在先前的 TiDB 源码阅读系列文章(四) 中,我们介绍了 Insert 语句,想必大家已经了解了 TiDB 是如何写入数据,本篇文章介绍一下 Select 语句是如何执行。相比 Insert,Select 语句的执行流程会更复杂,本篇文章会第一次进入优化器、Coprocessor 模块进行介绍。
表结构和语句
表结构沿用上篇文章的:
CREATE TABLE t {
id VARCHAR(31),
name VARCHAR(50),
age int,
key id_idx (id)
};
Select 语句只会讲解最简单的情况:全表扫描+过滤,暂时不考虑索引等复杂情况,更复杂的情况会在后续章节中介绍。语句为:
SELECT name FROM t WHERE age > 10;
语句处理流程
相比 Insert 的处理流程,Select 的处理流程中有 3 个明显的不同:
-
需要经过 Optimize
Insert 是比较简单语句,在查询计划这块并不能做什么事情(对于 Insert into Select 语句这种,实际上只对 Select 进行优化),而 Select 语句可能会无比复杂,不同的查询计划之间性能天差地别,需要非常仔细的进行优化。
-
需要和存储引擎中的计算模块交互
Insert 语句只涉及对 Key-Value 的 Set 操作,Select 语句可能要查询大量的数据,如果通过 KV 接口操作存储引擎,会过于低效,必须要通过计算下推的方式,将计算逻辑发送到存储节点,就近进行处理。
-
需要对客户端返回结果集数据
Insert 语句只需要返回是否成功以及插入了多少行即可,而 Select 语句需要返回结果集。
本篇文章会重点说明这些不同的地方,而相同的步骤会尽量化简。
Parsing
Select 语句的语法解析规则在 这里。相比 Insert 语句,要复杂很多,大家可以对着 MySQL 文档 看一下具体的解析实现。需要特别注意的是 From 字段,这里可能会非常复杂,其语法定义是递归的。
最终语句被解析成 ast.SelectStmt 结构:
type SelectStmt struct {
dmlNode
resultSetNode
// SelectStmtOpts wraps around select hints and switches.
*SelectStmtOpts
// Distinct represents whether the select has distinct option.
Distinct bool
// From is the from clause of the query.
From *TableRefsClause
// Where is the where clause in select statement.
Where ExprNode
// Fields is the select expression list.
Fields *FieldList
// GroupBy is the group by expression list.
GroupBy *GroupByClause
// Having is the having condition.
Having *HavingClause
// OrderBy is the ordering expression list.
OrderBy *OrderByClause
// Limit is the limit clause.
Limit *Limit
// LockTp is the lock type
LockTp SelectLockType
// TableHints represents the level Optimizer Hint
TableHints [](#)*TableOptimizerHint
}
对于本文所提到的语句 SELECT name FROM t WHERE age > 10; name 会被解析为 Fields,WHERE age > 10 被解析为 Where 字段,FROM t 被解析为 From 字段。
Planning
在 planBuilder.buildSelect() 方法中,我们可以看到 ast.SelectStmt 是如何转换成一个 plan 树,最终的结果是一个 LogicalPlan,每一个语法元素都被转换成一个逻辑查询计划单元,例如 WHERE c > 10 会被处理为一个 plan.LogicalSelection 的结构:
if sel.Where != nil {
p = b.buildSelection(p, sel.Where, nil)
if b.err != nil
return nil
}
}
具体的结构如下:
// LogicalSelection represents a where or having predicate.
type LogicalSelection struct {
baseLogicalPlan
// Originally the WHERE or ON condition is parsed into a single expression,
// but after we converted to CNF(Conjunctive normal form), it can be
// split into a list of AND conditions.
