概括
我们公司使用spark已经有段时间了,现在我对我之前的学习知识进行整理,以便记录和大家共同学习,有一部分是网上摘抄,感谢网络共享大神。本文只是针对spark2,spark基本概念,简而言之就是:spark专门为大规模数据处理而设计的快速通用的计算引擎,是apache的一个开源项目。是一种跟Hadoop相似的通用分布式并行计算框架,但是spark是基于内存计算的分布式执行框架,在执行速度上优于hadoop,并且提供了一个全面、统一的框架用于管理各种有着不同性质的数据集和数据源的大数据处理需求。
SPARK架构和生态
spark主要包括Spark Core和在Spark Core基础上建立的应用框架:数据分析引擎SparkSQL、图计算框架GraphX、机器学习库MLlib、流计算引擎Spark Streaming。Core库主要包括上下文(Spark Context)、数据抽象集(RDD、DataFrame和DataSet)、调度器(Scheduler)、洗牌(shuffle)和序列化器(Serializer)等。
在Core库之上就根据业务需求分为用于交互式查询的SQL、实时流处理Streaming、机器学习Mllib和图计算GraphX四大框架,除此外还有一些其他实验性项目如Tachyon、BlinkDB和Tungsten等。Hdfs是Spark主要应用的持久化存储系统。Spark 体系结构如下图。
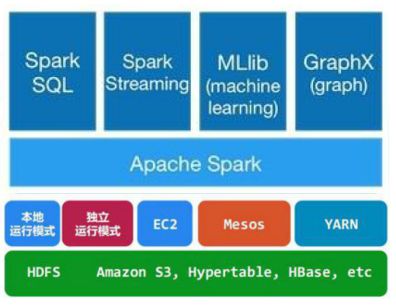
Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveSQL)与Spark进行交互的API,每个数据表被当作一个RDD,SparkSQL查询被转换为Spark操作。
Spark Streaming:对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
MLlib:一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
GraphX:控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
SPARK核心概念

