序
>机器学习的核心就是预测:预测我们想要什么,预测我们行为的结果,预测如何能实现我们的目标,预测世界将如何改变。
>终极算法即通用算法,它甚至综合了五大主要算法学派的观点。
机器学习革命
学习算法入门(概念)
>算法就是一系列指令,告诉计算机该做什么。计算机是由几十亿个微小开关(称为晶体管)组成的,而算法能在一秒内打开并关闭这些开关几十亿次。
>一个晶体管的状态就是一个比特信息:如果开关打开,信息就是1;如果开关关闭,信息就是0。
>最简单的算法是触动开关。
>第二简单的算法是:把两个比特结合起来。
>所有算法,无论多复杂,都能分解为这三种逻辑运算:且,或,非。
>一种算法不仅是简单的一套指令,这些指令必须精确且不能模糊,这样计算机才能够执行。
>算法是一套严格的标准。人们常说,你没法真正了解某样东西,直到你能用一种算法来将其表达出来(理查德·费曼曾说,“如果我无法创造某样东西,那么也就无法理解它”)。
>算法的限制:空间复杂性&时间复杂性
机器学习的意义
(商业、国家安全、总统选举、商业、医疗什么的。。。总之作用太多了。。。。)
举个栗子:
(2016年)谷歌每年的收入是500亿美元,预测点击率每上升1%,就可能意味着每年为公司带来额外5亿美元的收入。
终极算法
各种科学对机器学习的论证
(神经科学、进化论、物理学、统计学等多个学科中都能找到机器学习的影子,这真是惊人的巧合。。。但是我对这部分存疑很多。所以就不写了。)
终极算法长什么样?
>终极算法应该是一种通用算法,适用于任何一个任务。(但是这样的算法真的有必要吗???我质疑)
>终极算法不需要在遇到每个新问题时,都从零开始。
>终极算法不只是被动地消耗知识,它可以和周围的环境进行互动,然后积极寻找它想要的数据,就像机器人科学家“亚当”一样,或者像所有探索世界的孩子一样。
机器学习的五大学派
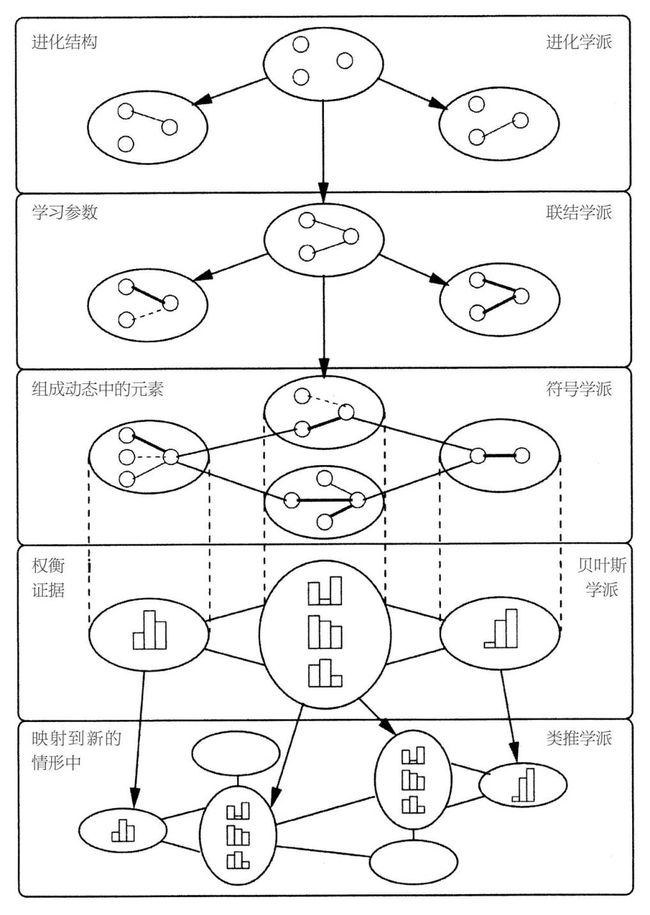
符号学派:休谟的归纳问题
所有的信息都可以简化为操作符号,就像数学家那样,为了解方程,会用其他表达式来代替本来的表达式。符号学者认为你不能从零开始学习:除了数据,你还需要一些原始的知识。他们已经弄明白,如何把先前存在的知识并入学习中,如何结合动态的知识来解决新问题。
他们的主算法是**逆向演绎**,逆向演绎致力于弄明白,为了使演绎进展顺利,哪些知识被省略了,然后弄明白是什么让主算法变得越来越综合。
约会问题的预测
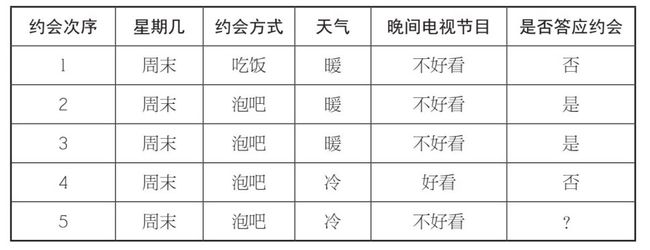
如何根据前几次约会情况,预测第5次她是否答应约会呢?
