一,pyspider
pyspider的设计基础是:以python脚本驱动的抓取环模型爬虫
通过python脚本进行结构化信息的提取,follow链接调度抓取控制,实现最大的灵活性
通过web化的脚本编写、调试环境。web展现调度状态
抓取环模型成熟稳定,模块间相互独立,通过消息队列连接,从单进程到多机分布式灵活拓展
pyspider的架构主要分为 scheduler(调度器), fetcher(抓取器), processor(脚本执行):
各个组件间使用消息队列连接,除了scheduler是单点的,fetcher 和 processor 都是可以多实例分布式部署的。 scheduler 负责整体的调度控制
任务由 scheduler 发起调度,fetcher 抓取网页内容, processor 执行预先编写的python脚本,输出结果或产生新的提链任务(发往 scheduler),形成闭环。
每个脚本可以灵活使用各种python库对页面进行解析,使用框架API控制下一步抓取动作,通过设置回调控制解析动作。
二,Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy 使用了 Twisted 异步网络库来处理网络通讯。整体架构大致如下
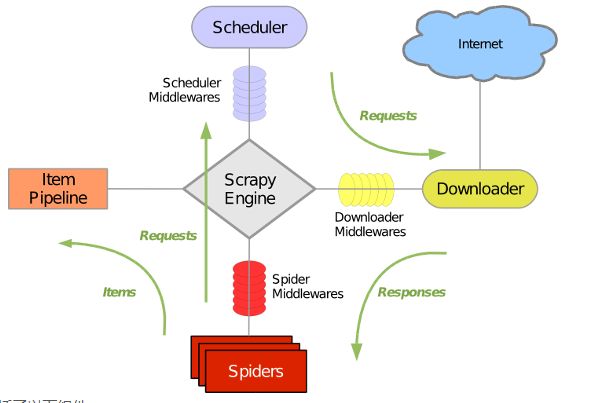
Scrapy主要包括了以下组件:
引擎(Scrapy): 用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader): 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
下载器中间件(Downloader Middlewares): 位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
爬虫中间件(Spider Middlewares): 介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。
调度中间件(Scheduler Middewares): 介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下
首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
然后,爬虫解析Response
若是解析出实体(Item),则交给实体管道进行进一步的处理。
若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
pysipder环境搭建:
http://docs.pyspider.org/en/latest/
pip install pyspider
首先要安装phantomjs
安装好了之后命令行输入pyspider all启动
http://localhost:5000
支持多线程爬取、JS动态解析,提供了可操作界面、出错重试、定时爬取等等的功能,使用非常人性化。
scrapy环境搭建:
pip installpyOpenSSL
安装pywin32
https://sourceforge.net/projects/pywin32/files/pywin32/
import win32com验证
pip install lxml
pip install scrapy