client:客户端进程,负责提交作业。
Driver:一个spark作业有一个Spark Context,一个Spark Context对应一个Driver进程,作业的main函数运行在Driver中。Driver主要负责Spark作业的解析,以及通过DAGScheduler划分stage,将Stage转化成TaskSet提交给TaskScheduler任务调度器,进而调度Task到Executor上执行。
Executor:负责执行driver分发的task任务。集群中的一个节点可以启动多个Executor,每个Executor可以执行多个Task任务。
Cache:Spark提供了对RDD不同级别的缓存策略,分别可以缓存到内存,磁盘,外部分布式内存存储系统Tachyon等。
Application:提交的一个作业就是一个application,一个application只有一个driver。
Job:RDD执行一次Action操作就会生成一个Job。
Task:spark运行的基本单位,负责处理RDD的计算逻辑。
Stage:DAGScheduler将Job划分成多个Stage,Stage的划分界限为Shuffle的产生,Shuffle标志着一个stage的结束和下一个stage的开始。
TaskSet:划分的stage会转换一组相关联的任务集,下面会详细讲解。
RDD(Resilient Distributed Dataset):弹性分布式集,可以理解为一种只读的分布式多分区的数组。
DAG(Directed Acyclic Graph):有向无环图,Spark实现了DAG的计算模型,DAG计算模型是指将一个计算任务按照计算规则分解为若干个子任务,这些子任务之间根据逻辑关系构建成有向无环图。
SPARK提交运行流程
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。
1、Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等)
2、Cluster manager分配应用程序执行需要的资源,在Worker节点上创建Executor
3、SparkContext 将程序代码(jar包或者python文件)和Task任务发送给Executor执行,并收集结果给Driver。
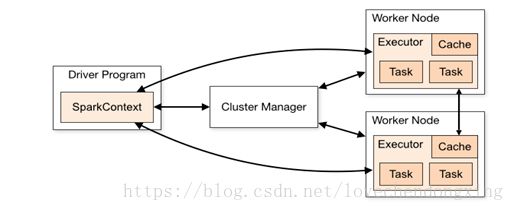
spark详细运行过程入下:
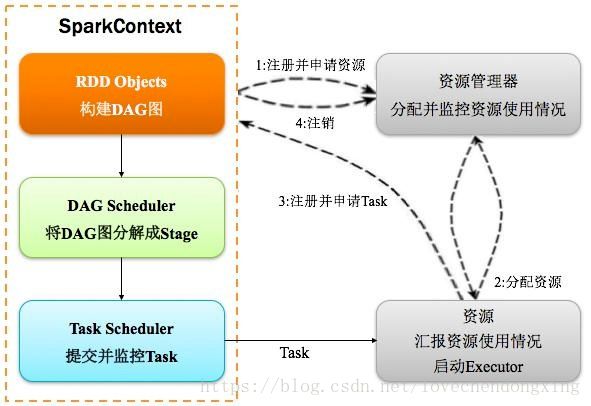
spark运行详细流程:
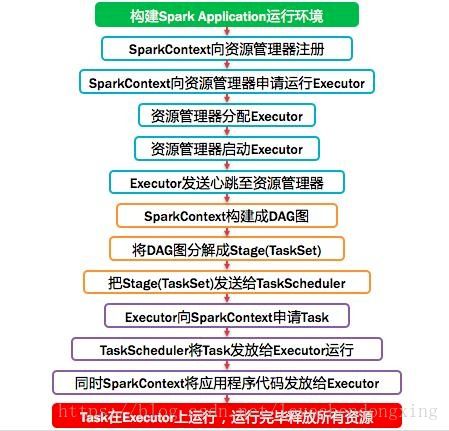
涉及的几个定义和详细的运行过程:
1,application:spark应用程序
指的是用户编写的Spark应用程序,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。 Spark应用程序,由一个或多个作业JOB组成,如下图所示
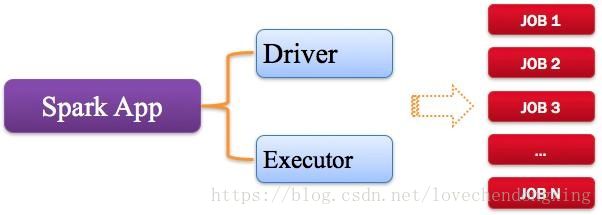
2,driver驱动程序
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示。

3,Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Haddop Yarn,由Yarn中的ResearchManager负责资源的分配;Messos,由Messos中的Messos Master负责资源管理。
4,Executor:执行器
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示。
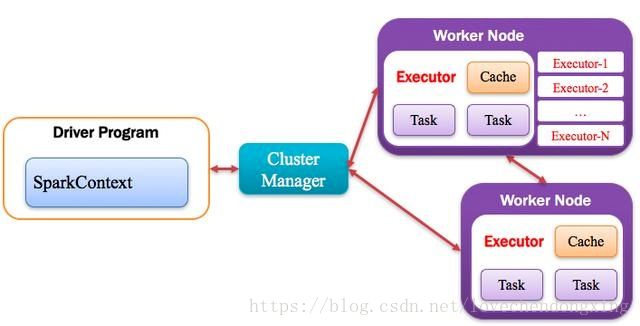
5,work节点:计算节点
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示。
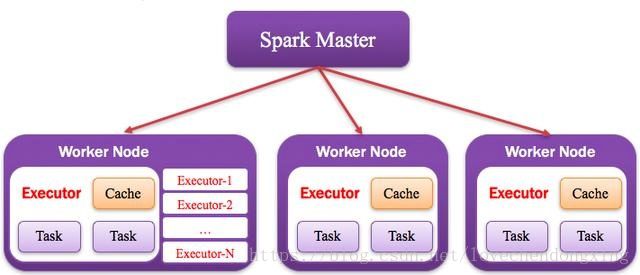
6,DAGScheduler:有向无环图调度器
基于DAG划分Stage 并以TaskSet的形势提交Stage给TaskScheduler;负责将作业拆分成不同阶段的具有依赖关系的多批任务;最重要的任务之一就是:计算作业和任务的依赖关系,制定调度逻辑。在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler。