Conditions []expression.Expression
}
其中最重要的就是这个 Conditions 字段,代表了 Where 语句需要计算的表达式,这个表达式求值结果为 True 的时候,表明这一行符合条件。
其他字段的 AST 转 LogicalPlan 读者可以执行研究一下,经过个这个 buildSelect() 函数后,AST 变成一个 Plan 的树状结构树,下一步会在这个结构上进行优化。
Optimizing
让我们回到 plan.Optimize() 函数,Select 语句得到的 Plan 是一个 LogicalPlan,所以 这里 可以进入 doOptimize 这个函数,这个函数比较短,其内容如下:
func doOptimize(flag uint64, logic LogicalPlan) (PhysicalPlan, error) {
logic, err := logicalOptimize(flag, logic)
if err != nil {
return nil, errors.Trace(err)
}
if !AllowCartesianProduct && existsCartesianProduct(logic) {
return nil, errors.Trace(ErrCartesianProductUnsupported)
}
physical, err := dagPhysicalOptimize(logic)
if err != nil {
return nil, errors.Trace(err)
}
finalPlan := eliminatePhysicalProjection(physical)
return finalPlan, nil
}
大家可以关注来两个步骤:logicalOptimize 和 dagPhysicalOptimize,分别代表逻辑优化和物理优化,这两种优化的基本概念和区别本文不会描述,请大家自行研究(这个是数据库的基础知识)。下面分别介绍一下这两个函数做了什么事情。
逻辑优化
逻辑优化由一系列优化规则组成,对于这些规则会按顺序不断应用到传入的 LogicalPlan Tree 中,见 logicalOptimize() 函数:
func logicalOptimize(flag uint64, logic LogicalPlan) (LogicalPlan, error) {
var err error
for i, rule := range optRuleList {
// The order of flags is same as the order of optRule in the list.
// We use a bitmask to record which opt rules should be used. If the i-th bit is 1, it means we should
// apply i-th optimizing rule.
if flag&(1<目前 TiDB 已经支持下列优化规则:
var optRuleList = []logicalOptRule{
&columnPruner{},
&maxMinEliminator{},
&projectionEliminater{},
&buildKeySolver{},
&decorrelateSolver{},
&ppdSolver{},
&aggregationOptimizer{},
&pushDownTopNOptimizer{},
}
这些规则并不会考虑数据的分布,直接无脑的操作 Plan 树,因为大多数规则应用之后,一定会得到更好的 Plan(不过上面有一个规则并不一定会更好,读者可以想一下是哪个)。
这里选一个规则介绍一下,其他优化规则请读者自行研究或者是等到后续文章。
columnPruner(列裁剪) 规则,会将不需要的列裁剪掉,考虑这个 SQL: select c from t; 对于 from t 这个全表扫描算子(也可能是索引扫描)来说,只需要对外返回 c 这一列的数据即可,这里就是通过列裁剪这个规则实现,整个 Plan 树从树根到叶子节点递归调用这个规则,每层节点只保留上面节点所需要的列即可。
经过逻辑优化,我们可以得到这样一个查询计划:

其中 FROM t 变成了 DataSource 算子,WHERE age > 10 变成了 Selection 算子,这里留一个思考题,SELECT name 中的列选择去哪里了?
物理优化
在物理优化阶段,会考虑数据的分布,决定如何选择物理算子,比如对于 FROM t WHERE age > 10 这个语句,假设在 age 字段上有索引,需要考虑是通过 TableScan + Filter 的方式快还是通过 IndexScan 的方式比较快,这个选择取决于统计信息,也就是 age > 10 这个条件究竟能过滤掉多少数据。
我们看一下 dagPhysicalOptimize 这个函数:
func dagPhysicalOptimize(logic LogicalPlan) (PhysicalPlan, error) {
logic.preparePossibleProperties()
logic.deriveStats()
t, err := logic.convert2PhysicalPlan(&requiredProp{taskTp: rootTaskType, expectedCnt: math.MaxFloat64})
if err != nil {
return nil, errors.Trace(err)
}
p := t.plan()
p.ResolveIndices()
return p, nil
}
这里的 convert2PhysicalPlan 会递归调用下层节点的 convert2PhysicalPlan 方法,生成物理算子并且估算其代价,然后从中选择代价最小的方案,这两个函数比较重要:
// convert2PhysicalPlan implements LogicalPlan interface.
func (p *baseLogicalPlan) convert2PhysicalPlan(prop *requiredProp) (t task, err error) {
// Look up the task with this prop in the task map.
