
作者简介:于航,PayPal Senior Software Engineer,在 PayPal 上海负责 Global GRT 平台相关的技术研发工作。曾任职于阿里巴巴、Tapatalk 等企业。freeCodeCamp 上海社区负责人。研究领域主要为前端基础技术架构、Serverless、WebAssembly、LLVM 及编译器等相关方向。
说到 Web 前端开发,我们首先能够想到的是浏览器、HTML、CSS 以及 JavaScript 这些开发时所必备使用的软件工具和编程语言。而在这个专业领域中,作为开发者我们众所周知的是,所有来自前端的数据都是“不可信”的,由于构成前端业务逻辑和交互界面的所有相关代码都是可以被用户直接查看到的,所以我们无法保证我们所确信的某个从前端传递到后端的数据没有被用户曾经修改过。
那么是否有办法可以将前端领域中那些与业务有关的代码(比如数据处理逻辑、验证逻辑等,通常是 JavaScript 代码)进行加密以防止用户进行恶意修改呢?本文我们将讨论这方面的内容。
提到“加密”,我们自然会想到众多与“对称加密”、“非对称加密”以及“散列加密”相关的算法,比如 AWS 算法、RSA 算法与 MD5 算法等。在传统的 B-S 架构下,前端通过公钥进行加密处理的数据可以在后端服务器再通过相应私钥进行解密来得到原始数据,但是对于前端的业务代码而言,由于浏览器本身无法识别运行这些被加密过的源代码,因此实际上传统的加密算法并不能帮助我们解决“如何完全黑盒化前端业务逻辑代码”这一问题。
既然无法完全隐藏前端业务逻辑代码的实际执行细节,那我们就从另一条路以“降低代码可读性”的方式来“伪黑盒化前端业务逻辑代码”。通常的方法有如下几种:
第三方插件
我们所熟知的可用在 Web 前端开发中的第三方插件主要有:Adobe Flash、Java Applet 以及 Silverlight 等。由于历史原因这里我们不会深入介绍基于这些第三方插件的前端业务代码加密方案。其中 Adobe 将于 2020 年完全停止对 Flash 技术的支持,Chrome、Edge 等浏览器也开始逐渐对使用了 Flash 程序的 Web 页面进行阻止或弹出相应的警告。同样的,来自微软的 Silverlight5 也会在 2021 年停止维护,并完全终止后续新版本功能的开发。而 Java Applet 虽然还可以继续使用,但相较于早期上世纪 90 年代末,现在已然很少有人使用(不完全统计)。并且需要基于 JRE 来运行也使得 Applet 应用的运行成本大大提高。
代码混淆
在现代前端开发过程中,我们最常用的一种可以“降低源代码可读性”的方法就是使用“代码混淆”。通常意义上的代码混淆可以压缩原始 ASCII 代码的体积并将其中的诸如变量、常量名用简短的毫无意义的标识符进行代替,这一步可以简单地理解为“去语义化”。以我们最常用的 “Uglify” 和 “GCC (Google Closure Compiler)” 为例,首先是一段未经代码混淆的原始 ECMAScript5 源代码:
let times = 0.1 * 8 + 1;
function getExtra(n) {
return [1, 4, 6].map(function(i) {
return i * n;
});
}
var arr = [8, 94, 15, 88, 55, 76, 21, 39];
arr = getExtra(times).concat(arr.map(function(item) {
return item * 2;
}));
function sortarr(arr) {
for(i = 0; i < arr.length - 1; i++) {
for(j = 0; j < arr.length - 1 - i; j++) {
if(arr[j] > arr[j + 1]) {
var temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return arr;
}
console.log(sortarr(arr));
经过 UglifyJS3 的代码压缩混淆处理后的结果:
let times=1.8;function getExtra(r){return[1,4,6].map(function(t){return t*r})}var arr=[8,94,15,88,55,76,21,39];function sortarr(r){for(i=0;ir[j+1]){var t=r[j];r[j]=r[j+1],r[j+1]=t}return r}arr=getExtra(times).concat(arr.map(function(r){return 2*r})),console.log(sortarr(arr));
经过 Google Closure Compiler 的代码压缩混淆处理后的结果:
var b=[8,94,15,88,55,76,21,39];b=function(a){return[1,4,6].map(function(c){return c*a})}(1.8).concat(b.map(function(a){return 2*a}));console.log(function(a){for(i=0;ia[j+1]){var c=a[j];a[j]=a[j+1];a[j+1]=c}return a}(b));
