学过决策树的人大概都知道,构造树可以用基尼系数。那问题来了,衡量收入分配差异也可以用基尼系数,这两个基尼系数计算过程差异很大,但名称却一样,这是怎么回事呢?
我也一直有这个疑惑,最近查了一下才搞明白。衡量收入分配差异状况的那个,是真正的基尼系数(Gini Coefficient);用来构造决策树的那个,准确叫法是基尼不纯度(Gini Impurity)。
我特意查了下,李航老师的《统计学方法》和周志华老师的《机器学习》,都称基尼不纯度为基尼指数(Gini Index)。其实这种叫法也说得过去,指数的英文是Index,是有度量、表征的意思。把一个有度量、表征作用的变量叫做指数,似乎也合理。
但是网上的资料大多都把基尼不纯度称为基尼系数,这个叫法就不准确了。本文就带你看一下这两个概念。
一.基尼系数
一般所说的基尼系数都是指收入基尼系数。除了用于衡量收入,基尼系数也可以用于一些其他领域,是意大利经济学家基尼于1922年提出的。
我们一般从概念和公式开始,再结合场景去进行理解一个指标,但这正好和解决实际问题的过程相反。实际中一般是先有场景,为解决场景问题,才能得出概念和公式。现在从场景问题出发,看一下洛基尼系数是怎么得出来的。
问题
假设有个国家,人不多,一两亿吧。已知这个国家每个人的的收入,且按收入从低到高排好了顺序,需要衡量这个国家的贫富差距状况。
我想一般人都和我一样,可以想到考察分布的均匀程度,想到用方差。现在看,计算各类统计量很容易啊,调用一个函数就搞定了。
但如果再加一个假设,你穿越到了100年前,没有计算机和手机,只能手算。
一个国家上亿的人口,去计算方差?崩溃了!小心脏瞬间碎了!
解决方案之洛伦兹曲线
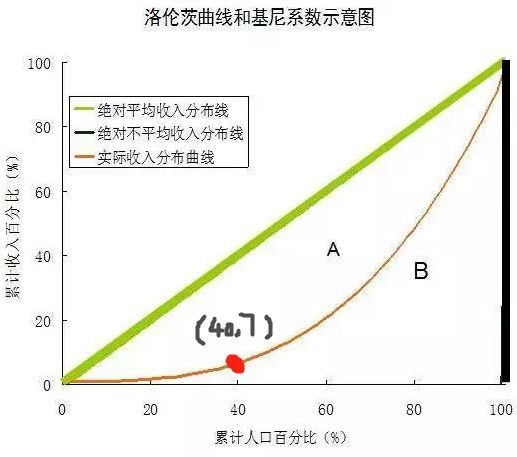
首先,统计学家洛伦兹在1905年提出了洛伦兹曲线。这是怎么一条曲线呢?该怎么画呢?
第一步,确定坐标轴,横坐标是累积人口百分比,纵坐标是累积收入百分比。第二步,计算全国总人口数和总收入。第三步,从收入最低的人开始,逐个人累积,并计算两个累积量,并将每次计算的点画到坐标轴上。第四步,将所有点平滑的连起来。
这样就画出了洛伦兹曲线,就是下图黄色的曲线。过程比计算方差容易多了多,没有平方这种崩溃的计算。
这条曲线可以衡量贫富差距程度,比如下图红点的坐标是(40,7),其含义是全国最贫困的40%人的只能拿到全国7%的钱。
如果红点下移,代表分到的钱更少,也就是贫富差距越大。所以说,洛伦兹曲线弯曲程度越大,代表贫富差距越大。
解决方案之基尼系数
洛伦兹曲线可以反映贫富差距,但是我们好像更习惯数值型的指标。基尼系数就是个数值型指标,是在洛伦兹曲线基础上计算的。
如果全国的人收入都相同,那里洛伦兹曲线就会是绿线。设绿线和黄线之间的面积为A,黄线和两个坐标轴之间面积为B,基尼系数为A/(A+B)。
