前言介绍:
1.数据分析初识
数据分析是21世纪的石油 数据分析的过程: 1. 提出需求 2.数据的来源 a.公司内部的数据 b.买数据或爬虫爬取数据 3.数据分析用的编辑器: numpy/pandas 4.数据的展示:matplotlib 》》》数据量大的时候我们就用hadoop/spark等
一.安装ipython
命令:pip install ipython 》》》之前我们是一直用的python cmd 命令 实在是有点low 对于新手用户没有提示不是很友好
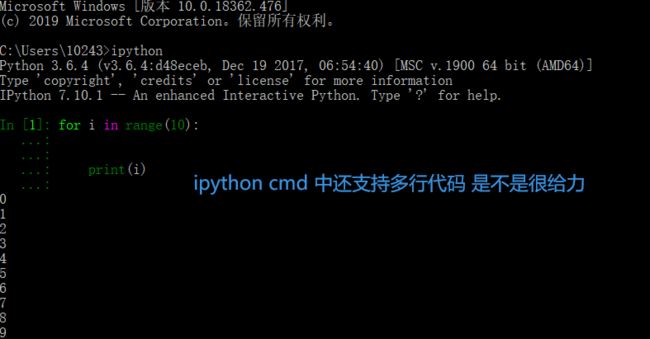
所以测试的话我还是推荐用我们ipython
2.安装jupyter noptebook
两种安装和启动方式
(1)命令行安装:pip install jupyter
启动:cmd直接输入 >>>jupyter notebook

直接会跳转到我们的 http://localhost:8888/tree#notebooks 也就是我们上面的iP+port
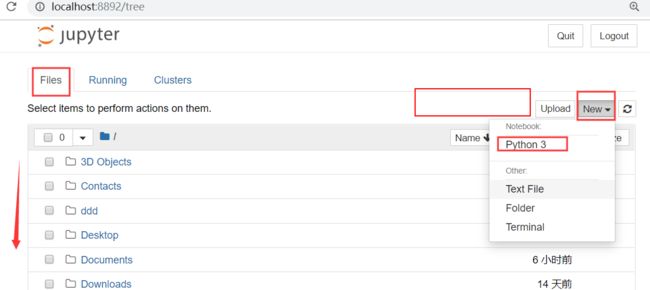
执行代码 我们选择的是python 所以执行时要遵循python 语法
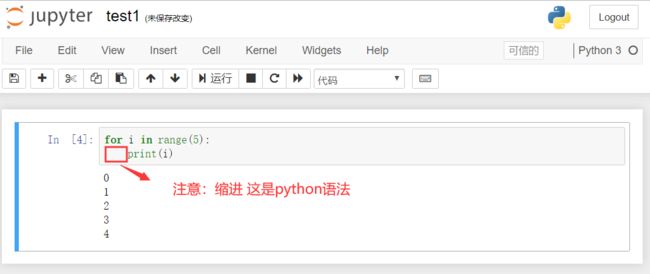
缺点:
必须后动安装数据分析包
3.接受anaconda 软件
(1)优点:包含了数据分析的基础包 大概200 个包左右的科学运算包,上面的我们会在接下来 做一个重点的介绍
(2)安装anaconda:https://www.anaconda.com/
简单的步奏:



4.anaconda 中的jupyter notebook 的快捷方式
(1)快捷键
# 快捷键 ## 1 运行当前代码并选中下一个单元格 shift+enter # 绿色:表示编辑模式 # 蓝色:按ESC表示表示命令行 #接下来按a(above) >>> 上方添加一个单元格 # 接下来按b(below) >>> 下方添加一个单元格 # 删除单元格 还是在esc 下按 dd(delete) # 2.仅仅只运行当前的代码 crl+enter # 3.# 代码和markdown的切换。esc 接下来按m # 切换到我们的markdown# : 一级标题## : 二级标题### : 三级标题###
5.numpy 的数据分析
(1)numpy的优势
#### 有一个购物车, 购物车中有商品的数量和对应的价格, 求总的价格
### 1.numpy的使用
import numpy as np shop_price=[20,30,40] goods_num = [1,2,3] shop_price_np = np.array(shop_price) goods_num_np = np.array(goods_num) res = shop_price_np*goods_num_np # 向量操作 完成两个列表中的城积之和 res.sum() ### 1.numpy的使用
import numpy as np shop_price=[20,30,40] goods_num = [1,2,3] shop_price_np = np.array(shop_price) goods_num_np = np.array(goods_num) res = shop_price_np*goods_num_np # 向量操作 完成两个列表中的城积之和 res.sum() 200 list1 = np.array([1,2,3,4,5]) list1*3 array([ 3, 6, 9, 12, 15]) 2. # 2.[1,2,3]* 3 》》》 结果应该是我们的][[[]]] list1 = np.array([1,2,3,4,5]) list1*3 # 没有返回值 array([ 3, 6, 9, 12, 15]) # 3. nparray 二维数组 res = np.array([1,2,3,4], [5,6,7,8]) res
# 3. nparray 二维数组 res = np.array([1,2,3,4], [5,6,7,8]) res --------------------------------------------------------------------------- TypeError Traceback (most recent call last)in 1 # 3. nparray 二维数组 2 res = np.array([1,2,3,4], ----> 3 [5,6,7,8]) 4 res TypeError: data type not understood --------------------------------------------------------------------------- TypeError Traceback (most recent call last) in 1 # 3. nparray 二维数组 ----> 2 res = np.array([1,2,3,4],[5,6,7,8]) 3 res TypeError: data type not understood res = np.array([[1,2,3,4],[5,6,7,8]])
# 3. nparray 二维数组 res = np.array([[1,2,3,4],[5,6,7,8]]) res array([[1, 2, 3, 4], [5, 6, 7, 8]]) 类似于
# 4.