马斯克的自信从哪儿来 Part III.软硬结合达到自动驾驶人工智能
Part III. 软硬结合达到自动驾驶人工智能
接下来,我们将来到《马斯克的自信从哪儿来》本篇长文的终章,带您深度体验特斯拉自动驾驶技术。
请看下章——领略特斯拉自动驾驶
前文回顾:
END
“加速全球向可持续能源转变”。

扫码关注
特斯拉电动车
Part III. 软硬结合达到自动驾驶人工智能
马斯克认为的自动驾驶实现逻辑,既然人类依靠双眼就能认知周围环境,并且作出上述三个环节的决策。
那么特斯拉电动车配备有8个摄像头、1个前置毫米波雷达,12个超声波传感器,已然能比人类获取的数据要多。
问题的根本在哪里,即是人类最引以为傲的大脑处理。
一、特斯拉实现自动驾驶的逻辑与方法
先听我讲一个故事。当年上学的时候,大部分理工科课程都会出现一个很有意思的现象。
初中的时候物理化学等知识,到了高中后,老师会说,你初中老师讲的不对不准确,忘掉那些,让我重新跟你讲。
或者说,你曾经学过都是理想条件下的,老师为了方便教学简化了模型,现在我们要加入一个条件。而后当你读到大学时候会发现,原来高中老师跟初中老师是一样的……
引申到一个方法论,如果为了更好的理解一个问题,往往屏蔽掉某些因素或者假设某个条件是理想状况,如此一来在已有的知识范畴里,更容易理解学习。
回到正题上来,FSD芯片并非想要达到像《人工智能》级别的人工智能,而是拥有自动驾驶所需要的能力。人工智能的发展在近些年已经实现了诸多惊人的成就,例如ALpha Go,并且有一些甚至进入了生活,例如手机上语音助手。
那么假设特斯拉FSD芯片已经能在自动驾驶所需范畴内能做到人工智能,让我们试着理解一下特斯拉是如何由此实现自动驾驶。
1.神经网络和人脑的运作方式

要理解实现的逻辑和方法,得先了解一下神经网络和人脑的运作方式。
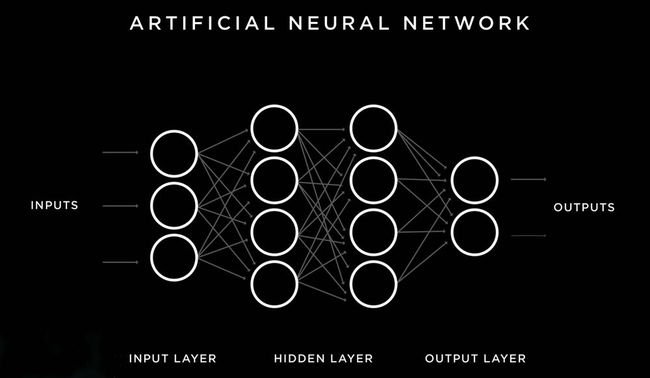
一个事物许多Pattern或者叫特征,例如苹果,认知苹果的过程大致可以简化为:
你第一次看到苹果(INPUTS),会接受到颜色的信息,形状的信息;
通过颜色信息的组合,通过基础信息又可以进一步知道组合信息,例如颜色的分布、花纹等(HIDDEN LAYER);
当你被告知这个事物叫苹果,你会将特征信息存储对应苹果(OUTPUTS)。
而后如果见到不同颜色不同形状的苹果,或许不会100%确信是苹果,但是经过信息比对,能猜出是苹果的概率很大。
再然后,你对此是否为苹果的判断会越来越精准。当然这还是仅仅局限于视觉信息,如果加上触觉、嗅觉等其它信息的参与,其判断结果将更加精准。
越来越多的特征信息存储,大脑会不断拥有更多的特征信息来判断,结果一步一步趋近于正确答案。就好像如果你了解某一车型,或许仅仅看到了进气格栅或者倒车镜,就能精准说出型号一样。
这是因为你大脑中储存了太多的相关信息,每一个特征都能不断减少答案备选项。根据外形颜色等,你得知是一辆车,进一步的组合信息得出是某一品牌的车,再根据一些特征交叉判断得知是某一型号的车。
而判断不仅仅局限于物体。
例如看到两个人牵手,基础视觉信息判断出是在牵手,而后根据体型信等息得知两人是异性,那么两人的关系可能是父女、母女、情侣或者其它可能,再之后通过样貌判断得出年龄进一步缩减可能,得出两人关系。又或者当两个人相互拳打脚踢,通过具体的神态或者听到之间对话得知信息,就可以预测出他们一会是去派出所还是去喝酒又或者是分手离婚。
也就是说当特征信息输入大脑后,每一个信息判断结果都会有诸多的可能,而通过相互交错影响制约,逐步降低错误结果概率,而在最终待选结果中判断得出可能性最高的,如果通过训练或者教学,得到的答案会越来越接近答案。
2.特斯拉如何通过神经网络实现自动驾驶
那么,特斯拉是如何通过类似大脑运行逻辑的神经网络实现自动驾驶呢?
初步学习
当影像信息输入后,经过FSD芯片的处理,判断出道路分界线、周围车辆、道路边界以及交通指示牌(灯)等等,对道路走向、移动物体运动轨迹作出预测,从而得出可行使区域。

