上次已经讲了怎么下载数据,这次就不说废话了,直接开始。首先导入相应的模块,然后检视一下数据情况。对数据有一个大致的了解之后,开始进行下一步操作。
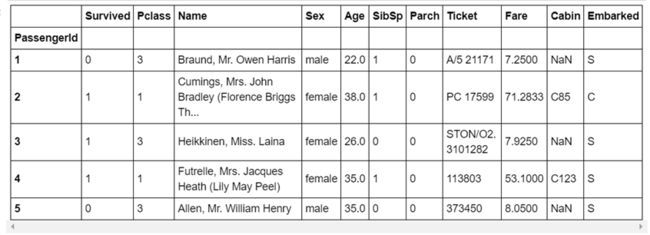
一、分析数据
1、Survived 的情况
train_data['Survived'].value_counts()

2、Pclass 和 Survived 之间的关系
train_data.groupby('Pclass')['Survived'].mean()

3、Embarked 和 Survived 之间的关系
train_data.groupby('Embarked')['Survived'].value_counts() sns.countplot('Embarked',hue='Survived',data=train_data)

二、特征处理
先将 label 提取出来,然后将 train 和 test 合并起来一起处理。
y_train = train_data.pop('Survived').astype(str).values data = pd.concat((train_data, test_data), axis=0)
1、对 numerical 数据进行处理
(1)SibSp/Parch (兄弟姐妹配偶数 / 父母孩子数)
由于这两个属性都和 Survived 没有很大的影响,将这两个属性的值相加,表示为家属个数。
data['FamilyNum'] = data['SibSp'] + data['Parch']
(2)Fare (费用)
它有一个缺失值,需要将其补充。(这里是参考别人的,大神总能发现一些潜在的信息:票价和 Pclass 和 Embarked 有关) 因此,先看一下他们之间的关系以及缺失值的情况。
train_data.groupby(by=["Pclass","Embarked"]).Fare.mean()

缺失值 Pclass = 3, Embarked = S,因此我们将其置为14.644083.
data["Fare"].fillna(14.644083,inplace=True)
还有 Age 的缺失值也需要处理,我是直接将其设置为平均值。
2、对 categorical 数据进行处理
(1)对 Cabin 进行处理
Cabin虽然有很多空值,但他的值的开头都是字母,按我自己的理解应该是对应船舱的位置,所以取首字母。考虑到船舱位置对救生是有一定影响的,虽然有很多缺失值,但还是把它保留下来,而且由于 T 开头的只有一条数据,因此将它设置成数量较小的 G。
data['Cabin'] = data['Cabin'].str[0] data['Cabin'][data['Cabin']=='T'] = 'G'
(2)对 Ticket 进行处理
将 Ticket 的头部取出来当成新列。
data['Ticket_Letter'] = data['Ticket'].str.split().str[0] data['Ticket_Letter'] = data['Ticket_Letter'].apply(lambda x:np.nan if x.isnumeric() else x) data.drop('Ticket',inplace=True,axis=1)
(3)对 Name 进行处理
名字这个东西,虽然它里面的称呼可能包含了一些身份信息,但我还是打算把这一列给删掉...
data.drop('Name',inplace=True,axis=1)
(4)统一将 categorical 数据进行 One-Hot
One-Hot 大致的意思在之前的文章讲过了,这里也不再赘述。
data['Pclass'] = data['Pclass'].astype(str) data['FamilyNum'] = data['FamilyNum'].astype(str) dummied_data = pd.get_dummies(data)
(5)数据处理完毕,将训练集和测试集分开
X_train = dummied_data.loc[train_data.index].values
X_test = dummied_data.loc[test_data.index].values
三、构建模型
这里用到了 sklearn.model_selection 的 GridSearchCV,我主要用它来调参以及评定 score。
1、XGBoost
xgbc = XGBClassifier() params = {'n_estimators': [100,110,120,130,140], 'max_depth':[5,6,7,8,9]} clf = GridSearchCV(xgbc, params, cv=5, n_jobs=-1) clf.fit(X_train, y_train) print(clf.best_params_) print(clf.best_score_)
{'max_depth': 6, 'n_estimators': 130}
0.835016835016835
2、Random Forest
rf = RandomForestClassifier() params = { 'n_estimators': [100,110,120,130,140,150], 'max_depth': [5,6,7,8,9,10], } clf = GridSearchCV(rf, params, cv=5, n_jobs=-1) clf.fit(X_train, y_train) print(clf.best_params_) print(clf.best_score_)
{'max_depth': 8, 'n_estimators': 110}
0.8294051627384961
四、模型融合
from sklearn.ensemble import VotingClassifier xgbc = XGBClassifier(n_estimators=130, max_depth=6) rf = RandomForestClassifier(n_estimators=110, max_depth=8) vc = VotingClassifier(estimators=[('rf', rf),('xgb',xgbc)], voting='hard') vc.fit(X_train, y_train)
准备就绪,预测并保存模型与结果
y_test = vc.predict(X_test) # 保存模型 from sklearn.externals import joblib joblib.dump(vc, 'vc.pkl') submit = pd.DataFrame(data= {'PassengerId' : test_data.index, 'Survived': y_test}) submit.to_csv('./input/submit.csv', index=False)
最后提交即可,提交的方式也在上一篇提到过了。Over~ 项目地址:Titanic
想要第一时间获取更多有意思的推文,可关注公众号: Max的日常操作
