Akka持久可以用HBase,翻译HBase官方架构文档:Akka persistence enables stateful actors to persist their state so that it can be recovered when an actor is either restarted, such as after a JVM crash, by a supervisor or a manual stop-start, or migrated within a cluster. 持久可以令有状态actor(实体)持久化自身状态,以便可以做状态恢复(从JVM Crash导致的监管重启或者手动重启、再或者是在集群的再平衡迁移过程)

技术上来说,HBase更像是"Data Store" 而不是 "Data Base"数据库,因为HBase不具备耳熟能详的RDBMS特性,如:typed columns严格类型列、 secondary indexes二级索引、 triggers触发器、以及高(傻)级(瓜)的SQL查询语言。HBase是兼具列式存储、键值存储特性的NoSQL. 在新建表的时候只要指定表名和至少一个列族名字即可,列可以在插入数据时动态新建,最佳定义:“HBase is a sparse, distributed, persistent multidimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted array of bytes.”
但是,HBase具备的多种features可以支持linear and modular scaling (应该是Scale-Out横向扩展能力),HBase集群可以添加商(便)用(宜)级Server来扩展RegionServers. 如果集群从10台扩展到20台RegionServers,那么存储翻倍、 processing capacity处理容量也翻倍。
HBase几大features
1、直观的CP系统:强一致的reads/writes;
2、自动分片/分区Automatic sharding:HBase表跨regions存储于集群,随着数据增长,regions自动分裂以及re-distributed再分布;
3、自动容错:自动化的RegionServer失效处理;
...分片和容错早已有之,NoSQL的一大贡献是使之自动化。
最大特性:数据不变(HBase basically never overwrites data but only appends.),也就是数据基本不会就地修改(当已达到最大版本号时, 超出限量版本的老数据在合并时会被丢弃),凡是有讲append就是在说数据不变了比如AkkaPersistence对流式事件数据存储到日志的架构同样是appending to storage (nothing is ever mutated) which allows for very high transaction rates and efficient replication. Akka对流式/时序数据称为events事件即事实数据,存储目标为journal日志/流水账。数据不变带来两个巨大好处:
1、避免分布式事务,这是成本很高的老大难问题,要支持则达不到处理大数据的吞吐量性能。到了NoSQL时代,解决这个问题的办法就是让问题消失、最高明的解决方案就是让问题消失、无需解决,数据不变仅append、消灭分布式事务代表消灭了相关的锁和同步远程方法调用;
2、磁盘连续存,这样就可以支持性能很高的连续读写,特别是读,读取在磁盘上连续存储的数据时,有统计表明性能高于直读内存。
那么有即使是少量的删改肿么办?改靠version版本号、删靠打标记,之后在major compact时真正删除(HBase does not overwrite row values, but rather stores different values per row by time (and qualifier). Excess versions are removed during major compactions.The number of max versions may need to be increased or decreased depending on application needs.)、传统RDB说你这有一点workaround了,HBase说没错,因为哥的格局就不在这里!哥的征途是云大物移。version数据类型是Integer.MAX_VALUE,最大Integer.MAX_VALUE. 其实“不约而同”选择数据不变的还有HDFS及Kafka. 聪明如你,应可体会,数据不变是一把屠龙刀,所斩杀的龙叫做数据共享,这把宝刀函数式和HBase都有用。
A cell is a combination of row, column family, and column qualifier, and contains a value and a timestamp, which represents the value’s version. 版本号就是时间戳。
函数式的数据不变,巧合?
