1. 论文相关
2018
单样本学习的生成性对抗残差配对网络

2.摘要
2.1 摘要
深度神经网络在许多任务上达到了前所未有的性能水平,并且在大量数据的情况下具有很好的扩展性,但是在小数据模式和像单样本学习这样的任务上的性能仍然落后。虽然最近的研究提出了许多假设,从更好的优化到更复杂的网络结构,但在这项工作中,我们假设有一个可学习的和更具表现力的相似目标是一个必不可少的缺失部分。为了克服这一问题,我们提出了一种基于深度残差网络的网络设计方法,该方法能够有效地计算出这种更具表现力的成对相似目标。进一步,我们认为正则化是小数据学习的关键,并在生成对抗网络的基础上提出了一种新的生成网络,其中判别器是我们的残差成对网络(residual pairwise network)。这通过利用生成的数据样本提供了一个强大的正则化器。该模型能在不可见的类上产生样本的合理变化,并且在小样本分类任务中优于强判别基线。值得注意的是,在具有挑战性的mini-Imagenet数据集上,我们的残差成对网络设计在单样本学习中优于先前的状态,其5-way分类任务的不可见类的准确率超过了55%。
2.2 主要贡献
综上所述,我们的工作提出了一个相似性匹配模型,并对相似性度量提出了两个改进建议。具体贡献如下:
(1)我们建议使用可训练的距离测量来完成单样本学习任务,并且我们基于修改残差网络的实现在具有挑战性的minimagenet数据集上达到了最先进的水平。
(2)我们证明生成的数据对相似性匹配任务起到了很强的正则化作用,并基于GAN框架设计了一个新的网络,该网络显示了对单样本学习任务的提高。
2.3 思想
(1) The focus of our work, however is on two aspects which we believe are essential for a model to do well on the task of one shot learning - inferring an accurate semantic representation in a low dimensional manifold and strong regularization.
然而,我们的工作重点是两个方面,我们认为这两个方面对于一个模型能够很好地完成单样本学习的任务是必不可少的——在低维流形中推导精确的语义表示和强正则化。
(2) Specifically our modification involves using skip residual connections and we refer to the our model as Skip Residual Siamese Network (SRPN). The model takes a pair of images and outputs a single similarity embedding vector. We train this model end-to-end for the similarity matching objective and then use it for few shot classification tasks on the Omniglot and mini-Imagenet datasets.
具体来说,我们的修改涉及使用跳跃残差连接,我们将我们的模型称为跳跃残差暹罗网络(SRPN)。该模型提取一对图像,输出一个单一的相似性嵌入向量。在Omniglot和mini-Imagenet数据集上,我们对该模型进行端到端的相似性匹配训练,并将其用于小样本分类任务。
