写在前面的话
上一节的复制集也就是主从能够解决我们高可用和数据安全性问题,但是无法解决我们的性能瓶颈问题。所以针对性能瓶颈,我们需要采用分布式架构,也就是分片集群,sharding cluster!
架构说明
架构规划:
我们这里准备了 4 台虚拟机:192.168.200.101-104
在分片集群中,mongodb 包含以下三个角色:mongos(router),config server,shard。
mongos 节点:用于服务连接,不存数据,有点像路由器。
config server 节点:保存集群相关配置以及数据到底存放在那个分片,所以数据非常重要,需要一主两从。
shard 节点:数据存储节点,由多个集群组成,每个集群可以为一主一从一arbiter。
端口设计:
shard 集群1:192.168.200.101-103:27001
shard 集群2:192.168.200.101-103:27002
config 集群:192.168.200.101-103:28001
mongos:192.168.200.104:29000
默认主尽量分开,这样能够避免压力都在一台机器上面。这只能算是一个简陋的集群。
架构如图:
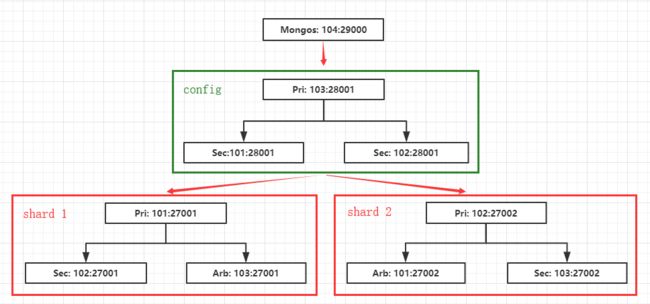
配置分片集群
1. 所有节点初始化安装:
# 关闭大页内存机制 if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi # 查看设置结果 cat /sys/kernel/mm/transparent_hugepage/enabled cat /sys/kernel/mm/transparent_hugepage/defrag # 初始化目录 mkdir -p /data/{backup,data,logs,packages,services} mkdir -p /data/packages/mongodb # 将安装包上传到:/data/packages/mongodb 下 # 解压 cd /data/packages/mongodb tar -zxf mongodb-linux-x86_64-rhel70-4.2.1.tgz mv mongodb-linux-x86_64-rhel70-4.2.1 /data/services/mongodb # 配置基础目录 cd /data/services/mongodb rm -f LICENSE-Community.txt MPL-2 README THIRD-PARTY-NOTICES THIRD-PARTY-NOTICES.gotools
2. 所有节点配置环境变量:
cat >> /etc/profile << EOF # mongodb env export MONGODB_HOME='/data/services/mongodb' export PATH=\$PATH:\${MONGODB_HOME}/bin EOF # 环境变量生效 source /etc/profile # 查看版本 mongo --version
3. 101-103 节点初始化目录设计:
cd /data/services
mkdir -p mongodb-shard1/{data,config,logs} mkdir -p mongodb-shard2/{data,config,logs} mkdir -p mongodb-config/{data,config,logs}
结构如下:
/data/services/ ├── mongodb -- mongodb 安装目录 │ └── bin ├── mongodb-config -- config 节点根目录 │ ├── config │ ├── data │ └── logs ├── mongodb-shard1 -- shard 1 节点根目录 │ ├── config │ ├── data │ └── logs └── mongodb-shard2 -- shard 2 节点根目录 ├── config ├── data └── logs
4. 101-103 节点构建 shard 1 集群:
添加配置:注意红色部分根据节点修改,蓝色部分为需要注意的
cat > /data/services/mongodb-shard1/config/shard.conf << EOF # 系统相关 systemLog: destination: file path: "/data/services/mongodb-shard1/logs/shard.log" logAppend: true # 存储相关 storage: journal: enabled: true dbPath: "/data/services/mongodb-shard1/data" directoryPerDB: true wiredTiger: engineConfig: cacheSizeGB: 1 directoryForIndexes: true collectionConfig: blockCompressor: zlib indexConfig: prefixCompression: true # 网络相关 net: bindIp: 192.168.200.101,127.0.0.1 port: 27001 # 复制相关 replication: oplogSizeMB: 2048 replSetName: my_shard_1 # 分片相关 sharding: clusterRole: shardsvr # 进程相关 processManagement: fork: true pidFilePath: "/data/services/mongodb-shard1/logs/shard.pid" EOF
启动节点:
mongod -f /data/services/mongodb-shard1/config/shard.conf
在 101 上登录配置复制集:
mongo --port 27001
配置:注意蓝色部分为我们配置文件中定义的。