(8个摄像头配合前置雷达信息以及特斯拉数据库提供信息)
而训练的方法,正如上文所讲,通过大量的图像信息的输入,在神经网络判断出的答案中,标识正确答案,周而复始。
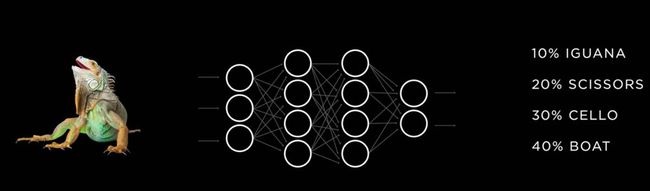
(通过左侧图片输入得出不同结果的概率)
不像人类,芯片不会因为学习时长而疲惫。通过大量的数据输入,让芯片不断“学习”,存储的特征信息越来越多,判断的也就越来越精准。
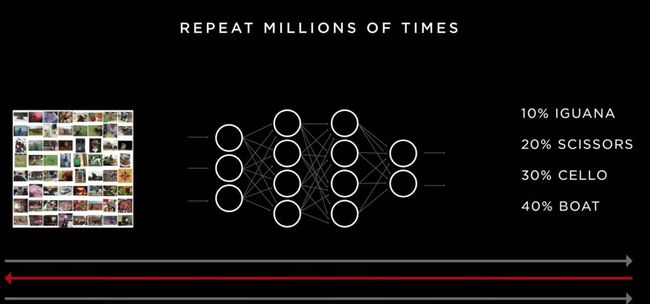
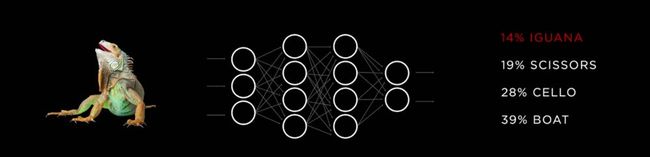
(通过大量数据训练得出正确结论概率提高)
不过认识动物并不是一辆自动驾驶汽车所需要,而是行驶道路环境中的事物,但是道理是一样的。
通过初步的学习,得知哪些东西是道路分界线、哪些是路标(什么意思)、哪些是障碍物、哪些是车辆等等,让芯片先初步认知行驶环境。

(行驶路线预测)
但是正如现实世界中的环境,道路环境千变万化,各种情况都会随时出现。
例如上图中由于前车遮挡了分界线延长,芯片如果通过调取特斯拉行驶采集数据,而大量数据都是高速路的特征,则芯片判断道路是直的可能性较大,结果将会惨不忍睹。

