写在前面:在初学nlp时的第一个任务——NER,尝试了几种方法,cnn+crf、lstm+crf、bert+lstm+crf,毫无疑问,最后结果时Bert下效果最好。
1、关于NER:
NER即命名实体识别是信息提取的一个子任务,但究其本质就是序列标注任务。
eg:
sentence:壹 叁 去 参加一个 NER 交 流 会
tag: B_PER I_PER O O O O O B_ORG I_ORG I_ORG I_ORG
(咱们暂且认为这个实体标记是正确的)
按照CoNLL2003任务中,LOC-地名、PER-人名、ORG-机构名、MISC-其他实体,其他此被标记为O,B代表实体名的开始位置,I代表实体名的中间位置。(在具体任务中标记不一,按照自己的任务中进行标记即可)
NER是一个基础问题,不会不行,但是也是一个非常重要的问题,下面将按照实现过程中碰到的问题依次进行阐述(小白,如有错误,请疯狂留言喷我,一定改正)。首先的明白NER是一个分类任务,也叫序列标注,其实就是对文本的不同实体标记上对应的标签。
方法主要如下:
- 基于规则:按照语义学的先验定义规则,由于语言的复杂性,这个方法很难制定出良好的规则;
- 基于统计学:统计学就是根据大量文本,在其中找到规律,代表作有HMM、CRF;
- 神经网络:神经网络的大放异彩在各个领域都点亮了一片天空,当然不会遗忘,其中在NER方面主要有CNN+CRF、LSTM+CRF。
2、老婆孩子热炕头
-
分词
分词工具主要采用了jieba分词,在结巴原始词库的基础上加载自定义词典,方法参考参考
import jieba
jieba.load_userdict('..\data\\result_SVM_to_jiaba.txt')
import jieba.posseg as pseg
jieba支持三种分词模式:
- 精准模式:试图将句子最精确的切分,适合文本分析;
- 全模式:把句子中所有的词都扫描出来,速度快,但是不支持歧义;
- 搜索引擎模式:在精准模式的基础上,在对长词进行切分,提高召回率,适用于搜索引擎分词。
jieba对中文的支持还是很好的,当然现在还有很多中文方面的工具:jiagu、等等。
2.实体标记
假设我们的任务是从0开始的,没有开源数据集,在做的时候先对实体词进行摘取(eg:python开发工程师、全栈开发等等),作为自己的实体词库,并加载到jieba中进行分词库中,对数据进行分词,分词后按照我们抽取的实体词进行标记(eg:B_PER\I_PER\B_LOC\I_LOC...)。在这儿我们已经有了NER的老婆(标记好的数据)。
3.一号儿子(CNN+CRF) [paper]
论文名字:Convolutional Neural Network Based Semantic Tagging with Entity Embeddings
- 词嵌入:Word2Vec
Word2Vec是一种有效的神经网络模型,该模型采用非结构化的文本并学习每个单词的嵌入特性,这些嵌入特性捕获了语法和语义的不同关系,有趣的是可以进行线性线性操作,eg: man + woman ~= queen.
值得提出的是Word2Vec工具主要包含两个模型,分别是skip-gram(跳字模型)和CBOW(连续词袋模型),以及两种高效的训练方法negative sampling和softmax。word2vec就是将词转换为向量,这个向量就可以认为是词的特征向量,词是nlp中最细粒度的,词组成句子,句子组成段落、篇章...。我们将词的向量表示出来,那么更粗粒度的表示也可表示出来。
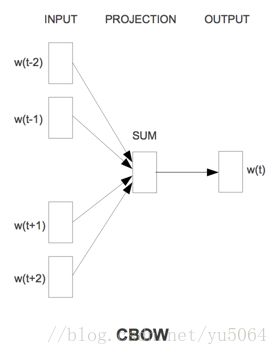


注意:在CBOW模型中,我们最后得到的词向量实际上权重矩阵,我们并不关心最后的输出是什么,我们输入层是词的onehot编码,V是我们最后学习到的向量维度大小,C为我们词的上下文个数,学习目标就是让我们预测的中间词和onehot的label越小越好,这样权重矩阵就是我们最终所需的。
skip-gram和CBOW类似,只不过是反过来用当前词预测上下文。

【计算方式可参考论文里,这里打公式太麻烦了,有大佬知道有啥插件或者啥啥能方便快捷的打出来求告知一下。】
- 关系约束模型(RTM):
利用一个词的其他相关词来进行预测这个词的向量,利用单词之间synonymous 或者 paraphrase构建知识库。将这个先验当作编码,再对Word2Vec中删除上下文作为目标函数来学习嵌入。原论文公式(3)。
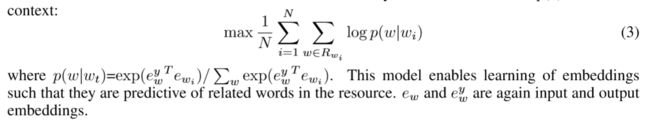
- 联合模型
就是将Word2Vec和RTM联合起来,
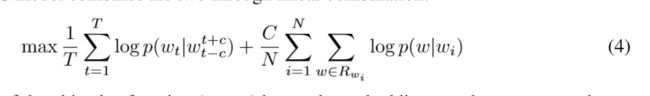
- CNN+CRF
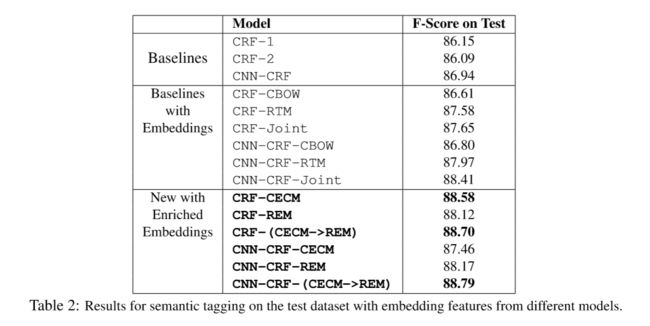
命名实体识别由于有长距离依赖问题,大部分都用rnn家族模型,尽可能记住长序列的信息来对句子进行标注。但是RNN家族在GPU的利用上不如CNN,RNN无法做到并行。CNN的优势在于可以并行速度快,但是随着卷积层的增加,最后只得到原始信息的一小块,这就不利于句子的序列标注。当然后来也有人提出IDCNN(膨胀卷积),暂不讨论。而本论文中的CNN是一个基本的CNN,就不在赘述,论文主要针对不同的嵌入向量学习在模型下的F-score做了对比,结果如下:
4.儿子二号(LSTM+CRF)
5.儿子三号(CNN+LSTM+CRF)
上面这两也没啥说的了,就是换了个模型。LSTM和CNN相信大家都很熟悉,只需要针对自己的问题设置合理的结构就行。LSTM一般都用双向的LSTM。后期再补充一个CRF内容。
才疏学浅,如有错误,请不吝赐教!