数组的转置 (对高唯数组而言) res.T 》》》 进行转换 res = np.array([[1,2,3,4],[5,6,7,8]]) res.T # 类似于zip 函数 array([[1, 5], [2, 6], [3, 7], [4, 8]]) res.dtype
# 5.元素的类型 res.dtype dtype('int32') # 6数组元素的个数 res.size # >>> 指的是所有元素的个数 8 # 7.数组的维度 空间维度 指的是我们最初的res数据的行数 res.ndim 2 2行 4列
# 8。以元祖的形式展示数组的维度 res.shape # res 为2行 4列 (2, 4)
###ndarray的创建
6.ndarray()
# ndarray-创建 这个是多维数组 # 2.linspace() np.linspace(1,10,20) # 需要通过我们numpy as np 的对象进行点linspace() >>>> 1 起点 10 终点 等分20份 》》》支持浮点数 array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684, 3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789, 5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895, 8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ]) # 3.zeros np.zeros((3,4)) # 会生成一个以零为对象的三行 4列的 多维数组对象 array([[0., 0., 0., 0.], [0., 0., 0., 0.], [0., 0., 0., 0.]]) t # 4.empty() np.empty(10) # 这个方法只申请内存,不给它赋值 array([6.95185110e-310, 1.18924533e-311, 1.18924534e-311, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000]) np.empty(10) np.empty(10) array([6.95185110e-310, 1.18924533e-311, 1.18924534e-311, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000]) np.empty(20) np.empty(20) array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684, 3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789, 5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895, 8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ]) np.empty(10) np.empty(10) array([6.95185110e-310, 1.18924533e-311, 1.18924534e-311, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000, 0.00000000e+000]) np.empty(20) array([ 1. , 1.47368421, 1.94736842, 2.42105263, 2.89473684, 3.36842105, 3.84210526, 4.31578947, 4.78947368, 5.26315789, 5.73684211, 6.21052632, 6.68421053, 7.15789474, 7.63157895, 8.10526316, 8.57894737, 9.05263158, 9.52631579, 10. ]) # # array() l = [1,2,3] l2 = np.array(l) l2.dtype? # # shift+enter 进入文档 列子 # ones() np.ones((3,5)) # 注意内部套的是元祖 全部以1为准 3行 5列的多维数组 array([[1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.], [1., 1., 1., 1., 1.]]) 创建单位矩阵 # eye() np.eye(5) # 根据指定边长和dtype创建单位矩阵 array([[1., 0., 0., 0., 0.], [0., 1., 0., 0., 0.], [0., 0., 1., 0., 0.], [0., 0., 0., 1., 0.], [0., 0., 0., 0., 1.]])