对比上述两种工具的代码混淆压缩结果我们可以看到,UglifyJS 不会对原始代码进行“重写”,所有的压缩工作都是在代码原有结构的基础上进行的优化。而 GCC 对代码的优化则更靠近“编译器”,除了常见的变量、常量名去语义化外,还使用了常见的 DCE 优化策略,比如对常量表达式(constexpr)进行提前求值(0.1 * 8 + 1)、通过 “inline” 减少中间变量的使用等等。
UglifyJS 在处理优化 JavaScript 源代码时都是以其 AST 的形式进行分析的。比如在 Node.js 脚本中进行源码处理时,我们通常会首先使用 UglifyJS.parse 方法将一段 JavaScript 代码转换成其对应的 AST 形式,然后再通过 UglifyJS.Compressor 方法对这些 AST 进行处理。最后还需要通过 print_to_string 方法将处理后的 AST 结构转换成相应的 ASCII 可读代码形式。UglifyJS.Compressor 的本质是一个官方封装好的 “TreeTransformer” 类型,其内部已经封装好了众多常用的代码优化策略,而通过对 UglifyJS.TreeTransformer 进行适当的封装,我们也可以编写自己的代码优化器。
如下所示我们编写了一个实现简单“常量传播”与“常量折叠”(注意这里其实是变量,但优化形式同 C++ 中的这两种基本优化策略相同)优化的 UglifyJS 转化器。
const UglifyJS = require('uglify-js');
var symbolTable = {};
var binaryOperations = {
"+": (x, y) => x + y,
"-": (x, y) => x - y,
"*": (x, y) => x * y
}
var constexpr = new UglifyJS.TreeTransformer(null, function(node) {
if (node instanceof UglifyJS.AST_Binary) {
if (Number.isInteger(node.left.value) && Number.isInteger(node.right.value)) {
return new UglifyJS.AST_Number({
value: binaryOperations[node.operator].call(this,
Number(node.left.value),
Number(node.right.value))
});
} else {
return new UglifyJS.AST_Number({
value: binaryOperations[node.operator].call(this,
Number(symbolTable[node.left.name].value),
Number(symbolTable[node.right.name].value))
})
}
}
if (node instanceof UglifyJS.AST_VarDef) {
// AST_VarDef -> AST_SymbolVar;
// 通过符号表来存储已求值的变量值(UglifyJS.AST_Number)引用;
symbolTable[node.name.name] = node.value;
}
});
var ast = UglifyJS.parse(`
var x = 10 * 2 + 6;
var y = 4 - 1 * 100;
console.log(x + y);
`);
// transform and print;
ast.transform(constexpr);
console.log(ast.print_to_string());
// output:
// var x=26;var y=-96;console.log(-70);
这里我们通过识别特定的 Uglify AST 节点类型(UglifyJS.AST_Binary / UglifyJS.AST_VarDef)来达到对代码进行精准处理的目的。可以看到,变量 x 和 y 的值在代码处理过程中被提前计算。不仅如此,其作为变量的值还被传递到了表达式 a + b 中,此时如果能够再结合简单的 DCE 策略便可以完成最初级的代码优化效果。类似的,其实通过 Babel 的 @babel/traverse 插件,我们也可以实现同样的效果,其所基于的原理也都大同小异,即对代码的 AST 进行相应的转换和处理。
WebAssembly
关于 Wasm 的基本介绍,这里我们不再多谈。那么到底应该如何利用 Wasm 的“字节码”特性来做到尽可能地做到“降低 JavaScript 代码可读性”这一目的呢?一个简单的 JavaScript 代码“加密”服务系统架构图如下所示:
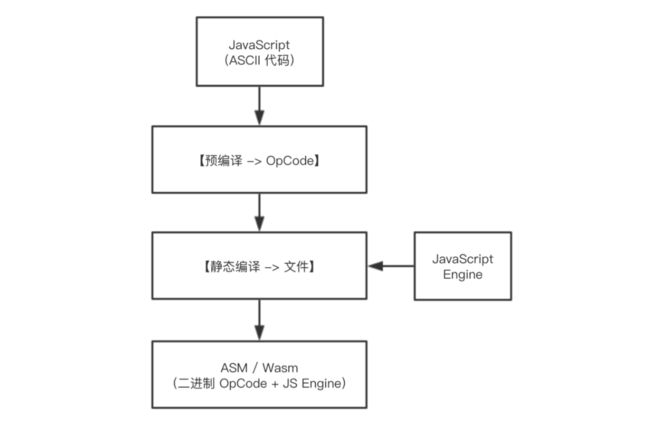
