链接方式存储的线性表简称为链表 Link List
链表的具体存储表示为:
1)用一组任意的存储单元来存放
2)链表中结点的逻辑次序和物理次序不一定相同。还必须存储指示其后继结点的地址信息
用一组地址任意的存储单元存放线性表中的数据元素
链表是:线性表中数据为(1,3,5,7.8)
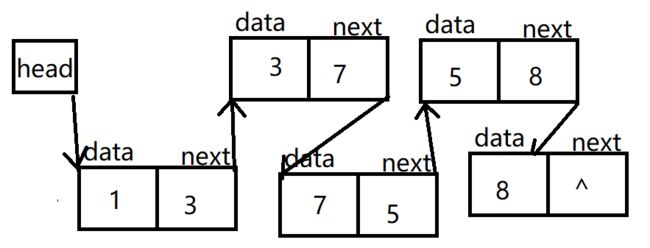
单链表:data域:存放结点的数据域
next域:存放结点的直接后继的地址(位置)的指针域
所有结点通过指针链接而组成单链表
NULL:成为空指针
head: 头指针,存放链表的第一个结点地址(每个链表都需要有一个头指针)

单链表的一般图示法:

单链表特点:
起始节点又叫做首结点,没有前驱,故设头指针head指向开始结点
链表由头指针唯一确定,单链表可以用头指针的名字来命名。头指针是head的链表可以称为表head
终端结点又称尾结点,没有后继结点,所以终端结点的指针域为空,NULL
除头结点之外的结点为表结点
为运算操作方便,头节点中不存数据哦~
单链表的类型定义:
1 ytpedef struct node{ 2 Datatype data; //数据域 3 struct node*next;//指针域,存放该结点的直接后继结点的地址 4 } Node, *LinkList;
1.初始化
每一个新建的单链表都需要进行一个初始化,(一个空的单链表是一个头指针和一个头结点构成的)
//建立一个空链表 LinkList InitiateLinkList(){ LinkList head; //头指针 head =malloc (sizeof(node)); //动态构建一节点,它是头结点 head->next=null; return head;
现在咱们已经创建了一个新链表,接下来创建几个数据域后如何来算表的长度呢?
:在单链表存储结构中,线性表的长度等于单链表所含结点的个数(不含头结点)
1 //求表长 2 int lengthLinklist (LinkList head){ 3 Node *p; 4 p=head;j=0; 5 while(p->next!=null){//p的下一个指针不为空继续循环,当p的指针为空跳出循环 6 p=p->next;//p指向下个结点 7 j++;长度加1 8 } 9 return (j);}
3.读表元素
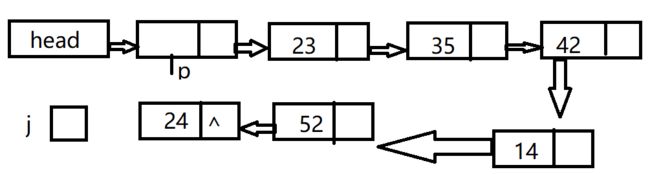
步骤;查找第I个结点
1.零计数器J为0
2.令P指向头节点
3.当下一个结点不空时,并且j 4.如果j等于i,则p所指结点为要找的第i结点,否则,链表中无第i结点 4.定位 定位运算是对给定表元素的值,找出这个元素的位置。对 5.插入 插入运算是将值为x的新结点插入到表的第i个结点 6. 删除 算法步骤 双向循环链表 在链表中设置两个指针域, 双向链表的结构体 双向循环链表适合应用在需要经常 双向链表中结点的删除 设p指向待删结点, 删除*p可通过下述语句完成: (1) 、 (2) 这两个语句的执行顺序可以颠倒。 双向链表中结点的插入 在p所指结点的后面插入一个新结点*t, 需要修改四个指针: 1 Node *GetlinkList(LinkList head,int i){
2 Node *p;
3 p=head->next;
4 int c=1;
5 while((c
于单链表,给定一个结点的值,找出这个结点是单链表的
第几个结点。定位运算又称为按值查找。
具体步骤:
1、令p指向头结点
2、令i=0
3、当下一个结点不空时, p指向下一个结点,同时i的值加1
4、直到p指向的结点的值为x,返回i+1的值。
5、如果找不到结点值为x的话,返回值为0 1 int LocateLinklist (LinkList head ,Data Type x){