传统小内存当中数据存放需要精打细算,不允许一点冗余,数据共享是直觉选择,有并发冲突也就是必然。随着多核时代到来,大内存也来了,上百G内存已很常见,有个类比,当前再去讲究几个KB的节省无异于买了几万块的东西再去讲价几分钱,已经没有意义了。函数式的数据不变避免了内存中数据共享的问题;HBase的数据不变避免了磁盘中数据共享的问题。Scala语言集合库优先不可变,对于javaer可以从String入手理解,Scala集合库在底层通过共享对象降低了生成新对象的成本,感觉为此Scala去掉了基本类型:Byte、Char、Short、Int、Long、Float、Double、Boolean全是高级类型,scala里敲一个2这就是实实在在的对象:

类似Akka的Sharding,HBase的数据分片以Region分区表示,Regions分区是表分布存储到集群以及分布式访问的基本单元,它由每个Column Family列族的具体Store组成,对象层次图:
Table (HBase table) ——抽象层
Region (Regions for the table) ——逻辑层
Store (Store per ColumnFamily for each Region for the table) —— 列式存储层
MemStore (MemStore for each Store for each Region for the table) — 写缓存
StoreFile (StoreFiles for each Store for each Region for the table) —— 物理存储层、一个StoreFile只会属于一个列族、一个列族则可能不止一个StoreFile;StoreFile与MemStore平级、一个在磁盘一个在内存、MemStore满了flush到StoreFile、后台compact以StoreFile为单位进行
Block (Blocks within a StoreFile within a Store for each Region for the table) — HDFS存储层
我们看到HBase是按照CF列族做列式存储的,在每一个CF列式存储中直到每一个StoreFile级别,都独立存储rowKey、MemStore也存,可见rowKey从硬盘到内存是大量冗余存在的,所以HBase的rowKey不要设计的太长上升为设计注意事项的高度。HBase的regions,具备一定大小(每个在5-20Gb)之后,最好是在每台节点机保持20-200个,不要过多了。
什么时候可以用HBase
HBase并不适用于所有问题:首先,你得有足够多的数据需要处理,如果只有几百万行数据,RDBMS就够用了,用HBase的话可能造成你的数据只存在一两个节点上,集群其余节点机全都空闲浪费了,少量数据即使不是关系型,存MySQL+主键,够了;第二,你不是必须要用到RDBMS的一些特性 e.g. typed columns, secondary indexes, transactions, advanced query languages, etc. 说白了就是你存的数据是不是强关系型。
第三,你得有足够多的硬件,比如HDFS在默认三备份情况下、少于5个DataNodes节点就不太好了,还得外加一个NameNode节点。HBase即使在笔记本上也能跑得很好,但这应该只是在开发时;
HBase的底层存储HDFS分布式文件系统并不是一个通用文件系统,它只特别适合于大文件存储,不适合在文件中查找内容(也就不适合删除修改单条数据),但HBase在HDFS之上支持快速的数据记录的查找和更新(以append形式追加小文件StoreFiles、但最终合并compact为大文件,合并期间旧数据真正删除),有时候这会造成概念混淆,HBase内部存储是以经过索引的"StoreFiles"文件形式,StoreFiles存在于HDFS可供高速查找,参考Data Model.
这是一篇不错的博客。
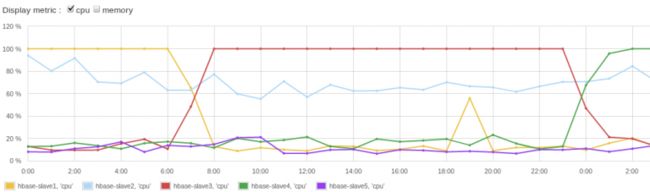
Rowkey加盐问题:“如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。” —— 这些只是通用化的提示,实际当中还是需要根据你的场景、结合具体情况去考虑,注重性能的少量几个字段条件查询可以结合phoenix、要丰富图表的时序数据存储可以考虑OpenTSDB.
rowKey如果设计为递增数值,则能在按给定行键起止范围读取相关/相近数据时提供最佳性能(借助OS的预读缓存),但同时会在大并发写数据时造成热点:writing records with sequential row keys allows the most efficient reading of data range given the start and stop keys, it causes undesirable RegionServer hotspotting at write time. 这便是HBase RS热点问题:RegionServer hotspotting. 它会造成写热点:
目录表
目录表hbase:meta就是一个普通HBase表,虽然在HBase shel 的list命令中会被滤掉,但它和其他HBase表一样。hbase:meta表 (previously called.META.) 记录系统所有regions,hbase:meta表存储在ZooKeeper. 表结构如下:
1、Key:分区键Region key,格式: ([table],[region start key],[region id])
2、Values:
1) info:regioninfo (serialized HRegionInfo instance for this region) 分区信息
