Encoding encoding = CheckUtf8(buffer, size); if (encoding != Encoding.None) { return encoding; } // ANSI or None (binary) then 一个零都没有情况。 if (!ContainsZero(buffer, size)) { CheckChinese(buffer, size); return Encoding.Ansi; } // Now try UTF16 按寻找换行字符先进行判断 encoding = CheckByNewLineChar(buffer, size); if (encoding != Encoding.None) { return encoding; } // 没办法了,只能按0出现的次数比率,做大体的预判 encoding = CheckByZeroNumPercent(buffer, size); if (encoding != Encoding.None) { return encoding; } // Found a null, return based on the preference in null_suggests_binary_ return Encoding.None; }
用中文解释流程是这样的:
1、UTF8编码的检测规则,这个是通用的有效,可以保留。 2、调整顺序:先检测字节有没有0字节,若无,补一个是否中文的编码的检测(GB2312、GBK、Big5)。 这个后续有点用。 3、检测换行符:增加UTF-32编码的检测(原来的思路只有UTF16)。 4、预判概率:改造成同时适应中文环境。
测试的结果是这样的:
A、纯中文的:

该测试下,对于BigEndianUnicode的会产生乱码。
B、非纯中文的
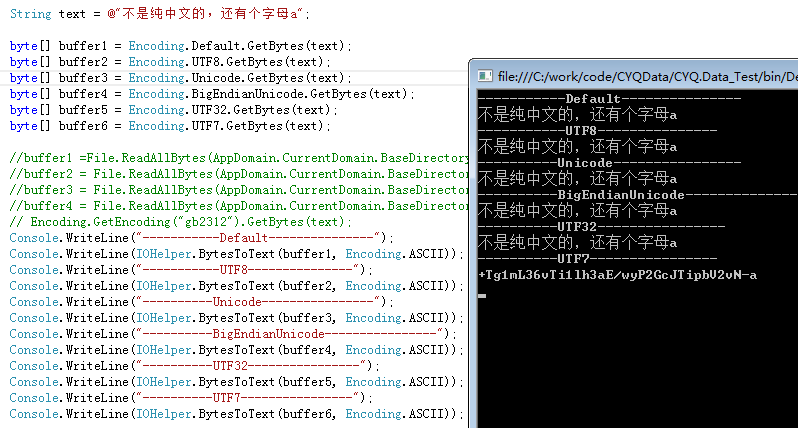
一切编码正常通用。
改进后的完整源码:
using System; using System.Collections.Generic; using System.IO; using System.Text; namespace CYQ.Data.Tool { internal static class IOHelper { internal static Encoding DefaultEncoding = Encoding.Default; private static List<object> tenObj = new List<object>(10); private static List<object> TenObj { get { if (tenObj.Count == 0) { for (int i = 0; i < 10; i++) { tenObj.Add(new object()); } } return tenObj; } } private static object GetLockObj(int length) { int i = length % 9; return TenObj[i]; } ////// 先自动识别UTF8,否则归到Default编码读取 /// /// public static string ReadAllText(string fileName) { return ReadAllText(fileName, DefaultEncoding); } public static string ReadAllText(string fileName, Encoding encoding) { try { if (!File.Exists(fileName)) { return string.Empty; } Byte[] buff = null; lock (GetLockObj(fileName.Length)) { if (!File.Exists(fileName))//多线程情况处理 { return string.Empty; } buff = File.ReadAllBytes(fileName); return BytesToText(buff, encoding); } } catch (Exception err) { Log.WriteLogToTxt(err); } return string.Empty; } public static bool Write(string fileName, string text) { return Save(fileName, text, false, DefaultEncoding, true); } public static bool Write(string fileName, string text, Encoding encode) { return Save(fileName, text, false, encode, true); } public static bool Append(string fileName, string text) { return Save(fileName, text, true, true); } internal static bool Save(string fileName, string text, bool isAppend, bool writeLogOnError) { return Save(fileName, text, true, DefaultEncoding, writeLogOnError); } internal static bool Save(string fileName, string text, bool isAppend, Encoding encode, bool writeLogOnError) { try { string folder = Path.GetDirectoryName(fileName); if (!Directory.Exists(folder)) { Directory.CreateDirectory(folder); } lock (GetLockObj(fileName.Length)) { using (StreamWriter writer = new StreamWriter(fileName, isAppend, encode)) { writer.Write(text); } } return true; } catch (Exception err) { if (writeLogOnError) { Log.WriteLogToTxt(err); } else { Error.Throw("IOHelper.Save() : " + err.Message); } } return false; } internal static bool Delete(string fileName) { try { if (File.Exists(fileName)) { lock (GetLockObj(fileName.Length)) { if (File.Exists(fileName)) { File.Delete(fileName); return true; } } } } catch { } return false; } public static bool IsLastFileWriteTimeChanged(string fileName, ref DateTime compareTimeUtc) { bool isChanged = false; IOInfo info = new IOInfo(fileName); if (info.Exists && info.LastWriteTimeUtc != compareTimeUtc) { isChanged = true; compareTimeUtc = info.LastWriteTimeUtc; } return isChanged; } public static string BytesToText(byte[] buff, Encoding encoding) { if (buff.Length == 0) { return ""; } //if (buff[0] == 239 && buff[1] == 187 && buff[2] == 191) //{ // return Encoding.UTF8.GetString(buff, 3, buff.Length - 3); //} //else if (buff[0] == 255 && buff[1] == 254) //{ // return Encoding.Unicode.GetString(buff, 2, buff.Length - 2); //} //else if (buff[0] == 254 && buff[1] == 255) //{ // if (buff.Length > 3 && buff[2] == 0 && buff[3] == 0) // { // return Encoding.UTF32.GetString(buff, 4, buff.Length - 4); // } // return Encoding.BigEndianUnicode.GetString(buff, 2, buff.Length - 2); //} //else //{ TextEncodingDetect detect = new TextEncodingDetect(); //检测Bom switch (detect.DetectWithBom(buff)) { case TextEncodingDetect.Encoding.Utf8Bom: return Encoding.UTF8.GetString(buff, 3, buff.Length - 3); case TextEncodingDetect.Encoding.UnicodeBom: return Encoding.Unicode.GetString(buff, 2, buff.Length - 2); case TextEncodingDetect.Encoding.BigEndianUnicodeBom: return Encoding.BigEndianUnicode.GetString(buff, 2, buff.Length - 2); case TextEncodingDetect.Encoding.Utf32Bom: return Encoding.UTF32.GetString(buff, 4, buff.Length - 4); } if (encoding != DefaultEncoding && encoding != Encoding.ASCII)//自定义设置编码,优先处理。 { return encoding.GetString(buff); } switch (detect.DetectWithoutBom(buff, buff.Length > 1000 ? 1000 : buff.Length))//自动检测。 { case TextEncodingDetect.Encoding.Utf8Nobom: return Encoding.UTF8.GetString(buff); case TextEncodingDetect.Encoding.UnicodeNoBom: return Encoding.Unicode.GetString(buff); case TextEncodingDetect.Encoding.BigEndianUnicodeNoBom: return Encoding.BigEndianUnicode.GetString(buff); case TextEncodingDetect.Encoding.Utf32NoBom: return Encoding.UTF32.GetString(buff); case TextEncodingDetect.Encoding.Ansi: if (IsChineseEncoding(DefaultEncoding) && !IsChineseEncoding(encoding)) { if (detect.IsChinese) { return Encoding.GetEncoding("gbk").GetString(buff); } else//非中文时,默认选一个。 { return Encoding.Unicode.GetString(buff); } } else { return encoding.GetString(buff); } case TextEncodingDetect.Encoding.Ascii: return Encoding.ASCII.GetString(buff); default: return encoding.GetString(buff); } // } } private static bool IsChineseEncoding(Encoding encoding) { return encoding == Encoding.GetEncoding("gb2312") || encoding == Encoding.GetEncoding("gbk") || encoding == Encoding.GetEncoding("big5"); } } internal class IOInfo : FileSystemInfo { public IOInfo(string fileName) { base.FullPath = fileName; } public override void Delete() { } public override bool Exists { get { return File.Exists(base.FullPath); } } public override string Name { get { return null; } } } /// /// 字节文本编码检测 /// internal class TextEncodingDetect { private readonly byte[] _UTF8Bom = { 0xEF, 0xBB, 0xBF }; //utf16le _UnicodeBom private readonly byte[] _UTF16LeBom = { 0xFF, 0xFE }; //utf16be _BigUnicodeBom private readonly byte[] _UTF16BeBom = { 0xFE, 0xFF }; //utf-32le private readonly byte[] _UTF32LeBom = { 0xFF, 0xFE, 0x00, 0x00 }; //utf-32Be //private readonly byte[] _UTF32BeBom = //{ // 0x00, // 0x00, // 0xFE, // 0xFF //}; /// /// 是否中文 /// public bool IsChinese = false; public enum Encoding { None, // Unknown or binary Ansi, // 0-255 Ascii, // 0-127 Utf8Bom, // UTF8 with BOM Utf8Nobom, // UTF8 without BOM UnicodeBom, // UTF16 LE with BOM UnicodeNoBom, // UTF16 LE without BOM BigEndianUnicodeBom, // UTF16-BE