7,TaskScheduler:任务调度器
将Taskset提交给worker(集群)运行并回报结果;负责每个具体任务的实际物理调度。如图所示。

8,Job:作业
由一个或多个调度阶段所组成的一次计算作业;包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation。如图所示。
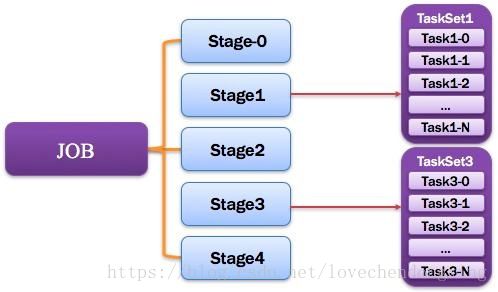
9,Stage:调度阶段
一个任务集对应的调度阶段;每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;Stage分成两种类型ShuffleMapStage、ResultStage。如图所示。
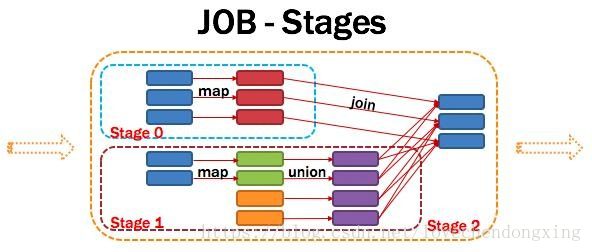
Application多个job多个Stage:Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:Stage划分的依据就是宽依赖,何时产生宽依赖,reduceByKey, groupByKey等算子,会导致宽依赖的产生。
核心算法:从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。Spark内核会从触发Action操作的那个RDD开始从后往前推,首先会为最后一个RDD创建一个stage,然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。然后依次类推,继续继续倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
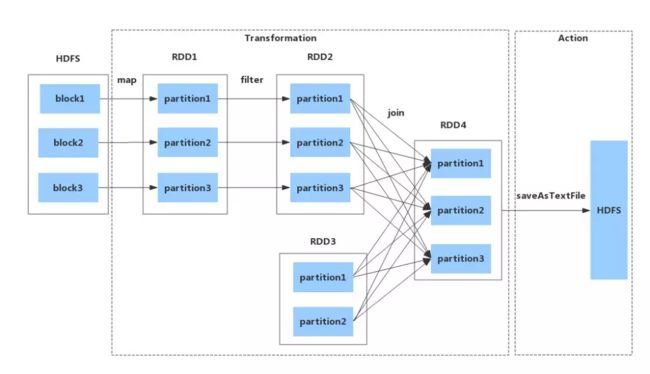
将DAG划分为Stage剖析:如上图,从HDFS中读入数据生成3个不同的RDD,通过一系列transformation操作后再将计算结果保存回HDFS。可以看到这个DAG中只有join操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage. 同时我们可以注意到,在图中Stage2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,通过map操作生成的partition可以不用等待整个RDD计算结束,而是继续进行union操作,这样大大提高了计算的效率。
10,TaskSet:任务集
由一组关联的,但相互之间没有Shuffle依赖关系的任务所组成的任务集。如图所示。
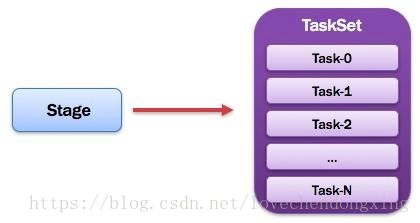
提示:
1)一个Stage创建一个TaskSet;
2)为Stage的每个Rdd分区创建一个Task,多个Task封装成TaskSet。
11,Task:任务
被送到某个Executor上的工作任务;单个分区数据集上的最小处理流程单元(单个stage内部根据操作数据的分区数划分成多个task)。如图所示。
总体如图所示:

SPARK运行模式
1,测试或实验性质的本地运行模式 (单机)
该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题。其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.如下:
spark-submit 和 spark-submit --master local 效果是一样的
(同理:spark-shell 和 spark-shell --master local 效果是一样的)
spark-submit --master local[4] 代表会有4个线程(每个线程一个core)来并发执行应用程序。
那么,这些线程都运行在什么进程下呢?后面会说到,请接着往下看。运行该模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用,而不用启动Spark的Master、Worker守护进程( 只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。
那么,这些执行任务的线程,到底是共享在什么进程中呢?
我们用如下命令提交作业:
spark-submit --class JavaWordCount --master local[10] JavaWordCount.jar file:///tmp/test.txt
可以看到,在程序执行过程中,只会生成一个SparkSubmit进程。