use admin config = {_id: "my_shard_1", members:[ {_id: 0, host: '192.168.200.101:27001'}, {_id: 1, host: '192.168.200.102:27001'}, {_id: 2, host: '192.168.200.103:27001', "arbiterOnly": true} ]} rs.initiate(config) rs.status()
rs.isMaster()
结果如图:

5. 101-103 节点构建 shard 2 集群,和 1 大致相同,注意目录,my_shard_2 名字,端口就行。
config = {_id: "my_shard_2", members:[
{_id: 0, host: '192.168.200.101:27002', "arbiterOnly": true},
{_id: 1, host: '192.168.200.102:27002'},
{_id: 2, host: '192.168.200.103:27002'}
]}
在 102 上面登录初始化复制集,结果如下:

6. 101-103 节点配置 config:
配置文件:红色部分为不通节点需要修改的,蓝色部分为需要注意的
cat > /data/services/mongodb-config/config/config.conf << EOF # 系统相关 systemLog: destination: file path: "/data/services/mongodb-config/logs/config.log" logAppend: true # 存储相关 storage: journal: enabled: true dbPath: "/data/services/mongodb-config/data" directoryPerDB: true wiredTiger: engineConfig: cacheSizeGB: 1 directoryForIndexes: true collectionConfig: blockCompressor: zlib indexConfig: prefixCompression: true # 网络相关 net: bindIp: 192.168.200.101,127.0.0.1 port: 28001 # 复制相关 replication: oplogSizeMB: 2048 replSetName: configReplSet # 分片相关 sharding: clusterRole: configsvr # 进程相关 processManagement: fork: true pidFilePath: "/data/services/mongodb-config/logs/config.pid" EOF
启动服务:
mongod -f /data/services/mongodb-config/config/config.conf
在 103 登录节点初始化:
mongo --port 28001 admin
配置:
config = {_id: "configReplSet", members:[
{_id: 0, host: '192.168.200.101:28001'},
{_id: 1, host: '192.168.200.102:28001'},
{_id: 2, host: '192.168.200.103:28001'}
]}
rs.initiate(config)
rs.isMaster()
结果如图:

7. 此时 101-103 三台服务器的服务运行如下:

8. 此时三个集群以及建立完成,但是它们是完全隔离的三个集群。所以需要另外一个东西把它们关联起来。
在 104 上面新增 mongos:
cd /data/services/
mkdir -p mongodb-mongos1/{data,logs,config}
添加配置文件:注意红色部分,名称,还有 config 集群各个节点的地址
cat > /data/services/mongodb-mongos1/config/mongos.conf << EOF # 系统相关 systemLog: destination: file path: "/data/services/mongodb-mongos1/logs/mongos.log" logAppend: true # 网络相关 net: bindIp: 192.168.200.104,127.0.0.1 port: 29001 # 分片相关 sharding: configDB: configReplSet/192.168.200.101:28001,192.168.200.102:28001,192.168.200.103:28001 # 进程相关 processManagement: fork: true pidFilePath: "/data/services/mongodb-mongos1/logs/mongos.pid" EOF
启动节点:注意这里启动节点和启动 mongodb 不同
mongos -f /data/services/mongodb-mongos1/config/mongos.conf
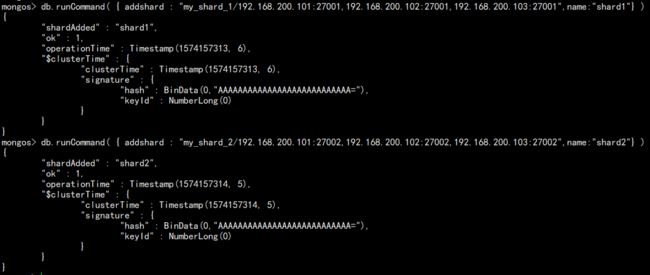
9. 连接 mongos 添加 shard:
mongo --port 29001 admin
配置:
db.runCommand( { addshard : "my_shard_1/192.168.200.101:27001,192.168.200.102:27001,192.168.200.103:27001",name:"shard1"} )
db.runCommand( { addshard : "my_shard_2/192.168.200.101:27002,192.168.200.102:27002,192.168.200.103:27002",name:"shard2"} )
如图:
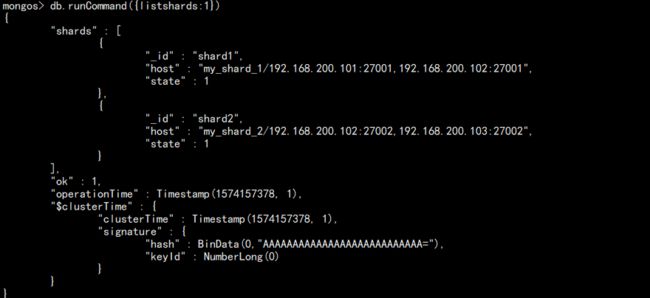
查看分片:
db.runCommand({listshards:1})
如图:
也可以查看分片集群状态:
sh.status()
至此,分片集群搭建完成!