7.索引和切片
1.数组和标量之间的运算
# li = [[1,2,3], [4,5,6]] a = np.array(li) # 通过array()组列生成对象 a*2 array([[ 2, 4, 6], [ 8, 10, 12]])
# 2. 同样大小数据间的运算 >>>>多维空间的运算
l2 = [[3,3,4],
[5,6,9]]
l3 = [[4,4,6],
[1,2,3]]
# a = np.array() # 将多维数组传入转为array()多维数组对象
a = np.array(l2)
b = np.array(l3)
a+b
2。索引
(1)
# 将一维变二维 一个列表套一个列表 就是二维 arr = np.arange(30).reshape(5,6) # 后面的参数6可以改为-1, 相当于占位符,系统可以自动帮忙算几列 arr array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29]]) 对象 # 二维变一维 一维 就是一个数组 array()对象 arr.reshape(30) array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29])
(2)需求现有一组数据,需求:找到20
列表写法:arr[3,2]
# arr[r3,2] arr[3,2] 20 arr[3][2] 20 arr[0,4] arr[0,4] 4
(3)切片
array([[ 7, 8, 9], [13, 14, 15], [19, 20, 21]])
切片和bool 值的补充
nunmpy进阶¶ 1.numpy 的常用属性有哪些?T dtype ndim size shape》》》 数组的维度大小 一元祖的形式 2.生成ndarray的类对象的几种常用的创建方法 array(将列表转为数组 可以选择显示dtype) arange(对象支持浮点数) linspace(其实是类似与我们range) zeros(生成0的数组)) empty(数组随机值) np.eye(5):数组行 列都是5 的矩阵 . import numpy as np import pandas as pd # 1.切片 a = np.arange(30).reshape(5,6) a array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29]]) a[1:4,1:3] array([[ 7, 8], [13, 14], [19, 20]]) 是一个范围 # 1:4 >>> 从索引1 这一行 切 到4 我们得到1,2,3 行数据 那么再看列1开始 切3列 不含三 # 行的结果+列的结果 就是上面的 是一个范围 arr # 单切是非常好理解的 arr = np.arange(10) arr array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) a # 单切和我们的索引是切片一模一 顾头不顾尾 5,6,7 a = arr[5:8] a array([5, 6, 7]) # 布尔类型索引取值 >>> 现在有这样的数组 选出数组中所有大于5的数 按照之前的列变操作我们 # 需要进行for 在判断aarr >5 >list1.apppend(arr) 太麻烦了 import random li = [random.randint(1,10) for i in range(15)] # res = li>5 错 要将列变 转换成ndarray 类对象 现在我们需要数组 用array() 方法 res = np.array(li) res>5 array([ True, True, False, True, True, True, True, False, True, True, False, False, False, True, False]) # 上面的bool值类型 转换位数值 res[res>5] # 类似对象list(reduce|map|zip) array([ 9, 9, 10, 9, 6, 9, 9, 9, 7])
花式索引:
# 花式索引 c = np.arange(1,13) # 需求 获取[2,4,,6,12] c[[1,3,7,11]] # # 花式索引 c = np.arange(1,13) # 需求 获取[2,4,,6,12] c[[1,3,7,11]] # array([ 2, 4, 8, 12])
三.numpy的通用函数
能对所有数组中的元素同时进行运算的函数就是通用函数
常见的通用函数:
(1)能接受一个数组叫做一元函数,接受两个数组的就是二元函数 结果返回的也是一个数组
- 一元函数:
| 函数 | 功能 | |
|---|---|---|