2) info:server (server:port of the RegionServer containing this region) 分区所在RegionServer信息
3) info:serverstartcode (start-time of the RegionServer process containing this region)
当表处于splitting分裂阶段时,额外的两个列会被创建出来:info:splitA 和info:splitB. 这俩列表示两个分裂目标regions. 其值也是serialized HRegionInfo instances. 分裂结束后、最终会删掉。
HRegionInfo是用来表示一个region分区的具体类型,它用empty key空键表示一张表的起始和终止位置,具备空的起始键的region就是一张表的起始分区。 If a region has both an empty start and an empty end key, it is the only region in the table —— 如果一个region分区具备一张表的空起始键以及空结束键,那么这个分区就是这张表唯一所在的分区。另外上面提到数据的version版本号,也就是说同样rowKey、同样列族列名的数据cell,也可以存在多个,以版本号区分(It’s possible to have an unbounded number of cells where the row and column are the same but the cell address differs only in its version dimension),需注意即使版本数量设到最大Integer.MAX_VALUE. 单个rowkey的region再大也是不会split的。
版本号、compaction一定程度上都是为了数据不变的目标服务,数据不变,是存在于不止HBase的各个大数据存储技术栈的核心特性,而且事实上,海量数据本身就有不变的天然属性,这些数据如移动互联网的用户行为数据、物联网的传感器量测数据,都属于事实/时序数据,他们是既成事实,不应该改变,所谓时序是只与时间强相关的数据,那么,不可能也不应该回到过去的时间修改数据,与时间强相关意味,如果一条数据其他都完整就是丢了时间,那么这条数据完全不可用了。对于这些海量事实数据的访问,不同于传统关系数据,往往只在两个方面:一要么定点快速查明细,就是高效查单条;二要么大规模统计分析,看结果。基本上不会像传统RDB/BI,各种姿势的SQL翻来覆去的看数据。而HBase的数据访问方式,契合这两方面要求,用rowKey查单条、ok够简单,列式OLAP数据分析用scan,ok够粗暴。HBase的第一大招定点爆破、用rowKey查单条,和scala的Vector类似:
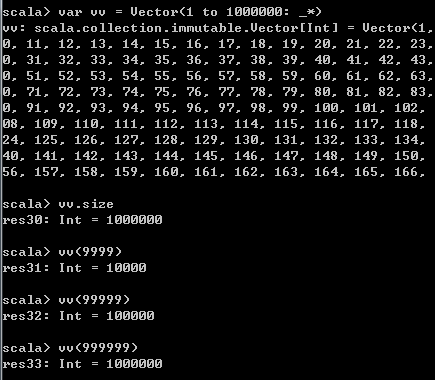
Vector以树形结构实现,支持大数据量的性能O(1)的随机读(感觉随机这个词翻译的不好,它其实就是查单条,叫定点爆破更好)及随机写(基于随机读),增和删稍差些。每个树节点可以有32个子节点,所以n层树就有32的n次幂个元素。100万元素只需4层树(1million < 32的四次幂),下标访问任意元素只需4跳(List就完了平均需要50万跳),如果你有大量有序元素,需要在内存快速随机访问就用Vector;如果你有海量数据,需要在磁盘快速随机访问就用HBase,而且HBase集群更狠,虽然是集群,不过估计所有RegionServer都知道哪个rowKey范围的数据在哪一台节点机上,这样,所有的按rowKey查应该最多只需一次跨机路由,数据很多吗?集群很大嘛?1k台节点机和三五台,一样是一次路由定位,对于单条定点爆破式查询而言,不管数据量和集群大小,时间成本近乎常数O(1),如果单条体现不出什么优势,和RDB差不多也可能低一点,木关系,哥的征途是大数据大集群,海量数据超大集群每个单条查询性能不变,RDB行么?这就是,HBase最简单最粗暴的地方

终于在Maximum Number of Versions最大版本数量看到这句话:It is not recommended setting the number of max versions to an exceedingly high level (e.g., hundreds or more) unless those old values are very dear to you because this will greatly increase StoreFile size,找这句话好久了,意思是不要把允许的最大版本数量设置的很大比如上百,除非你真的真的需要,因为这样做会显著增大StoreFile大小。潜台词是,所有cell,即使你没有存入多个版本,因为磁盘连续存,同样会留出多个版本的空间,每个cell都是这样,才会造成StoreFile整体尺寸显著增大,这也印证了数据不变。
一个region就是一张表的整个key空间当中的一段key分布,每个region都有一个唯一名字region name,包含下列信息:
1、tableName : The name of the table
2、startKey : The startKey for the region.
3、regionId : A timestamp when the region is created.
4、replicaId : An id starting from 0 to differentiate replicas of the same region range but hosted in separated servers. The same region range can be hosted in multiple locations.
5、encodedName : An MD5 encoded string for the region name.