基尼系数是一个比例,所以在0和1之间;如果黄线和绿线重合,那么A为0,所以基尼系数为0,代表无贫富差距;如果黄线和坐标轴重合,那么B为0,基尼系数为1,代表最大的贫富差距。
基尼系数多少才合适
国际上认为基尼系数合理的范围是0.2~0.4,太小不好,代表社会收入差距太小,干好干坏都一样,人们会丧失动力,社会也就没有了活力;基尼系数太大也不好,太大就会“朱门酒肉臭,路有冻死骨”,造成社会不稳定。
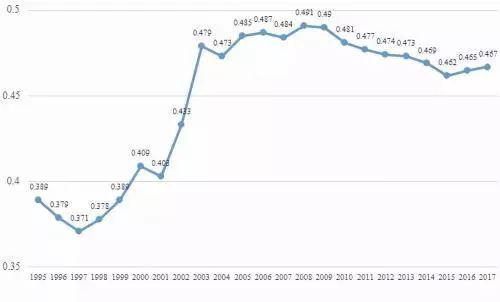
看一下我国基尼系数的情况,如下图。可看出,我国的基尼系数是一个先增后减的过程,这意味着是一部分人先富起来,逐渐达到共同富裕。
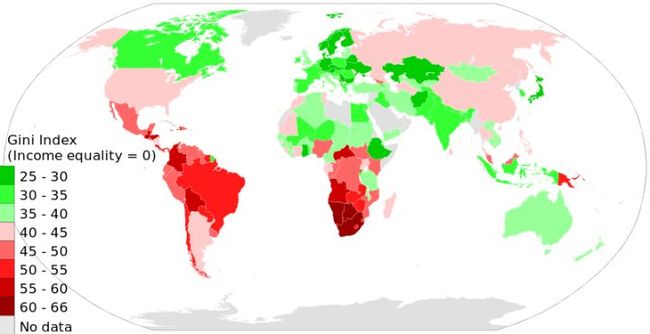
看一下世界各国基尼系数,虽然不是最新的图,但是也能看出一些问题。让我有点意外的是,印度竟然是绿色的,感兴趣的可以网上搜一下原因。
二.基尼不纯度
基尼不纯度的故事就比基尼系数少多了。上一篇文章《【AI基础】什么是信息?什么是熵?》中讲到,熵H(X)的计算公式为:
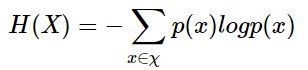
。对其中的-log p(x)进行泰勒展开后,忽略高阶项(因为p小于1,所以高阶近似于0),就得到了基尼不纯度的公式:
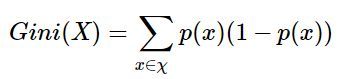
。
从基尼不纯度的计算可以看出,它的计算更加方便,是熵的一个近似值。所以含义和熵差不多,可以衡量不确定性的大小,可以衡量杂乱程度也就是不纯度。
另外,对于二分类问题,还可以画出熵、基尼不纯度、分类误差率与p之间的图形。为了更好反应变量关系,曲线中的熵除以2。(其中分类误差率可以理解成分错的最大概率。为更准确,对于不确定的样本肯定会向概率大的类别中分,所以误差率就是较小的类别概率。)
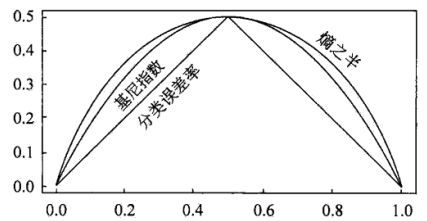
可以看出,p为0或1时,熵、基尼不纯度、和分类误差率都为0,代表不存在不确定性;当p为0.5时,也就是两个类别的概率相等时,熵、基尼不纯度、和分类误差率最大,不确定性最大。
三.基尼指数、基尼不纯度的关系
这两个指标,计算过程和含义,差异都是挺大的,但是为啥后来搞混了呢。我猜想,两个指标都是一种度量和表征,所以都可以称为“指数”;而又都姓“基尼”,所以用着用着就都成为“基尼指数”了;再用着用着,就分不清彼此了。希望本文能帮您把关系理顺。
往期回顾
【AI基础】什么是信息?什么是熵?
【PCA】上证50主成分分析
【PCA】主成分分析介绍
【定价】二叉树(CRR)欧式/美式期权定价的原理及Python实现
【定价】用蒙特卡洛模拟为零息债券定价
【智能投顾】两篇研报笔记
知乎专栏:AI和金融模型
原创作品,未标明作者不得转载。

作者公众号