// It's used to reduce double counting.
t = p.getTask(prop)
if t != nil {
return t, nil
}
t = invalidTask
if prop.taskTp != rootTaskType {
// Currently all plan cannot totally push down.
p.storeTask(prop, t)
return t, nil
}
for _, pp := range p.self.genPhysPlansByReqProp(prop) {
t, err = p.getBestTask(t, pp)
if err != nil {
return nil, errors.Trace(err)
}
}
p.storeTask(prop, t)
return t, nil
}
func (p *baseLogicalPlan) getBestTask(bestTask task, pp PhysicalPlan) (task, error) {
tasks := make([]task, 0, len(p.children))
for i, child := range p.children {
childTask, err := child.convert2PhysicalPlan(pp.getChildReqProps(i))
if err != nil {
return nil, errors.Trace(err)
}
tasks = append(tasks, childTask)
}
resultTask := pp.attach2Task(tasks...)
if resultTask.cost() < bestTask.cost() {
bestTask = resultTask
}
return bestTask, nil
}
上面两个方法的返回值都是一个叫 task 的结构,而不是物理计划,这里引入一个概念,叫 Task,TiDB 的优化器会将 PhysicalPlan 打包成为 Task。Task 的定义在 task.go 中,我们看一下注释:
// task is a new version of `PhysicalPlanInfo`. It stores cost information for a task.
// A task may be CopTask, RootTask, MPPTask or a ParallelTask.
type task interface {
count() float64
addCost(cost float64)
cost() float64
copy() task
plan() PhysicalPlan
invalid() bool
}
在 TiDB 中,Task 的定义是能在单个节点上不依赖于和其他节点进行数据交换即可进行的一些列操作,目前只实现了两种 Task:
CopTask 是需要下推到存储引擎(TiKV)上进行计算的物理计划,每个收到请求的 TiKV 节点都会做相同的操作
RootTask 是保留在 TiDB 中进行计算的那部分物理计划
如果了解过 TiDB 的 Explain 结果,那么可以看到每个 Operator 都会标明属于哪种 Task,比如下面这个例子:
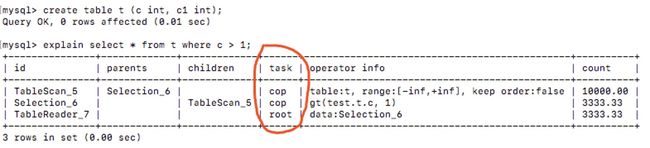
整个流程是一个树形动态规划的算法,大家有兴趣可以跟一下相关的代码自行研究或者等待后续的文章。
经过整个优化过程,我们已经得到一个物理查询计划,这个 SELECT name FROM t WHERE age > 10; 语句能够指定出来的查询计划大概是这样子的:
读者可能会比较奇怪,为什么只剩下这样一个这一个物理算子?WHERR age > 10 哪里去了?实际上 age > 10 这个过滤条件被合并进了 PhysicalTableScan,因为 age > 10 这个表达式可以下推到 TiKV 上进行计算,所以会把 TableScan 和 Filter 这样两个操作合在一起。哪些表达式会被下推到 TiKV 上的 Coprocessor 模块进行计算呢?对于这个 Query 是在下面 这个地方 进行识别:
// PredicatePushDown implements LogicalPlan PredicatePushDown interface.