2 //求表head中第一个值等于x的结点的序号,若不存在这种结点,返回结果为0
3 Node *p=head;//p是工作指针
4 p=p->next;//初始时P指向首结点
5 int i=0;//i代表 结点的序号,这里初值为
6 while(p!=null&&p->data!=x){//访问链表
7 i++;
8 p=p->next;
9 }
10 if(p!=null)
11 return i+1;
12 else return 0;}
的位置上,即插入到ai-1与ai之间。
具体步骤:
(1)找到ai-1存储位置p
(2)生成一个数据域为x的新结点*s
(3)令结点*p的指针域指向新结点
(4)新结点的指针域指向结点ai。 
1 void InsertLinklist (LinkList head, DataType x, int i)
2 //在表head的第i个数据元素结点之前插入一个以x为值的新结点
3 {
4 Node *p,*q;
5 if (i==1) q=head;
6 else q=GetLinklist (head, i-1); //找第 i-1个数据元素结点
7 if (q==NULL) //第i-1个结点不存在
8 exit(“找不到插入的位置”);
9 else
10 {
11 p=malloc(sizeof (Node) );p->data=x; //生成新结点
12 p->next=q->next; //新结点链域指向*q的后继结点
13 q->next=p; //修改*q的链域
14 }
15 }
删除运算是将表的第i个结点删去。
(1)找到ai-1的存储位置p
(2)令p->next指向ai的直接后继结点
(3)释放结点ai的空间,将其归还给"存储池"。 1 void DeleteLinklist(LinkList head, int i)
2 //删除表head的第i个结点
3 {
4 Node *q;
5 if(i==1) q=head;
6 else q=GetLinklist(head, i-1); //先找待删结点的直接前驱
7 if(q !== NULL && q->next != NULL) //若直接前驱存在且待删结点存在
8 {
9 p=q->next; //p指向待删结点
10 q->next=p->next; //移出待删结点
11 free(p); //释放已移出结点p的空间
12 }
13 else exit (“找不到要删除的结点”); //结点不存在
14 }
一个指向后继结点
一个指向前驱结点
这样的链表叫做双向链表 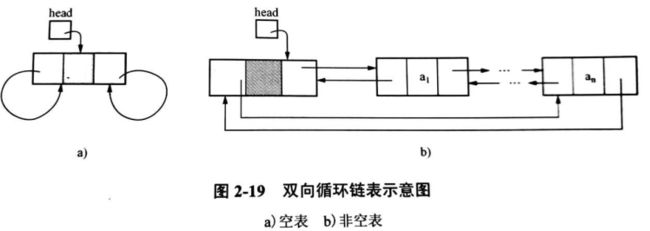
查找结点的前驱和后继的场合。 找
前驱和后继的复杂度均为: O(1)。 
1 struct dbnode
2 { DataType data;
3 struct dbnode *prior, *next;
4 };
5 typedef struct dbnode *dbpointer;
6 typedef dbpointer Dlinklist;
7 假设双向链表中p指向某节点
8 则有 p->prior->next 与p->next->prior相等
1 (1)p->prior->next=p->next; //p前驱结点的后链指向p的后继结点
2 (2)p->next->prior=p->prior; //p后继结点的前链指向p的前驱结点
3 (3)free(p); //释放*p的空间

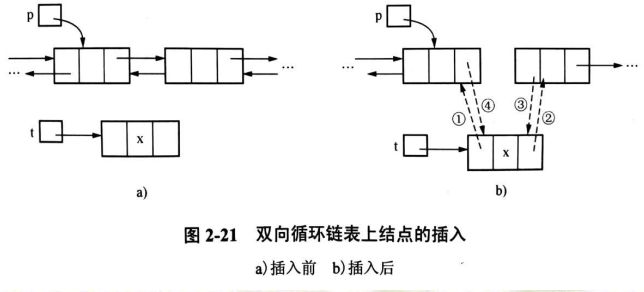
(1)t->prior=p;
(2)t->next=p->next;
(3)p->next->prior=t;
(4)p->next=t;