除了region name,HRegionInfo 还包含信息:
1、endKey : the endKey for the region (exclusive)
2、split : Whether the region is split
3、offline : Whether the region is offline
在0.98及更老版本,一张表的所有regions包含了该表整个keyspace键空间,也就是该表所有数据。在任何时候,一个row key总会属于唯一一个region,这个region也会位于唯一一个server. 到0.99版本以上,一个region开始可以具备多个实例即replicas副本,这样一行或者一个范围的数据就可能关联到多个HRegionInfo. 这些HRI共享大部分region信息、除了replicaId 副本ID. replicaId副本ID不设置的话默认为0(which is compatible with the previous behavior of a range corresponding to 1 region.)
Standalone部署模式
HBase运行模式分两个大类:standalone和分布式模式。standalone即所有HBase Demon运行在单JVM当然也是单机的,麻雀虽小五脏俱全,standalone模式同样具备所有HBase daemons :Master、一个RegionServers 以及 ZooKeeper ,他们运行在一个JVM中以线程形式运行。概括来说,standalone就是以多线程模拟多进程;分布式模式中的所谓伪分布式是以单机多进程(多JVM)模拟分布多进程、是最接近生产环境的,但是,以我用过的Spark包括这个HBase来说,本地多线程模拟分布多进程没啥毛病。
Standalone又分为两个小类:
1、standalone模式,纯本地:持久化到本地文件系统(In standalone mode, HBase does not use HDFS — it uses the local filesystem instead),但是为了用起来windows文件系统,美帝活雷锋提供了winutils,如果你是win10+WSL就用不到它了,但还是要感谢雷锋同志,在WSL出来之前,要么用cygwin模拟linux环境、要么用这个winutils模拟posix文件系统。
2、standalone over HDFS模式:持久化到一个运行中的HDFS实例,算是一种standalone模式的变种(standalone variant),此时除了存储部分其他与standalone模式一样,只是存储不再是file:///本地、而是访问远程HDFS实例。You might consider this profile when you are intent on a simple deploy profile, the loading is light, but the data must persist across node comings and goings. Writing to HDFS where data is replicated ensures the latter. 意思大概是这种场景下,数据存储放到了远程HDFS,你每次的开发测试只会拉取少量数据、全数据放在远程HDFS、这样你的本地开发环境更加轻量同时全数据还能保持可访问性。很简单只要配置即可:

分布式模式也分两种:pseudo-distributed vs.fully-distributed,参考:Distributed,Pseudo-distributed伪分布式是在本地起多个JVM,多进程模拟,所以也类似standalone可以基于纯本地文件系统、以及基于远程HDFS文件系统的变种(但是有了standalone感觉伪分布式就没什么用处);Fully-distributed纯分布式则是所有HBase Demon也都是分布式运行了,这就是生产环境了,当然只能是on HDFS. 伪分布式就是纯分布式在单机上运行的模式,用于测试和原型开发,将上图standalone over HDFS模式配置中的hbase.cluster.distributed配置设置为true,zk的quorum设置为仅本机,就是伪分布式了。
下面演示纯本地standalone模式:使用hbase shell创建表、insert插入行数据、执行put and scan、 enable or disable the table, and start and stop HBase. 十分钟就完事(还不算下载HBase的时间),以两种环境(win10+WSL和win7+winutils)为例步骤如下:
win10+WSL
这个就可以按照官网来做,很方便,不用考虑Hadoop的事:
1、设置hbase.env.sh:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
2、设置hbase-site.xml(xml标签不写了):
hbase.rootdir = file:///usr/HBase/hbase
hbase.zookeeper.property.dataDir = /usr/HBase/zookeeper
要minimum最小配置的话,只做第一步就够了,此时hbase.rootdir会默认为tmp目录,对于linux来说重启会清除该目录,WSL bash只是一个窗口重启更简单了,那么为了数据不丢可以设一下hbase.rootdir,注意该目录不要自己创建(You do not need to create the HBase data directory. HBase will do this for you. If you create the directory, HBase will attempt to do a migration, which is not what you want.)否则会触发一个启动Error. 我是在win10环境下用IDEA编辑上述文件(win10下UE还不能用,别用写字板,当然最好是WSL里用vi),回到WSL bash执行目录/mnt/c/Ubuntu/hbase-2.0.1/bin 下的 start-hbase.sh启动HBase,然后可以操作测试:

有了WSL,单机开发测试就用Standalone Mode就够了,想不出来伪分布式还有什么用处。
win7
还得解决winutils问题:https://stackoverflow.com/questions/34697744/spark-1-6-failed-to-locate-the-winutils-binary-in-the-hadoop-binary-path;
https://wiki.apache.org/hadoop/WindowsProblems;
https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1/bin;
总之大概意思是可以自己下载hadoop-common,只要有exe和dll之类就行、设个HADOOP_HOME、步骤还是:
1、打开conf/hbase.env.cmd环境设置脚本、设置JDK 等:
set JAVA_HOME=C:\Java\jdk1.8.0_151
set HBASE_MANAGES_ZK=true
这里的JAVA_HOME是JDK目录(directory which contains the executable file bin/java.),linux一般可以设置为链接目录/usr(链接到bin/java.)