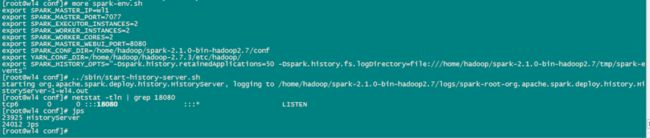
这里有个小插曲,因为driver程序在应用程序结束后就会终止,那么如何在web界面看到该应用程序的执行情况呢,需要如此这般:(如下图所示)
先在spark-env.sh 增加SPARK_HISTORY_OPTS;
然后启动start-history-server.sh服务;
就可以看到启动了HistoryServer进程,且监听端口是18080。
之后就可以在web上使用http://hostname:18080愉快的玩耍了。
2,测试或实验性质的本地伪集群运行模式(单机模拟集群)
这种运行模式,和Local[N]很像,不同的是,它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多个线程只能在一个进程下委屈求全的共享资源。通常也是用来验证开发出来的应用程序逻辑上有没有问题,或者想使用Spark的计算框架而没有太多资源。
用法是:提交应用程序时使用local-cluster[x,y,z]参数:x代表要生成的executor数,y和z分别代表每个executor所拥有的core和memory数。
spark-submit --master local-cluster[2, 3, 1024](同理:spark-shell --master local-cluster[2, 3, 1024]用法也是一样的)
上面这条命令代表会使用2个executor进程,每个进程分配3个core和1G的内存,来运行应用程序。可以看到,在程序执行过程中,会生成如下几个进程:

SparkSubmit依然充当全能角色,又是Client进程,又是driver程序,还有点资源管理的作用。生成的两个CoarseGrainedExecutorBackend,就是用来并发执行程序的进程。它们使用的资源如下。
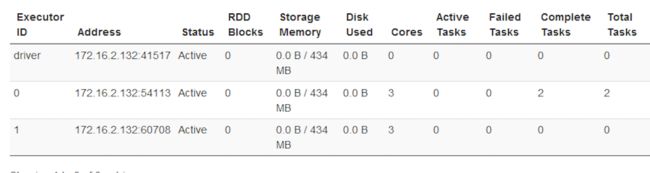
运行该模式依然非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用。而不用启动Spark的Master、Worker守护进程( 只有集群的standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非你要用到HDFS),这是和其他模式的区别哦,要记住才能理解。下面说说集群上的运行模式。
3,Spark自带Cluster Manager的Standalone Client模式(集群)
和单机运行的模式不同,这里必须在执行应用程序前,先启动Spark的Master和Worker守护进程。不用启动Hadoop服务,除非你用到了HDFS的内容。
start-master.sh
start-slave.sh -h hostname url:master
图省事,可以在想要做为Master的节点上用start-all.sh一条命令即可,不过这样做,和上面的分开配置有点差别,以后讲到数据本地性如何验证时会说。
启动的进程如下:(其他非Master节点上只会有Worker进程)

这种运行模式,可以使用Spark的8080 web ui来观察资源和应用程序的执行情况了。
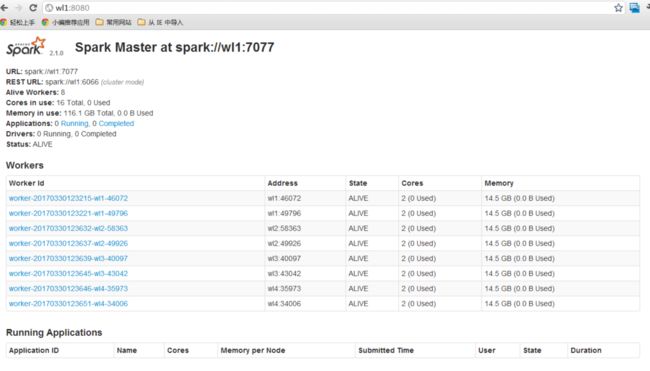
可以看到,当前环境下,我启动了8个worker进程,每个可使用的core是2个,内存没有限制。言归正传,用如下命令提交应用程序。
spark-submit --master spark://wl1:7077
或者 spark-submit --master spark://wl1:7077 --deploy-mode client
代表着会在所有有Worker进程的节点上启动Executor来执行应用程序,此时产生的JVM进程如下:(非master节点,除了没有Master、SparkSubmit,其他进程都一样)