with BOM BigEndianUnicodeNoBom, // UTF16-BE without BOM Utf32Bom,//UTF-32LE with BOM Utf32NoBom //UTF-32 without BOM } public Encoding DetectWithBom(byte[] buffer) { if (buffer != null) { int size = buffer.Length; // Check for BOM if (size >= 2 && buffer[0] == _UTF16LeBom[0] && buffer[1] == _UTF16LeBom[1]) { return Encoding.UnicodeBom; } if (size >= 2 && buffer[0] == _UTF16BeBom[0] && buffer[1] == _UTF16BeBom[1]) { if (size >= 4 && buffer[2] == _UTF32LeBom[2] && buffer[3] == _UTF32LeBom[3]) { return Encoding.Utf32Bom; } return Encoding.BigEndianUnicodeBom; } if (size >= 3 && buffer[0] == _UTF8Bom[0] && buffer[1] == _UTF8Bom[1] && buffer[2] == _UTF8Bom[2]) { return Encoding.Utf8Bom; } } return Encoding.None; } /// /// Automatically detects the Encoding type of a given byte buffer. /// /// The byte buffer. /// The size of the byte buffer. /// The Encoding type or Encoding.None if unknown. public Encoding DetectWithoutBom(byte[] buffer, int size) { // Now check for valid UTF8 Encoding encoding = CheckUtf8(buffer, size); if (encoding != Encoding.None) { return encoding; } // ANSI or None (binary) then 一个零都没有情况。 if (!ContainsZero(buffer, size)) { CheckChinese(buffer, size); return Encoding.Ansi; } // Now try UTF16 按寻找换行字符先进行判断 encoding = CheckByNewLineChar(buffer, size); if (encoding != Encoding.None) { return encoding; } // 没办法了,只能按0出现的次数比率,做大体的预判 encoding = CheckByZeroNumPercent(buffer, size); if (encoding != Encoding.None) { return encoding; } // Found a null, return based on the preference in null_suggests_binary_ return Encoding.None; } /// /// Checks if a buffer contains text that looks like utf16 by scanning for /// newline chars that would be present even in non-english text. /// 以检测换行符标识来判断。 /// /// The byte buffer. /// The size of the byte buffer. /// Encoding.none, Encoding.Utf16LeNoBom or Encoding.Utf16BeNoBom. private static Encoding CheckByNewLineChar(byte[] buffer, int size) { if (size < 2) { return Encoding.None; } // Reduce size by 1 so we don't need to worry about bounds checking for pairs of bytes size--; int le16 = 0; int be16 = 0; int le32 = 0;//检测是否utf32le。 int zeroCount = 0;//utf32le 每4位后面多数是0 uint pos = 0; while (pos < size) { byte ch1 = buffer[pos++]; byte ch2 = buffer[pos++]; if (ch1 == 0) { if (ch2 == 0x0a || ch2 == 0x0d)//\r \t 换行检测。 { ++be16; } } if (ch2 == 0) { zeroCount++; if (ch1 == 0x0a || ch1 == 0x0d) { ++le16; if (pos + 1 <= size && buffer[pos] == 0 && buffer[pos + 1] == 0) { ++le32; } } } // If we are getting both LE and BE control chars then this file is not utf16 if (le16 > 0 && be16 > 0) { return Encoding.None; } } if (le16 > 0) { if (le16 == le32 && buffer.Length % 4 == 0) { return Encoding.Utf32NoBom; } return Encoding.UnicodeNoBom; } else if (be16 > 0) { return Encoding.BigEndianUnicodeNoBom; } else if (buffer.Length % 4 == 0 && zeroCount >= buffer.Length / 4) { return Encoding.Utf32NoBom; } return Encoding.None; } /// /// Checks if a buffer contains any nulls. Used to check for binary vs text data. /// /// The byte buffer. /// The size of the byte buffer. private static bool ContainsZero(byte[] buffer, int size) { uint pos = 0; while (pos < size) { if (buffer[pos++] == 0) { return true; } } return false; } /// /// Checks if a buffer contains text that looks like utf16. This is done based /// on the use of nulls which in ASCII/script like text can be useful to identify. /// 按照一定的空0数的概率来预测。 /// /// The byte buffer. /// The size of the byte buffer. /// Encoding.none, Encoding.Utf16LeNoBom or Encoding.Utf16BeNoBom. private Encoding CheckByZeroNumPercent(byte[] buffer, int size) { //单数 int oddZeroCount = 0; //双数 int evenZeroCount = 0; // Get even nulls uint pos = 0; while (pos < size) { if (buffer[pos] == 0) { evenZeroCount++; } pos += 2; } // Get odd nulls pos = 1; while (pos < size) { if (buffer[pos] == 0) { oddZeroCount++; } pos += 2; } double evenZeroPercent = evenZeroCount * 2.0 / size; double oddZeroPercent = oddZeroCount * 2.0 / size; // Lots of odd nulls, low number of even nulls 这里的条件做了修改 if (evenZeroPercent < 0.1 && oddZeroPercent > 0) { return Encoding.UnicodeNoBom; } // Lots of even nulls, low number of odd nulls 这里的条件也做了修改 if (oddZeroPercent < 0.1 && evenZeroPercent > 0) { return Encoding.BigEndianUnicodeNoBom; } // Don't know return Encoding.None; } /// /// Checks if a buffer contains valid utf8. /// 以UTF8 的字节范围来检测。 /// /// The byte buffer. /// The size of the byte buffer. /// /// Encoding type of Encoding.None (invalid UTF8), Encoding.Utf8NoBom (valid utf8 multibyte strings) or /// Encoding.ASCII (data in 0.127 range). /// /// 2 private Encoding CheckUtf8(byte[] buffer, int size) { // UTF8 Valid sequences // 0xxxxxxx ASCII // 110xxxxx 10xxxxxx 2-byte // 1110xxxx 10xxxxxx 10xxxxxx 3-byte // 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 4-byte // // Width in UTF8 // Decimal Width // 0-127 1 byte // 194-223 2 bytes // 224-239 3 bytes // 240-244 4 bytes // // Subsequent chars are in the range 128-191 bool onlySawAsciiRange = true; uint pos = 0; while (pos < size) { byte ch = buffer[pos++]; if (ch == 0) { return Encoding.None; } int moreChars; if (ch <= 127) { // 1 byte moreChars = 0; } else if (ch >= 194 && ch <= 223) { // 2 Byte moreChars = 1; } else if (ch >= 224 && ch <= 239) { // 3 Byte moreChars = 2; } else if (ch >= 240 && ch <= 244) { // 4 Byte moreChars = 3; } else { return Encoding.None; // Not utf8 } // Check secondary chars are in range if we are expecting any while (moreChars > 0 && pos < size) { onlySawAsciiRange = false; // Seen non-ascii chars now ch = buffer[pos++]; if (ch < 128 || ch > 191) { return Encoding.None; // Not utf8 } --moreChars; } } // If we get to here then only valid UTF-8 sequences have been processed // If we only saw chars in the range 0-127 then we can't assume UTF8 (the caller will need to decide) return onlySawAsciiRange ? Encoding.Ascii : Encoding.Utf8Nobom; } /// /// 是否中文编码(GB2312、GBK、Big5) /// private void CheckChinese(byte[] buffer, int size) { IsChinese = false; if (size < 2) { return; } // Reduce size by 1 so we don't need to worry about bounds checking for pairs of bytes size--; uint pos = 0; bool isCN = false; while (pos < size) { //GB2312 //0xB0-0xF7(176-247) //0xA0-0xFE(160-254) //GBK //0x81-0xFE(129-254) //0x40-0xFE(64-254) //Big5 //0x81-0xFE(129-255) //0x40-0x7E(64-126) OR 0xA1-0xFE(161-254) byte ch1 = buffer[pos++]; byte ch2 = buffer[pos++]; isCN = (ch1 >= 176 && ch1 <= 247 && ch2 >= 160 && ch2 <= 254) || (ch1 >= 129 && ch1 <= 254 && ch2 >= 64 && ch2 <= 254) || (ch1 >= 129 && ((ch2 >= 64 && ch2 <= 126) || (ch2 >= 161 && ch2 <= 254))); if (!isCN) { return; } } IsChinese = true; } } }
后续更新地址:https://github.com/cyq1162/cyqdata/blob/master/Tool/IOHelper.cs
总结:
1、考虑到UTF7已经过时了,所以直接无视了。
2、对于纯中文情况,UTF16下是BE还是LE,暂时没有想到好的检测方法,所以默认返回了常用的LE,即Unicode。
3、其它一切都安好,全国公开的C#版本,应该就此一份了。