使用集群
当我们在存数据的时候,加入一张表有一千万数据,按照系统自带的分片策略,可能导致多个 shard 集群数据不均,然后整个集群的性能得不到充分的利用。
针对这个问题,mongdb 目前提供了两种分片规则配置:Range 和 Hash。
Range:根据某个字段将某范围内的放到指定节点,如 id < 50000 的放到集群 1 这样。该分片方式存在一个问题,因为数据的热度可能不一样,有可能最新的数据访问频繁程度高一些,这样导致请求大多可能都落在数据比较新的集群,导致服务器忙的忙死,闲的闲死,无法做到负载的均衡。
Hash:通过一定的算法将数据存到某个集群,这样的数据是随机的,也不知道访问的数据到底在哪一个。这样数据量越多,那么服务器性能占用就越接近均衡。
Range 配置(mongos 节点):
1. 给指定库(hello)开启分片功能:
use admin db.runCommand({enablesharding: "hello"})
2. 给指定库(hello)下面指定表(t1)创建索引和分片:
# 创建索引 use hello db.t1.ensureIndex({id:1}) # 开启分片 use admin db.runCommand({shardcollection: "hello.t1", key: {id:1}})
3. 录入100万数据:注意,如果数据量太少可能只会落在一个节点
use hello
for(i=1;i<=1000000;i++){db.t1.insert({"id":i,"name":"zhangsan","date":new Date()})}
查看记录数量:
db.t1.count()
4. 去分片节点查看数据:
注意,当数据量太小装满一个 chunk,所以最终数据还是在一个 shard 上。
Hash 分片配置(推荐使用):
1. 给指定库(world)开启分片功能:
use admin db.runCommand({enablesharding: "world"})
2. 给指定库(world)下面指定表(t2)创建索引和分片:
# 创建索引 use world db.t2.ensureIndex({id: "hashed"}) # 分片 use admin sh.shardCollection("world.t2", {id: "hashed"})
3. 录入 10 万数据:
use world
for(i=1;i<100000;i++){db.t2.insert({"id":i,"name":"zhangsan","date":new Date()})}
4. 登录 shard 节点查看数据:
use world
db.t2.count()
shard 1:
![]()
shard 2:
![]()
可以看到,大致相当,几百条数据差异不用在意。
其它命令:
# 查看所有开启分片的库 db.databases.find( { "partitioned": true } ) # 查看分片的键 db.collections.find().pretty()
balancer
mongodb 会自动巡查所有 shard 节点上的 chunk 情况,并自动迁移。如节点删除的时候。
但是迁移存在一个问题,会产生大量的 IO,如果是在业务繁忙期间,会影响业务。
于是我们便需要 balancer 来对 chunk 迁移的时间进行调整。
设置方法:
use config # 查看状态 sh.getBalancerState() # 开启 sh.setBalancerState(true) # 设置时间 db.settings.update({ _id : "balancer" }, { $set : { activeWindow : { start : "3:00", stop : "5:00" } } }, true ) # 查看设置结果 sh.getBalancerWindow()
当然,也可以通过查看 shard 状态查看:
sh.status()
如图:
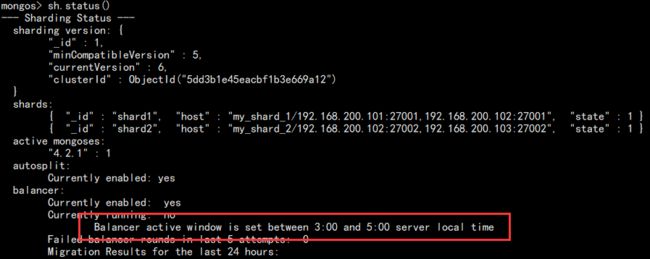
该操作需要避开备份和业务高峰期!至此,分破集群大致说到这里。