func (ds *DataSource) PredicatePushDown(predicates []expression.Expression) ([]expression.Expression, LogicalPlan) {
_, ds.pushedDownConds, predicates = expression.ExpressionsToPB(ds.ctx.GetSessionVars().StmtCtx, predicates, ds.ctx.GetClient())
return predicates, ds
}
在 expression.ExpressionsToPB 这个方法中,会把能下推 TiKV 上的表达式识别出来(TiKV 还没有实现所有的表达式,特别是内建函数只实现了一部分),放到 DataSource.pushedDownConds 字段中。接下来我们看一下 DataSource 是如何转成 PhysicalTableScan,见 DataSource.convertToTableScan() 方法。这个方法会构建出 PhysicalTableScan,并且调用 addPushDownSelection() 方法,将一个 PhysicalSelection 加到 PhysicalTableScan 之上,一起放进 copTask 中。
这个查询计划是一个非常简单计划,不过我们可以用这个计划来说明 TiDB 是如何执行查询操作。
Executing
一个查询计划如何变成一个可执行的结构以及如何驱动这个结构执行查询已经在前面的�两篇文章中做了描述,这里不再敷述,这一节我会重点介绍如何具体的执行过程以及 TiDB 的分布式执行框架。
Coprocessor 框架
Coprocessor 这个概念是从 HBase 中借鉴而来,简单来说是一段注入在存储引擎中的计算逻辑,等待 SQL 层发来的计算请求(序列化后的物理执行计划),处理本地数据并返回计算结果。在 TiDB 中,计算是以 Region 为单位进行,SQ
L 层会分析出要处理的数据的 Key Range,再将这些 Key Range 根据 PD 中拿到的 Region 信息划分成若干个 Key Range,�最后将这些请求发往对应的 Region。
SQL 层会将多个 Region 返回的结果进行汇总,在经过所需的 Operator 处理,生成最终的结果集。
DistSQL
请求的分发与汇总会有很多复杂的处理逻辑,比如出错重试、获取路由信息、控制并发度以及结果返回顺序,为了避免这些复杂的逻辑与 SQL 层耦合在一起,TiDB 抽象了一个统一的分布式查询接口,称为 DistSQL API,位于 distsql 这个包中。
其中最重要的方法是 SelectDAG 这个函数:
// SelectDAG sends a DAG request, returns SelectResult.
// In kvReq, KeyRanges is required, Concurrency/KeepOrder/Desc/IsolationLevel/Priority are optional.
func SelectDAG(goCtx goctx.Context, ctx context.Context, kvReq *kv.Request, fieldTypes []*types.FieldType) (SelectResult, error) {
// kvReq 中包含了计算所涉及的数据的 KeyRanges
// 这里通过 TiKV Client 向 TiKV 集群发送计算请求
resp := ctx.GetClient().Send(goCtx, kvReq)
if resp == nil {
err := errors.New("client returns nil response")
return nil, errors.Trace(err)
}
if kvReq.Streaming {
return &streamResult{
resp: resp,
rowLen: len(fieldTypes),
fieldTypes: fieldTypes,
ctx: ctx,
}, nil
}
// 这里将结果进行了封装
return &selectResult{
label: "dag",
resp: resp,
results: make(chan newResultWithErr, kvReq.Concurrency),
closed: make(chan struct{}),
rowLen: len(fieldTypes),
fieldTypes: fieldTypes,
ctx: ctx,
}, nil
}
TiKV Client 中的具体逻辑我们暂时跳过,这里只关注 SQL 层拿到了这个 selectResult 后如何读取数据,下面这个接口是关键。
// SelectResult is an iterator of coprocessor partial results.
type SelectResult interface {
// NextRaw gets the next raw result.
NextRaw(goctx.Context) ([]byte, error)
// NextChunk reads the data into chunk.
NextChunk(goctx.Context, *chunk.Chunk) error
// Close closes the iterator.
Close() error
// Fetch fetches partial results from client.
// The caller should call SetFields() before call Fetch().
Fetch(goctx.Context)
// ScanKeys gets the total scan row count.
ScanKeys() int64
selectResult 实现了 SelectResult 这个接口,代表了一次查询的所有结果的抽象,计算是以 Region 为单位进行,所以这里全部结果会包含所有涉及到的 Region 的结果。调用 Chunk 方法可以读到一个 Chunk 的数据,通过不断调用 NextChunk 方法,直到 Chunk 的 NumRows 返回 0 就能拿到所有结果。NextChunk 的实现会不断获取每个 Region 返回的 SelectResponse,把结果写入 Chunk。
Root Executor
能推送到 TiKV 上的计算请求目前有 TableScan、IndexScan、Selection、TopN、Limit、PartialAggregation 这样几个,其他更复杂的算子,还是需要在单个 tidb-server 上进行处理。所以整个计算是一个多 tikv-server 并行处理 + 单个 tidb-server 进行汇总的模式。
总结
Select 语句的处理过程中最复杂的地方有两点,一个是查询优化,一个是如何分布式地执行,这两部分后续都会有文章来更进一步介绍。下一篇文章会脱离具体的 SQL 逻辑,介绍一下如何看懂某一个特定的模块。
作者: 申砾