Master进程做为cluster manager,用来对应用程序申请的资源进行管理;
SparkSubmit 做为Client端和运行driver程序;
CoarseGrainedExecutorBackend 用来并发执行应用程序;
注意,Worker进程生成几个Executor,每个Executor使用几个core,这些都可以在spark-env.sh里面配置,此处不在啰嗦。

4,spark自带cluster manager的standalone cluster模式(集群)
这种运行模式和上面第3个还是有很大的区别的。使用如下命令执行应用程序(前提是已经启动了spark的Master、Worker守护进程)不用启动Hadoop服务,除非你用到了HDFS的内容。
spark-submit --master spark://wl1:6066 --deploy-mode cluster
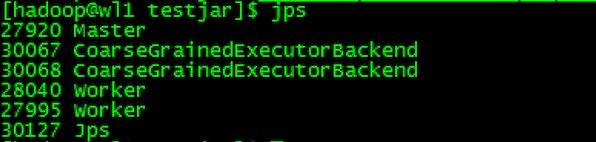
各节点启动的JVM进程情况如下:master进程
提交应用程序的客户端上的进程

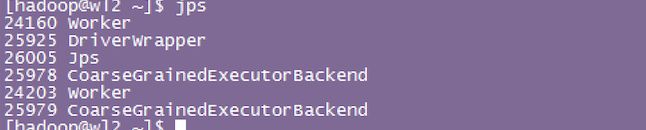
某worker节点上的
客户端的SparkSubmit进程会在应用程序提交给集群之后就退出(区别1)
Master会在集群中选择一个Worker进程生成一个子进程DriverWrapper来启动driver程序(区别2)
而该DriverWrapper 进程会占用Worker进程的一个core,所以同样的资源下配置下,会比第3种运行模式,少用1个core来参与计算(观察下图executor id 7的core数)(区别3)

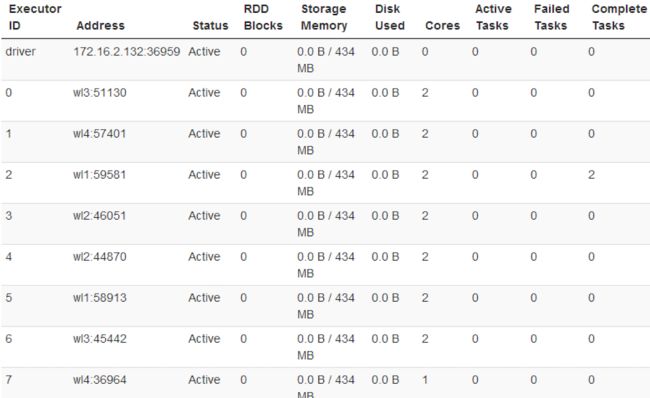
5,基于YARN的Resource Manager的Client模式(集群)
现在越来越多的场景,都是Spark跑在Hadoop集群中,所以为了做到资源能够均衡调度,会使用YARN来做为Spark的Cluster Manager,来为Spark的应用程序分配资源。在执行Spark应用程序前,要启动Hadoop的各种服务。由于已经有了资源管理器,所以不需要启动Spark的Master、Worker守护进程。相关配置的修改,请自行研究。使用如下命令执行应用程序。
spark-submit --master yarn 或者 spark-submit --master yarn --deploy-mode client
提交应用程序后,各节点会启动相关的JVM进程,如下:在Resource Manager节点上提交应用程序,会生成SparkSubmit进程,该进程会执行driver程序。

RM会在集群中的某个NodeManager上,启动一个ExecutorLauncher进程,来做为ApplicationMaster。另外,也会在多个NodeManager上生成CoarseGrainedExecutorBackend进程来并发的执行应用程序。