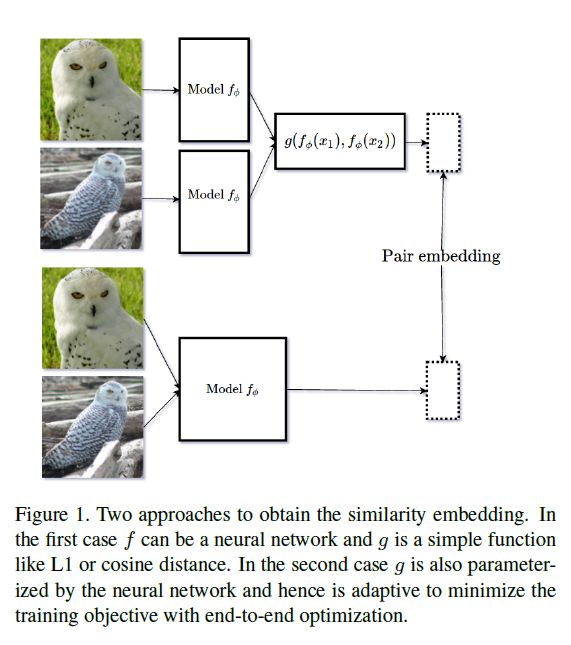
3.模型
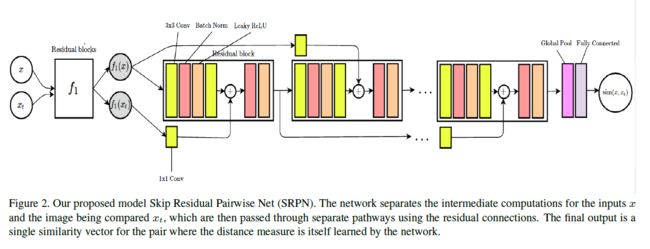
3.1. Skip Residual Pairwise Network
文献中的暹罗网络通常是指具有两个相同的前向路径来生成两个数据点的嵌入的模型,然后根据这两个嵌入的函数来计算相似度。虽然这是一个成功的范例,但是可以说的选择是任意的,模型被迫学习一个嵌入,它可以很好地处理特定的的选择。这样的选择通常可能是次优的(sub-optimal),例如当嵌入本身是解决诸如用于单样本学习的相似性匹配等问题的中间步骤(intermediate step)时。为了避免这种情况,我们提出了一个成对网络,它以一对数据点作为输入,并通过端到端的训练来优化一个特定的目标,在我们的例子中是两个数据点之间的相似性。注意,这会导致度量所必需的对称属性丢失。
我们的网络设计如图2所示。网络的初始部分集中于最抽象的特征,类似于一般的残差网络。然后,为输入对分割中间嵌入,并通过使用1×1卷积的残差跳跃连接和具有批处理规范化[14]和非线性的两个3×3卷积之间交替的不同路径馈送。因此,网络的设计确保了两个目标:
(1)确保足够的混合:允许一个数据点的中间表示影响另一个数据点的中间表示,而不是像正常的暹罗网络中仅在最终的层混合。
(2)保持已成功为非常深的网络训练的残差结构
模型的最终输出是一个输入到线性分类器中预测相似度的单个嵌入。整个网络采用与普通暹罗网络相似的二元交叉熵损失进行端到端的训练。
乘法单元(Multiplicative Units):
乘法门控单元(Multiplicative gating units)已被证明在学习深度模型方面是有效的[31]。在我们的情况下,乘法互动(Multiplicative interactions)通过允许更好地混合来自两个来源的信息提高性能。我们遵循[16]中使用的公式,用一个三门乘法单元(three-gated multiplicative unit)替换块中的第二个整流线性单元激活(second rectified linear unit activation)。然而,我们发现它在显著增加参数数目的同时,对mini-Imagenet实验确实有显著的积极影响,因此我们在最终的模型中避免(refrain)使用它。
3.2. 生成正则化(Generative Regularizer)
我们利用生成对抗网络(Generative Adversarial Network)建立第二个模型,目的是为相似性匹配任务提供更好的正则化。该模型由两个网络组成,一个是相似性匹配判别网络和一个生成网络。和θ是网络的参数。判别网络的目标是预测输入数据点是否与另一数据点属于同一类条件分布。同时训练判别器将生成的图像分类为伪图像。生成器的训练目标是能够生成给定图像的合理变化(plausible variations),即与输入图像属于同一类条件分布的图像。我们模型的结构如图3所示。两个网络的数学公式如下所述。
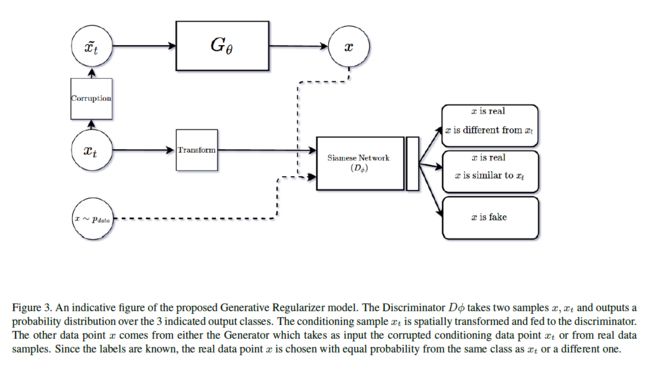
判别器网络:判别器网络试图预测输入数据点是否与属于同一类条件分布的概率,即,其中是数据点的类。因此,网络试图最大化概率,并将其最小化到和。我们避免对使用显式的标签向量,主要是因为2个原因:i)我们不希望网络记住类的详细信息,而是只记住不变的转换;ii)它将防止生成器在训练过程中对不可见的类进行调节。同时用从任何其他分布中提取的x训练网络使其最小化。因此,它还充当基于相似度的分类器,其中相似度是从类标签中确定的。