假设你朋友的回复由单个因素来决定。在这种情况下,算法就只包括看看每个已知的因素(时间、约会方式、天气、晚间电视节目),确定该因素是否每次都能准确预测她的回答。可问题就在于,每个因素都无法预测她的回答!你打赌了,然后输了。所以你把假设放宽了一点。如果你朋友的回答是由两个因素一起决定的呢?总共四个因素,每个因素有两种可能的值,那么总共有24种可能(总共有6对因素组合,即12乘以因素的两种可能)。数字太多,我们遇到尴尬:两个因素的四种组合准确预测了结果!接下来怎么办?如果你觉得运气还行,可以选其中的一种,然后祈祷最好的结果。但更明智的选择是采取民主的做法:对每个选项进行选择,然后选最后赢的预测。
如果所有两个因素组合的预测都失败了,你可以尝试任意个数因素的组合,即“合取概念”(conjunctive concept)。
*机器学习无法从零开始*:
>知识本身必须由归纳得来,因此知识也是有问题的。虽然知识是通过进化编入我们的大脑的,但我们不得不冒这个险。因为,不依靠知识进行学习是不可能的。
>机器学习这个问题是一个不适定问题(ill–posed problem):这个问题没有唯一解。解决不适定问题的唯一办法就是引入附加假设。
*对知识泵进行预设*:
>牛顿法则是机器学习的第一个不成文规则。我们归纳自己能力范围内、应用最广泛的规则,只有在数据的迫使下,才缩小规则的应用范围。
>然而,牛顿法则仅仅是第一步。还得弄明白我们见到的哪些是真实的——如何从原始数据中找出规律。标准的解决方法就是假设我们知道真理的形式,而算法的任务就是把这个形式具体化。
>首先做有条件的假设,如果这样无法解释数据,再放松假设的条件,这就是典型的机器学习。
*规则集问题*:
>将复杂概念以规则集的形式表示出来,机器学习经过一系列规则定义的概念,而不仅仅是单个规则。
>为了找到单个规则,我们也可以对算法进行改良,方法就是保留某数n的假设,不止一个数,然后在每个步骤中将这些数以所有可能的方法延伸开来,最后保留n的最佳结果。
E.g 零售商喜欢用比“分而治之”更为彻底的方法,也就是寻找所有能够准确预测每个购买项的规则,因为他们要决定该囤什么货。沃尔玛在该领域属先驱,他们早期的发现之一就是,如果你买了纸尿片,那么很有可能会买啤酒。为什么?对此进行解释的说法之一就是,妈妈让爸爸去超市买纸尿片,出于情感补偿,爸爸买了一箱啤酒。知道这一点,超市现在会把啤酒放在纸尿片旁边,这样啤酒就会卖得更好。
*过拟合问题*:
>自由的规则算法和富内斯一样,发挥不了作用。学习就意味着将细节遗忘,只记住重要部分。计算机就是最大的白痴专家:它们可以毫无差错地将所有东西记住,但那不是我们想让它们做的。
>每当算法在数据中找到现实世界中不存在的模型时,我们说它与数据过于拟合。过拟合问题是**机器学习中的中心问题**。
>避免幻觉模式唯一安全的方法,就是严格限制算法学习的内容,例如要求学习内容是一个简短的合取概念。很遗憾,这种做法就像把孩子和洗澡水一起倒掉一样,会让学习算法无法看到多数真实的模型,这些模型在数据中是可见的。因此,好的学习算法永远在无知与幻觉的夹缝中行走。
E.g 亚里士多德说要使一个物体不断运动,需要对其施加一个力,就犯了过拟合的错误。伽利略的天才之处在于,无须到外太空亲眼见证,他凭直觉就知道,不受外力影响的物体会一直保持运动。
>过拟合问题因为嘈杂的声音被严重夸大。在机器学习中,这些噪声仅仅意味着数据中的误差,或者你无法预测的偶然事件
>当你有过多假设,而没有足够的数据将这些假设区分开来时,就会产生过拟合问题。
>算法会尝试所有定义,而且这些定义也不是随机选择的。算法尝试的定义越多,越有可能偶然得到能够和所有例子匹配的定义。
>机器学习就是你拥有的数据的数量和你所做假设数量之间的较量。更多的数据会呈指数级地减少能够成立的假设数量,但如果一开始就做很多假设,最后你可能还会留下一些无法成立的假设。
*显著性检验*:
如何知道你的算法是否过拟合了?