这里整个系统分为两个处理阶段:
第一阶段:先将明文的 JavaScript 代码转换为基于特定 JavaScript 引擎(VM)的 OpCode 代码,这些二进制的 OpCode 代码会再通过诸如 Base64 等算法的处理而转换为经过编码的明文 ASCII 字符串格式;
第二阶段:将上述经过编码的 ASCII 字符串连同对应的 JavaScript 引擎内核代码统一编译成完整的 ASM / Wasm 模块。当模块在网页中加载时,内嵌的 JavaScript 引擎便会直接解释执行硬编码在模块中的、经过编码处理的 OpCode 代码;
比如我们以下面这段处于 Top-Level 层的 JavaScript 代码为例:
[1, 2, 3, 5, 6, 7, 8, 9].map(function(i) {
return i * 2;
}).reduce(function(p, i) {
return p + i;
}, 0);
按照正常的 VM 执行流程,上述代码在执行后会返回计算结果 82。这里我们以 JerryScript 这个开源的轻量级 JavaScript 引擎来作为例子,第一步首先将上述 ASCII 形式的代码 Feed 到该引擎中,然后便可以获得对应该引擎中间状态的 ByteCode 字节码。

然后再将这些二进制的字节码通过 Base64 算法编码成对应的可见字符形式。结果如下所示:
WVJSSgAAABYAAAAAAAAAgAAAAAEAAAAYAAEACAAJAAEEAgAAAAAABwAAAGcAAABAAAAAWDIAMhwyAjIBMgUyBDIHMgY6CCAIwAIoAB0AAToARscDAAAAAAABAAMBAQAhAgIBAQAAACBFAQCPAAAAAAABAAICAQAhAgICAkUBAIlhbQADAAYAcHVkZXIAAGVjAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA==
按照我们的架构思路,这部分被编码后的可见字符串会作为“加密”后的源代码被硬编码到包含有 VM 引擎核心的 Wasm 模块中。当模块被加载时,VM 会通过相反的顺序解码这段字符串,并得到二进制状态的 ByteCode。然后再通过一起打包进来的 VM 核心来执行这些中间状态的比特码。这里我们上述所提到的 ByteCode 实际上是以 JerryScript 内部的 SnapShot 快照结构存在于内存中的。
最后这里给出上述 Demo 的主要部分源码,详细代码可以参考 Github:
#include "jerryscript.h"
#include "cppcodec/base64_rfc4648.hpp"
#include
#include
#define BUFFER_SIZE 256
#ifdef WASM
#include "emscripten.h"
#endif
std::string encode_code(const jerry_char_t*, size_t);
const unsigned char* transferToUC(const uint32_t* arr, size_t length) {
auto container = std::vector();
for (size_t x = 0; x < length; x++) {
auto _t = arr[x];
container.push_back(_t >> 24);
container.push_back(_t >> 16);
container.push_back(_t >> 8);
container.push_back(_t);
}
return &container[0];
}
std::vector transferToU32(const uint8_t* arr, size_t length) {
auto container = std::vector();
for (size_t x = 0; x < length; x++) {
size_t index = x * 4;
uint32_t y = (arr[index + 0] << 24) | (arr[index + 1] << 16) | (arr[index + 2] << 8) | arr[index + 3];
container.push_back(y);
}
return container;
}
int main (int argc, char** argv) {
const jerry_char_t script_to_snapshot[] = u8R"(
[1, 2, 3, 5, 6, 7, 8, 9].map(function(i) {
return i * 2;
}).reduce(function(p, i) {
return p + i;
}, 0);
)";
std::cout << encode_code(script_to_snapshot, sizeof(script_to_snapshot)) << std::endl;
return 0;
}