为了我们的目的,我们发现和p_θ(x |\tilde{x}_t)的判别器分开输出可以获得更好的性能。这与[27]关于半监督学习的工作是一致的。因此,我们制定了我们的判别器,以尽量减少以下损失:


生成器网络:我们提出的模型中的生成器是一个参数函数,它从数据空间映射到同一空间中的另一个点,即充当自动编码器。为了防止生成器简单地复制输入,我们通过一些随机过程破坏输入数据点来实施正则化。然后,通过一系列卷积对损坏的输入数据点进行缩小,然后使用一系列转置卷积进行放大。本质上,我们的生成器表现为去噪自动编码器[33],但它不是重建损失,而是用对抗损失训练。对生成器进行训练,使以下目标最小化:
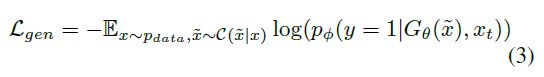
4. 实验
我们在Omniglot和mini-Imagenet两个数据集上进行了实验,验证了所提模型的有效性。我们所有的模型都是使用 Theano的Lasagne库[4]实现的。
4.1. Omniglot
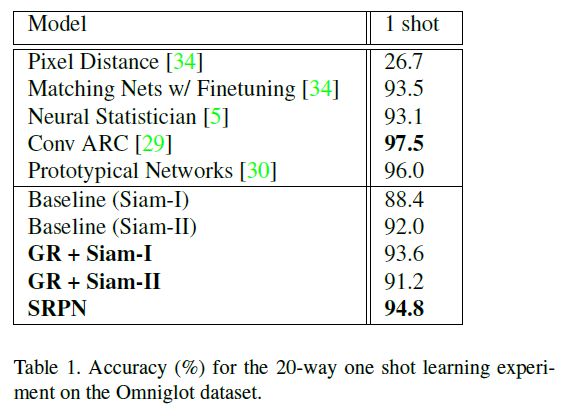
在[20]中引入Omniglot是为了测量模型的一次性学习性能。它由1623类字符组成,每个类有20个二进制图像。文献中使用了两种不同的配置来报告数据集上的结果,一种是字母表内的设置[20],另一种是最近的字母表内的设置[34]。本文的结果与文献[34]一致。
数据集分为两部分——前1200个类用于培训和验证,其余的是用于少量射击任务的测试类。对于这个数据集,我们遵循num tests=200和runs per test=20的训练协议(算法1)。
我们在这个数据集上测试了我们提出的改进,跳过剩余成对网络(SRPN)和生成正则化器(GR)。
我们为卷积连体网络训练两种架构:i)Siam-i:具有5个卷积层的较小架构和最终的全局池层ii)Siam-ii:具有5个剩余块的较大网络,然后是全局池。我们遵循k=2[36]的宽剩余网络设计。为了设计SRPN模型,我们修改了Siam II。虽然暹罗一号和暹罗二号的深度不同,但两者的可训练参数数量相似。我们还使用这些卷积暹罗网络作为我们提出的模型的基线。
为了保证与其他公布的结果的一致性,我们将图像重新调整为28×28像素,并在X和Y轴上以随机旋转(±45°和/或平移(6像素))增强训练数据。训练使用小批量梯度下降,Adam[17]更新,批量大小为128。GR实验的初始学习率设置为8×10-4,并且=0.5。除GR模型外,所有模型都使用L2正则化。我们从早期停止训练中维护了一个60个类的验证集。结果见表1β1
4.2. MiniImagenet
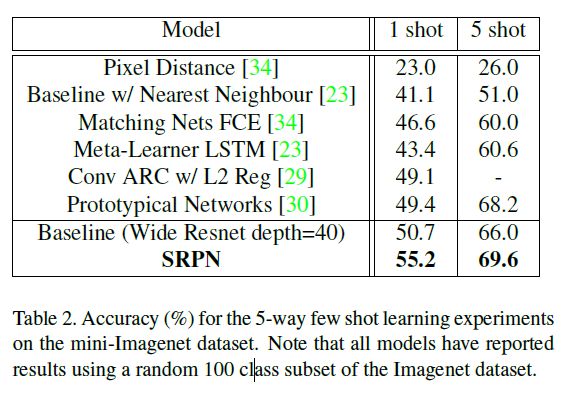
Mini-Imagenet最近在[34]中被引入,作为一个更具挑战性的数据集,用于一次性学习任务。数据集由来自Imagenet的100类自然图像组成,总正确pred=0;对于num测试


数据集[25],每类600个RGB图像,重新缩放到84x84像素。由于没有发布数据集的标准分割,研究人员从Imagenet数据集中随机选择了100个类来报告结果[23][30]。我们这里也有类似的做法。
数据集分为两个部分:前80个类用于训练和验证,其余的是用于少量射击任务的测试类。对于这个数据集,我们遵循num tests=100和runs per test=100的训练协议(算法1)。