(通过特斯拉数据库获取数据进行“参考学习”)
所以前期需要人工修正,将各种可能路况“教”给芯片,让芯片如同儿童一样,学习基本知识。

(人工修正特殊情况)
当然仅仅认识道路还是不够,还有许多道路情况需要处理。例如隧道、阴天、道路突然出现的动物等等,都需要让芯片逐步了解并学习其特征。

(不同环境的多样化输入)
模拟驾驶
当初步学习进行到一定阶段,行业内都会用另一种方式训练,那就是模拟驾驶——通过生成不同的驾驶环境,让芯片去做决策并从中“学习”。
如同是训练飞行员使用的飞行模拟器,但是具有人工智能的神经网络芯片,因为运行速度以及不存在疲惫问题,可以更加快速地模拟学习,不断提高精准度。
就像大名鼎鼎的Alpha Go,在经过有限的围棋教学后,模拟自己与自己博弈下棋,模拟出近乎无限种可能的局面,而从中学习“正确”的走法,从而赢得人类。
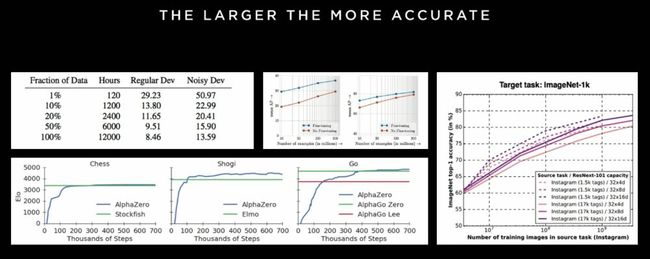
(Google公布的人工智能学习输入数据量与正确答案的关系)
虽然下围棋的可变数和可能性已经是极其夸张,但是现实世界中驾驶可能出现的情况,会更加复杂。
模拟尽管会很高效,但是毕竟是模拟驾驶,并非实际环境,模拟器就算再“完美”,仍与现实世界有差距。驾驶汽车,即便是好的驾驶员有着大量的驾驶经验,仍旧需要“老师傅”的指点教导。
特斯拉通过车载传感器采集数据,可以反向学习驾驶员在遇到不同情况下作出的操作,并以此优化自己。
再进一步,由于其它汽车的行驶方式不一定按照“标准”执行,特斯通过Shadow模式,作出除了预测其可能的行驶路径,还需要在安全范围内的“试错”。
例如,当变换道路时,根据后车的车速判断是安全的,芯片不会”毫不犹豫“转向变道,而是在安全的范围内,作出尝试转向决策,此时芯片仍“观察”后车的行驶状态,如果后车突然加速或者发生其它情况导致此次变道会有危险,则放弃变道并且回到原车道。

(Shadow功能)
关于距离判断问题,是摄像头与激光雷达之争的焦点。
人类依靠双眼获取的图像交叉产生的三维感知,可以判断出距离信息,而即便是某些双眼图像不交叉的动物,依靠产生位移后两个画面交叉感知,得出三维感知,最后判断出距离信息。
特斯拉通过8个摄像头的图像交叉分析,以及前置的毫米波雷达信息补充,构件出周围环境的3D模型。加上雷达判断出精准的距离信息,配合图像判断物体整体空间形状,综合在一起,可以对物体有更细致精准的距离判断。

(原点是雷达信息,立方体框是图像信息)
原理是,物体即便是在运动或不同视角下,本身形状尺寸是基本不变的,通过交叉分析同一个物体不同帧数下的图像信息,保证其外形各项参数不变,从而可以推算出精准的3D建模。

(判断物体具体形状参数的方法)
通过FSD芯片的研发,配合上神经网络的“学习”能力,结合特斯拉强大的模拟电脑Mojo,还有什么东西去保证这个自动驾驶芯片能够保障其“能力”呢?
二、保障特斯拉自动驾驶能力的其他关键因素
1.海量数据来源
在Q&A环节时候有一个提问,特斯拉如何保证其技术不被盗取或者如何保持其领先的地位。
马斯克讲到,即便是有人仿制我们的芯片并且反向编译了我们的自动驾驶软件,但是我们有一个巨大的优势。那就是海量的数据来源,每一台特斯拉电动车都能源源不断提供“教材”信息,通过神经网络计算后存储到的数据将是特斯拉最具有竞争力的保证。


(通过特斯拉车辆提供无数的海量数据)
2.空中升级OTA功能
不仅仅是海量的数据,特斯拉的空中升级OTA功能也是保障自动驾驶的另一个关键部分。
通过无线传输“学习”数据,所有的数据运算得到的“经验”可以通过OTA不断交流,使得所有的特斯拉车辆能够“三个臭皮匠,顶个诸葛亮”。
并且,即便断线,特斯拉也能依靠已经存储的数据,进行安全驾驶,只不过是短暂的停止了“学习”而已。
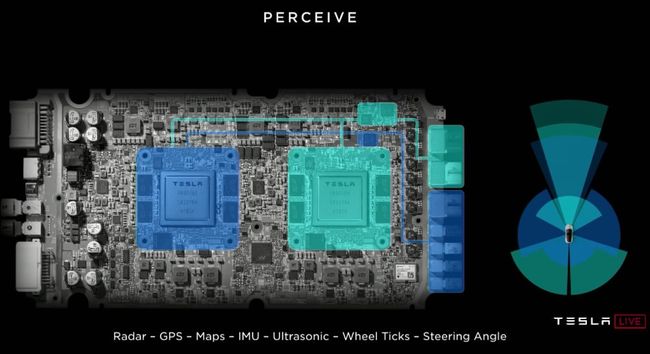
(车载电脑有两套图示FSD芯片组成)
接下来,我们将来到《马斯克的自信从哪儿来》本篇长文的终章,带您深度体验特斯拉自动驾驶技术。
请看下章——领略特斯拉自动驾驶
前文回顾:
END
“加速全球向可持续能源转变”。
扫码关注
特斯拉电动车