对应的YARN资源管理的单元Container,关系如下:
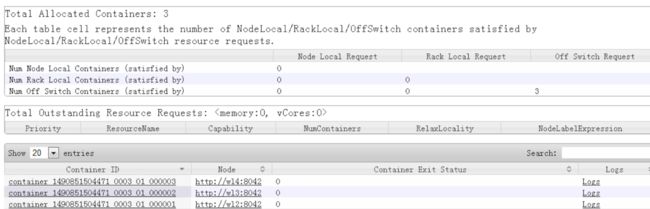
为ApplicationMaster生成了容器 000001;为CoarseGrainedExecutorBackend生成了容器 000002-000003。
6,基于YARN的Resource Manager的Custer模式(集群)
使用如下命令执行应用程序:
spark-submit --master yarn --deploy-mode cluster
和第5种运行模式,区别如下:在Resource Manager端提交应用程序,会生成SparkSubmit进程,该进程只用来做Client端,应用程序提交给集群后,就会删除该进程。

Resource Manager在集群中的某个NodeManager上运行ApplicationMaster,该AM同时会执行driver程序。紧接着,会在各NodeManager上运行CoarseGrainedExecutorBackend来并发执行应用程序。

应用程序的结果,会在执行driver程序的节点的stdout中输出,而不是打印在屏幕上。对应的YARN资源管理的单元Container,关系如下。

为ApplicationMaster生成了容器 000001
为CoarseGrainedExecutorBackend生成了容器 000002-000003
RDD介绍
RDD具有几个特性:只读、多分区、分布式,可以将HDFS块文件转换成RDD,也可以由一个或多个RDD转换成新的RDD,失效自动重构。基于这些特性,RDD在分布式环境下能够被高效地并行处理。
计算类型:
在Spark中RDD提供Transformation和Action两种计算类型。Transformation操作非常丰富,采用延迟执行的方式,在逻辑上定义了RDD的依赖关系和计算逻辑,但并不会真正触发执行动作,只有等到Action操作才会触发真正执行操作。Action操作常用于最终结果的输出。
常用的Transformation操作有:
map (func):接收一个处理函数并行处理源RDD中的每个元素,返回与源RDD元素一一对应的新RDD
filter (func):并行处理源RDD中的每个元素,接收一个处理函数,并根据定义的规则对RDD中的每个元素进行过滤处理,返回处理结果为true的元素重新组成新的RDD
flatMap (func):flatMap是map和flatten的组合操作,与map函数相似,不过map函数返回的新RDD包含的元素可能是嵌套类型,flatMap接收一个处理嵌套会将嵌套类型的元素展开映射成多个元素组成新的RDD
mapPartitions (func):与map函数应用于RDD中的每个元素不同,mapPartitions应用于RDD中的每个分区。mapPartitions函数接收的参数为func函数,func接收参数为每个分区的迭代器,返回值为每个分区元素处理之后组成的新的迭代器,func会作用于分区中的每一个元素。有一种典型的应用场景,比如待处理分区中的数据需要写入到数据库,如果使用map函数,每一个元素都会创建一个数据库连接对象,非常耗时并且容易引起问题发生,如果使用mapPartitions函数只会在分区中创建一个数据库连接对象,性能提高明显
mapPartitionsWithIndex(func):作用与mapPartitions函数相同,只是接收的参数func函数需要传入两个参数,分区的索引作为第一个参数传入,按照分区的索引对分区中元素进行处理
union (otherDataset):将两个RDD进行合并,返回结果为RDD中元素(不去重)
intersection (otherDataset):对两个RDD进行取交集运算,返回结果为RDD无重复元素
distinct ([numTasks])):对RDD中元素去重
groupByKey ([numTasks]):在KV类型的RDD中按Key分组,将相同Key的元素聚集到同一个分区内,此函数不能接收函数作为参数,只接收一个可选参数任务数,所以不能在RDD分区本地进行聚合计算,如需按Key对Value聚合计算,只能对groupByKey返回的新RDD继续使用其他函数运算
reduceByKey (func, [numTasks]):对KV类型的RDD按Key分组,接收两个参数,第一个参数为处理函数,第二个参数为可选参数设置reduce的任务数。reduceByKey函数能够在RDD分区本地提前进行聚合运算,这有效减少了shuffle过程传输的数据量。相对于groupByKey函数更简洁高效