我们在这个数据集上分别测试了我们提出的改进,跳过剩余成对网络(SRPN)和生成正则化器(GR)。然而,我们发现生成正则化(GR)并没有为这些非常深入的模型带来任何好处,因为生成器本身无法很好地学习。我们认为这是由于甘训练的不稳定性。因此,我们只报告跳过剩余配对网络(SRPN)的结果。
由于网络深度对于Imagenet的良好性能至关重要,我们将自己限制在网络深度为40且k=2的宽Resnet模型[36]。我们使用这个模型作为基线来训练暹罗网络,并在SRPN模型的设计中对其进行修改,以确保结果具有可比性。
为了确保与其他发布的结果一致,我们将图像重新缩放到84x84像素。不做任何形式的数据扩充或预处理。训练使用小批量梯度下降,Adam[17]更新,批量大小为64。两款车型都经过了10万次更新培训。初始学习率设置为5×10-4,线性退火为1×10-4。L2正则化用于两个模型,初始值5×10-7在60000次更新后增加到1×10-6。结果见表
5. 讨论
我们讨论了两个建议模型的一些观察结果-跳过剩余对网络(SRPN)和生成正则化(GR)。首先,我们注意到SRPN不仅比等效残差暹罗网络具有更高的精度,而且其收敛速度更快,平均网络权值明显更小。(见图6,7)在我们看来,这是因为SRPN没有被迫学习嵌入
使用固定距离度量效果很好,相反,它能够适应最能最小化总损失的距离度量。这使得网络能够找到一个流形,减少了相似性损失和正则化惩罚,有效地提高了泛化性能。我们还注意到,虽然SRPN没有明确地训练来学习对称嵌入,但模型会自动地学习,如图8中嵌入(预最终层)之间的差异减小所示。另外值得注意的是,对于mini-image net任务,我们的暹罗残差网基线优于先前的最新技术,这加强了深度在复杂图像识别任务中的重要性,但同时也表明具有数百万参数的深卷积模型能够成功地从以下特征中学习很好地推广到看不见的数据分布,因此在一次性学习设置很好。
我们使用生成正则化器(GR)进行的实验给出了一个混合的结果包-正则化比2个正则化有效得多,这一点在带有Siam-I模型的Omniglot上的结果表明,用这种方法重申了半监督学习的结果[27]。然而,由于生成器鉴别器框架对超参数非常敏感,因此对其进行训练具有挑战性,通常一
导致训练不好的生成器,阻碍了训练,因为很深的模型被视为鉴别器。我们相信,GAN训练方法的进步可以直接应用于此,并且经过适当训练的GR+SRPN网络将优于L2正则化网络。
另外,我们还尝试在不提供条件信息的情况下训练GR模型,即从高斯噪声到图像空间的映射。我们观察到,生成器不可避免地崩溃到一个点,但仍然能够使暹罗网络正规化。这表明发电机存在多种故障模式,良好的发电对正则化并不重要。我们将继续朝这个方向试验。
6. 结论
综上所述,我们确定了固定距离度量和弱正则化是相似匹配的主要挑战,并将其扩展到单样本学习,并针对每个问题提出了网络设计。我们的跳跃残差对网络优于等效残差暹罗网络,并在mini-Imagenet单样本分类数据集上取得了最新的性能。在Omniglot数据集上,我们的生成正则化算法显示了很有希望的结果,并且优于L2-正则化。未来的工作将集中在整合这两个网络,利用在生成性对抗模型训练方面的进展。
参考资料
[1]
[2]
[3]
论文下载
[1] Generative Adversarial Residual Pairwise Networks for One Shot Learning
代码
[1] # NVlabs/FUNIT