2、打开conf/hbase-site.xml主配置文件、配置HBase 和 ZooKeeper(ZK我们知道是定位active Master的,在此它用来支持HBase有限的Master HA)数据目录属性:
hbase.rootdir = file:///C:/HBase/hbase
hbase.zookeeper.property.dataDir = C:/HBase/zookeeper
最好使用变种的standalone over HDFS模式,这样也不用管winutils问题了:
hbase.rootdir = hdfs://namenode.example.org:8020/hbase
hbase.cluster.distributed = false
Bulk Loading
HBase有好几种向表加载数据的方法,第一个理论上最常用的是在MR里使用TableOutputFormat类,但事实上MR已淘汰,所以下面提到MR都可以理解为是在Spark任务程序当中使用;第二就是一般的客户端API了,适用于一条一条插入数据,这都不是最高效的方法。
最高效的是Bulk Load,它
使用了MR?
直接输出HBase内部数据格式的表数据,然后将生成的StoreFiles文件加载/上传到运行当中的集群直接入库,我们看到这实际上要求你生成/输出数据的生产端是并行的、也就是在数据库之外的客户端进行、把解析下推到客户端,也可以有多个客户端,并行+批量,才能达到大吞吐量、达到最高的入库效率。很明显,和上述两种方式不同的是,Bulk Load会使用少量CPU和网络资源。
限制和不足
As bulk loading bypasses the write path, the WAL doesn’t get written to as part of the process. Replication works by reading the WAL files so it won’t see the bulk loaded data – and the same goes for the edits that use Put.setDurability(SKIP_WAL). One way to handle that is to ship the raw files or the HFiles to the other cluster and do the other processing there. 大意是由于Bulk Load绕过了写路径,所以这个过程中没有写WAL. 那么一些通过读WAL来同步数据工作方式的工具就会看不到bulk loaded的数据,当然,像Put.setDurability(SKIP_WAL)这样明确声明不写WAL的插入数据一样看不到的。
实际当中,决定哪一种数据入库方式其实很简单,完全由你的场景决定。现在HBase很多是第一次应用到一些传统应用中去,这些应用往往有自己的数据接收模块,那么最简单的是在其中加入生成数据文件功能,然后用Bulk Load批量导入,MR的Bulk Load主要包括两步(MR没人用,要用还是在Spark任务程序中使用):
1、Preparing data via a MapReduce job
Bulk Load第一步是在MR(把MR都理解成Spark就好)中生成HBase数据文件(StoreFiles):使用HFileOutputFormat2.
这种输出格式会将数据直接写成HBase的内部存储格式,之后就能很高效地加载到集群。
为了效率,HFileOutputFormat2必须配置为每一份HFile存入一个region.
2、 Completing the data load
准备好要导入的HFile数据文件以后,你可以使用importtsv工具( with the “importtsv.bulk.output” option)、或者在MapReduce任务程序当中使用HFileOutputFormat, 还有一个completebulkload用于将数据导入正在运行的集群,这是一个命令行工具,它会遍历你准备好的数据文件、直接决定这个文件加载到哪一个region(iterates through the prepared data files, and for each one determines the region the file belongs to.)、之后它会找到合适的RegionServer、向其提交HFile文件,就o了!
在Spark任务程序当中使用
使用Spark向HBase导入数据有两种情况,一种是基本批量导入,用于一行有上百万列的场景、以及你的列并不固定、在Spark的Map作业之前要做partition分区(partitions before the on the map side of the Spark bulk load process.)的场景。
还有一种thin record bulk load瘦记录批量导入情况,设计用于列数在万以下的表(tables that have less then 10k columns per row.),这种的优势在于更高吞吐量、以及在 Spark shuffle 时不必全部加载。
两种情况都或多或少类似于 MapReduce bulk load,其中一个partitioner分区器会将rowkeys进行分区( based on region splits and the row keys are sent to the reducers in order),这样HFiles将会在reduce阶段被直接输出。
用Spark(官网)的话来说, bulk load的实现是基于其repartitionAndSortWithinPartitions followed by a Spark foreachPartition.