| abs、fabs | 分别是计算整数和浮点数的绝对值 | |
| sqrt | 计算各元素的平方根 | |
| square | 计算各元素的平方 | |
| exp | 计算各元素的指数e**x | |
| log | 计算自然对数 | |
| sign | 计算各元素的正负号 | |
| ceil | 计算各元素的ceiling值 向上取整 | |
| floor | 计算各元素floor值,即小于等于该值的最大整数 | |
| rint | 计算各元素的值四舍五入到最接近的整数,保留dtype 向下取整 | |
| modf | 将数组的小数部分和整数部分以两个独立数组的形式返回,与Python的divmod方法类似 | |
| isnan | 计算各元素的正负号 | |
| isinf | 表示那些元素是无穷的布尔型数组 | |
| cos,sin,tan | 普通型和双曲型三角函数 |
-
用法实列:
# abs(取绝对值) 和 fabs(浮点取绝对值) # np.abs(-10) np.abs([-2,-5,10]) # 也可以进行列表的整体取绝对值 array([ 2, 5, 10]) 列表 # np.fabs(-0.98) # 取浮点数的绝对值 np.fabs([1,89,-3.45,-10]) # 列表 array([ 1. , 89. , 3.45, 10. ]) # 平方根sqrt 开根号 np.sqrt(4) 2.0 np.square(4) # 平方 16 e**3 # exp() 计算个元素的指数e**3 np.e**3 20.085536923187664 # log() 自然数对数 np.log(2) 0.6931471805599453 # ceil 向上取整数 np.ceil(3.0000000001) 4.0 向下取整 # rfoor 向下取整 np.floor(4.99999) 4.0 # rint 四舍⑤略 np.rint(4.599999) 5.0 # nodf # 将小数部分和整数部分以独立数组的形式返回 np.modf(4.55) # nodf # 将小数部分和整数部分以独立数组的形式返回 np.modf(4.55) (0.5499999999999998, 4.0)
- 二元函数:
| 函数 | 功能 | |
|---|---|---|
| add | 将数组中对应的元素相加 | |
| subtract | 从第一个数组中减去第二个数组中的元素 | |
| multiply | 数组元素相乘 | |
| divide、floor_divide | 除法或向下圆整除法(舍弃余数) | |
| power | 对第一个数组中的元素A,根据第二个数组中的相应元素B计算A**B | |
| maximum,fmax | 计算最大值,fmax忽略NAN | |
| miximum,fmix | 计算最小值,fmin忽略NAN | |
| mod | 元素的求模计算(除法的余数) |
3.1 数学统计方法
# 3.1 统计方法 sum 求和 np.sum([2,3,4,45,5]) 59 np.cumsum? # cumsunm 求前缀和 np.cumsum? a = np.array([[1,2,3,4],[5,6,7,10]]) a a array([[ 1, 2, 3, 4], [ 5, 6, 7, 10]]) 位1+2,第三位3+3 np.cumsum(a) # 从0开始 一直往后加 0+1第一位,第二位1+2,第三位3+3 array([ 1, 3, 6, 10, 15, 21, 28, 38], dtype=int32) ]) # mean 求平均值r np.mean([1,2,3]) 2.0
3.2 随记数
随记生成一个0-1的数 np.random.rand() # 随记生成一个0-1的数 0.21909839531953224 整数 np.random.randint(1,9) # 随记生成一个1-9之间的整数 7 np.random.choice(5,6) # 在0-6 之间 随记生成5个数 array([1, 0, 2, 4, 1, 3]) 生成20个数 np.random.uniform(-1,10,20) # 在-1 到10 生成20个数 array([ 8.45356587, 1.29215679, 2.2847261 , 0.29622908, 6.66320791, 5.5950294 , 8.51121032, 8.62642454, 4.38174021, 3.86368799, 1.62436614, 4.46825402, 6.72249389, 6.50778638, 8.70313494, 2.56322355, 7.5230334 , 2.1484058 , 1.95718723, -0.65909369])

再见!!!!!!