aggregateByKey (zeroValue)(seqOp, combOp):对KV类型的RDD按Key分组进行reduce计算,可接收三个参数,第一个参数是初始化值,第二个参数是分区内处理函数,第三个参数是分区间处理函数
sortByKey ([ascending], [numTasks]):对KV类型的RDD内部元素按照Key进行排序,排序过程会涉及Shuffle
join (otherDataset, [numTasks]):对KV类型的RDD进行关联,只能是两个RDD之间关联,超过两个RDD关联需要使用多次join函数,join函数只会关联出具有相同Key的元素,相当于SQL语句中的inner join
cogroup (otherDataset, [numTasks]):对KV类型的RDD进行关联,cogroup处理多个RDD关联比join更加优雅,它可以同时传入多个RDD作为参数进行关联,产生的新RDD中的元素不会出现笛卡尔积的情况,使用fullOuterJoin函数会产生笛卡尔积
coalesce (numPartitions):对RDD重新分区,将RDD中的分区数减小到参数numPartitions个,不会产生shuffle。在较大的数据集中使用filer等过滤操作后可能会产生多个大小不等的中间结果数据文件,重新分区并减小分区可以提高作业的执行效率,是Spark中常用的一种优化手段
repartition (numPartitions):对RDD重新分区,接收一个参数——numPartitions分区数,是coalesce函数设置shuffle为true的一种实现形式
repartitionAndSortWithinPartitions (partitioner):接收一个分区对象(如Spark提供的分区类HashPartitioner)对RDD中元素重新分区并在分区内排序
常用的Action操作及其描述:
reduce(func):处理RDD两两之间元素的聚集操作
collect():返回RDD中所有数据元素
count():返回RDD中元素个数
first():返回RDD中的第一个元素
take(n):返回RDD中的前n个元素
saveAsTextFile(path):将RDD写入文本文件,保存至本地文件系统或者HDFS中
saveAsSequenceFile(path):将KV类型的RDD写入SequenceFile文件,保存至本地文件系统或者HDFS中
countByKey():返回KV类型的RDD每个Key包含的元素个数
foreach(func):遍历RDD中所有元素,接收参数为func函数,常用操作是传入println函数打印所有元素。
从HDFS文件生成Spark RDD,经过map、filter、join等多次Transformation操作,最终调用saveAsTextFile Action操作将结果集输出到HDFS,并以文件形式保存。RDD的流转过程如图。
总结
本人只是总结第一部分,后续还有其他更新,以下是我的摘抄来源链接:
https://www.jianshu.com/p/65a3476757a5?utm_campaign=haruki&utm_content=note&utm_medium=reader_share&utm_source=weixin
https://mp.weixin.qq.com/s?__biz=MjM5ODE1NDYyMA==&mid=2653391961&idx=2&sn=55513d8fb3169b8cb9bf9cc1fdf6bc6b&chksm=bd1c344a8a6bbd5c9fa427821238373aab1678f87a19071dad9ff347cc6a601bcf16983b38ef&mpshare=1&scene=1&srcid=1106IGqzlgCdwM4ojwjfRLa5&sharer_sharetime=1573259546736&sharer_shareid=d40e8d2bb00008844e69867bcfc0d895&key=56629d78eb0c25e48cf34661944bb96db95f7c1d133e4c61480f14c956b8dd8b2a23fe679ef34981b4b37daa6ebffcdd4b25439239d67b85809e02bdb6bfa7d95679382993b4bd432c95e23f86208d88&ascene=1&uin=MTYzNjUwNDcwNg%3D%3D&devicetype=Windows+10&version=62070152&lang=zh_CN&pass_ticket=MMaJxSTFwuVHUR41QNxDR38Nwj%2FzCnD9RtYl67%2BNH3PinGs3tLffeVy9VXQn3JpP