>可以利用自己拥有的数据,将其分成一个训练集和一个测试集,然后前者交给学习算法,把后者隐藏起来不让学习算法发现,用来验证其准确度。留存数据的准确度就是机器学习中的“黄金标准”。
>另一个方法就是运用统计显著性检验来确保我们看到的模型真实可靠。
E.g 拥有300个正面例子、100个反面例子的规则,和拥有3个正面例子、1个负面例子的规则一样,它们训练数据的准确率都达到75%,但第一个规则几乎可以肯定比抛硬币好用。
如果我尝试了一条规则,400个例子中的准确率是75%,可能会相信这个规则。但如果我尝试了100万条规则,其中最佳的规则中,400个例子中的准确率是75%,可能就不会相信这个规则,因为这很有可能是偶然发生的。
>还有一个方法就是选择更加简单的假设,即奥卡姆剃刀原理(Ocam’s razor)。
>如果你的学习算法检测集准确度不尽如人意,你就得诊断问题在哪里。是因为无知,还是因为幻想?
*决策树*:
决策树的原理就像玩一个有实例的20问游戏。从“根部”开始,每个节点都会问每个属性的值,然后根据答案,我们沿着这个或另外一个分支继续下去。当到达“树叶”部分时,我们读取预测的概念。从“根部”到“树叶”的每条路线都对应一个规则。
拥有某个属性的概念组被称为类集,而预测类集的算法称为分类器。单个概念隐含两类定义:概念本身及其反面(例如,垃圾邮件和非垃圾邮件)。分类器是机器学习最为普遍的方式。
为了学习一棵好的决策树的优点,我们在每个节点选择这样的属性:在其所有分支中,产生的熵在平均值上属性最低,取决于每个分支上有多少例子。
如果连续变量的每个值都有一个分支,决策树将变得无限宽。一个简单的方法就是通过熵来选择几个临界值,然后使这些临界值起作用。
联结学派:大脑如何学习
对于联结学派来说,学习就是大脑所做的事情,因此我们要做的就是对大脑进行逆向演绎。大脑通过调整神经元之间连接的强度来进行学习,关键问题是找到哪些连接导致了误差,以及如何纠正这些误差。联结学派的主算法是反向传播学习算法,该算法将系统的输出与想要的结果相比较,然后连续一层一层地改变神经元之间的连接,目的是为了使输出的东西接近想要的东西。
进化学派:自然的学习算法
对于联结学派来说,学习就是大脑所做的事情,因此我们要做的就是对大脑进行逆向演绎。大脑通过调整神经元之间连接的强度来进行学习,关键问题是找到哪些连接导致了误差,以及如何纠正这些误差。联结学派的主算法是反向传播学习算法,该算法将系统的输出与想要的结果相比较,然后连续一层一层地改变神经元之间的连接,目的是为了使输出的东西接近想要的东西。
贝叶斯学派:在贝叶斯教堂里
贝叶斯学派最关注的问题是不确定性。所有掌握的知识都有不确定性,而且学习知识的过程也是一种不确定的推理形式。那么问题就变成,在不破坏信息的情况下,如何处理嘈杂、不完整甚至自相矛盾的信息。解决的办法就是运用概率推理,而主算法就是贝叶斯定理及其衍生定理。贝叶斯定理告诉我们,如何将新的证据并入我们的信仰中,而概率推理算法尽可能有效地做到这一点。
类推学派:像什么就是什么
对于类推学派来说,学习的关键就是要在不同场景中认识到相似性,然后由此推导出其他相似性。如果两个病人有相似的症状,那么也许他们患有相同的疾病。问题的关键是,如何判断两个事物的相似程度。类推学派的主算法是支持向量机,主算法找出要记忆的经历,以及弄明白如何将这些经历结合起来,用来做新的预测。