也许我们习惯了在IDE环境中敲代码、执行程序,只需一个键就能完成从编译、汇编、链接到显示结果的所有工作。。
那么你有没有疑惑过,当你执行一个简单的C程序时,它内部到底发生了什么呢?下面我们就从汇编语言的层面上来分析一下程序运行的全过程。
假设我写了一个简单的a+b的程序:

接下来我把它编译成汇编代码。注意:在Unix/Linux下使用的是AT&T格式的汇编语言,而Dos/Windows下是Intel风格的汇编。这两者在语法格式上还是有很大的不同的。由于这里是在Linux系统上编译的,所以产生的是AT&T格式的汇编。
将上面的代码保存为main.c。下面对main.c进行编译:
- gcc –S –o main.s main.c -m32
这里的-S表示输出汇编代码(如果不加的话就直接生产目标文件了)。后面的-m32表示生成32位的汇编代码。
执行这条命令后,产生了如下汇编代码main.s:

注意:生成的汇编代码会有一些其它的信息,这里我把它们删了,我们只分析和我们的C代码密切相关的部分。
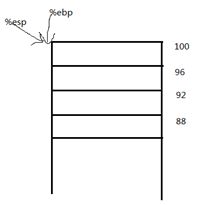
我们知道,系统会为每个进程分配一个堆栈空间(关于进程的堆栈空间的详细介绍请参考《Unix环境高级编程》):

程序中的变量包括函数调用占用的都是栈的空间,它的地址是向下递减的。那么初始化栈假设是这样的:

这里为了简化问题,假设栈底地址为100,由于地址向下递减,所以依次是96,92,88.....
%ebp和%esp是寄存器,其中%ebp存放的是栈底指针,而%esp存放的是栈顶指针。
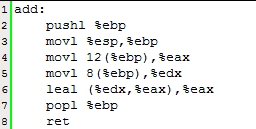
首先从main函数开始执行:
pushl %ebp
表示把%ebp寄存器中的内容压入堆栈,这时%esp就指向地址96处了(栈顶指针自动减4,因为是按32位寻址的。。)。
movl %esp,%ebp
表示将栈顶指针赋值给栈底指针,那么这时%ebp就是96了。
subl $24,%esp
将栈顶指针减去24,这时%esp指向72.
movl $1,-12(%ebp)
movl $2,-8(%ebp)
这两条指令表示把立即数1和2分别放置到(%ebp)减去12和减去8的位置上。
movl -8(%ebp),%eax
movl %eax,4(%esp)
表示把2赋给%eax,然后再放置在(%esp)+4的位置上。下面两天指令也相同。
发现没?这里就是在给函数add()传递参数呢。。
此时,栈的情况如下:
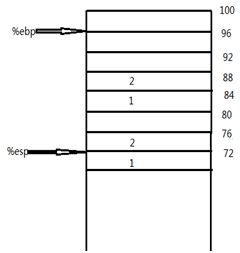
接下来执行:
call add
call指令开始调用add函数,它的作用相当于下面两天指令:
pushl %eip
movel add %eip
movel add %eip
其中%eip寄存器存放的是当前执行的指令的地址。这里调用了call以后,相当于把当前指令的地址压入栈中,此时%esp指向68,然后把add函数要执行的指令的地址赋给%eip。
接下来开始执行add函数中的指令,流程和上面的一样。
这时又用pushl %ebp把栈底指针入栈,你可能会有疑问,为什么每次调用一个函数都需要把%ebp入栈呢?其实你会发现,当add函数执行到后来,有一个popl %ebp指令,这个指令相当于把原来入栈的%ebp又恢复原值了,这个时候的%ebp指向的就是main函数的栈底了(相当于又回到main函数的环境了)。当然add函数里还有一个ret,ret指令代表popl %eip,就是把原来的%eip有恢复原值了,这样代码执行流就回到了main函数中调用add函数的下一条指令了。
当main函数执行完movl %eax,-4(%ebp)后,开始执行leave,leave指令相当于如下两条指令:
mov %ebp,%esp
pop %ebp
pop %ebp
发现了吗?这里相当于恢复调用main函数之前的栈情况了,借着执行ret后就回到原先的指令流了。这时候栈就恢复到最开始的状态啦。。简单吧?关于函数调用过程中栈空间的变化情况现在了解一点了吗?