std::string encode_code(const jerry_char_t script_to_snapshot[], size_t length) {
using base64 = cppcodec::base64_rfc4648;
// initialize engine;
jerry_init(JERRY_INIT_SHOW_OPCODES);
jerry_feature_t feature = JERRY_FEATURE_SNAPSHOT_SAVE;
if (jerry_is_feature_enabled(feature)) {
static uint32_t global_mode_snapshot_buffer[BUFFER_SIZE];
// generate snapshot;
jerry_value_t generate_result = jerry_generate_snapshot(
NULL,
0,
script_to_snapshot,
length - 1,
0,
global_mode_snapshot_buffer,
sizeof(global_mode_snapshot_buffer) / sizeof(uint32_t));
if (!(jerry_value_is_abort(generate_result) || jerry_value_is_error(generate_result))) {
size_t snapshot_size = (size_t) jerry_get_number_value(generate_result);
std::string encoded_snapshot = base64::encode(
transferToUC(global_mode_snapshot_buffer, BUFFER_SIZE), BUFFER_SIZE * 4);
jerry_release_value(generate_result);
jerry_cleanup();
// encoded bytecode of the snapshot;
return encoded_snapshot;
}
}
return "[EOF]";
}
void run_encoded_snapshot(std::string code, size_t snapshot_size) {
using base64 = cppcodec::base64_rfc4648;
auto result = transferToU32(
&(base64::decode(code)[0]),
BUFFER_SIZE);
uint32_t snapshot_decoded_buffer[BUFFER_SIZE];
for (auto x = 0; x < BUFFER_SIZE; x++) {
snapshot_decoded_buffer[x] = result.at(x);
}
jerry_init(JERRY_INIT_EMPTY);
jerry_value_t res = jerry_exec_snapshot(
snapshot_decoded_buffer,
snapshot_size, 0, 0);
// default as number result;
std::cout << "[Zero] code running result: " << jerry_get_number_value(res) << std::endl;
jerry_release_value(res);
}
#ifdef WASM
extern "C" {
void EMSCRIPTEN_KEEPALIVE run_core() {
// encoded snapshot (will be hardcoded in wasm binary file);
std::string base64_snapshot = "WVJSSgAAABYAAAAAAAAAgAAAAAEAAAAYAAEACAAJAAEEAgAAAAAABwAAAGcAAABAAAAAWDIAMhwyAjIBMgUyBDIHMgY6CCAIwAIoAB0AAToARscDAAAAAAABAAMBAQAhAgIBAQAAACBFAQCPAAAAAAABAAICAQAhAgICAkUBAIlhbQADAAYAcHVkZXIAAGVjAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA==";
run_encoded_snapshot(base64_snapshot, 142);
}
}
#endif
当然这里我们只是基于 JerryScript 做了一个利用 Wasm 进行 JavaScript 代码“加密”的最简单 Demo,代码并没有处理边界 Case,对于非 Top-Level 的代码也并没有进行测试。如果需要进一步优化,我们可以思考如何利用 “jerry-libm” 来处理 JavaScript 中诸如 Math.abs 等常见标准库;对于平台依赖的符号(比如 window.document 等平台依赖的函数或变量)怎样通过 Wasm 的导出段与导入段进行处理等等。