来源:http://spot.incubator.apache.org/project-components/suspicious-connects-analysis/
Spot提供了一系列可疑连接分析,这些分析可以识别观察到的网络中最可疑或最不可能发生的网络事件,并将这些事件报告给用户,以便进行进一步调查,以确定这些事件是否表示恶意或故障。可疑连接分析是半监督异常检测的一种形式,它使用主题建模来推断常见的网络行为,并为每个IP地址建立行为模型。
Spot-ml核心的主题模型是一个无监督的机器学习模型。然而,Spot允许用户反馈来影响模型对可疑内容的看法(有关反馈功能的更多细节,请参阅“Spot-ml进一步说明”)。本节简要介绍可疑连接分析背后的数学原理。
一、支持数据分析
目前Spot支持对以下数据源进行分析:
(无定向)Netflow日志
DNS日志
HTTP代理日志
在这个讨论中,日志条目被称为“网络事件”。
二、通过主题建模进行异常检测
可疑连接分析为每个IP地址的网络行为提供了一个概率模型。每个网络事件被分配一个估计的概率(从今以后,事件的“分数”)。得分较低的事件被标记为“可疑的”,以供进一步分析。
通过主题建模生成概率模型。主题建模是一种来自自然语言处理的技术,它分析自然语言文档的集合,并推断出文档讨论的主题。特别是我们使用一个潜在的Dirichlet分配(LDA)模型。关于超出此描述范围的详细信息,请参阅David M. Blei、Andrew Y. Ng和Michael I. Jordan合著的《机器学习研究期刊》文章“Dirichlet Allocation”。为了进行比较,我们的数学符号类似于JMLR文章中使用的符号。
下面我们将描述LDA模型产生的概率分布,并描述如何将异常分数分配给文档的单词。然后,我们将描述“单词”和“文档”是如何从网络日志中形成的,以便网络日志条目能够根据与之相关联的单词的得分提供一个异常值。
三、潜在狄利克雷分配
输入:一组文档,每个文档被视为一组单词(一组单词)。一个整数k,它是模型要学习的潜在主题的数量。
输出:两组分布。对于每个文档,一个“文档的主题混合”给出了从文档中随机选择的单词属于任何给定主题的概率(即文档中用于任何给定主题的部分)。对于每个主题,都有一个“主题词组合”,它给出了任何给定的词以主题为条件的概率(也就是说,该主题用于每个词的部分)。
数学符号:

假设主题的混合词与所讨论的文档是独立的。因此,我们可以对出现在文档d中的单词w的概率进行模型估计,如下所示:
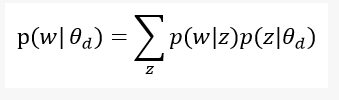
四、主题建模和网络事件
通过将IP地址的日志行为作为文档来查看(例如,所有特定客户端IP的DNS查询)和组成日志条目作为“words”使用主题建模来分析网络流量是很简单的。

有一个重要的问题:对于主题建模提供有趣的结果,不同文档使用的单词应该有显著的重叠,而网络日志条目包含几乎惟一的标识符,如网络地址和时间戳。出于这个原因,要在网络事件上执行主题建模,必须将日志条目简化为单词。
五、从事件到文档:单词创建
网络事件转化为文字是微妙的艺术点,在spot可疑的联系分析。将事件转换成文字的过程必须保持足够的信息在恶意行为出现有趣的异常或故障,必须创建单词之间有足够的重叠文档(IP地址),主题造型步骤产生有意义的结果,它应该提取信息特定流量的“类型”,而不是一个特定的机器(为简化的假设来估计词概率)。
六、Netflow
netflow记录被简化为两个独立的单词,一个插入到与源IP相关联的文档中,另一个(可能是不同的单词)插入到与目标IP相关联的文档中。这些词的构成如下:
特征(单词中的字母)
1、流向:
如果两个端口(源和目标之间)都为0,那么源和目标IP文档中的单词就会丢失这个特性。
如果恰好有一个端口为0,那么与0端口相关联的IP文档就会丢失该特性,而与非0端口相关联的IP文档则会将该特性作为“-1”给出。
如果两个端口都不为零,或者两个端口都严格小于1025,那么这个特性在源IP和目标IP中都不存在。
如果两个端口都不为零,并且只有一个端口严格小于1025,那么这个特性对于与小于1025的端口相关联的IP文档来说被赋予为“-1”,而与另一个(高)端口相关联的IP文档则被丢失。
2、关键端口:
如果源和目标端口都为0,那么对于源和目标IP文档,这个特性都被赋予为“0”。
如果其中一个端口是不为零的,那么这个特性将作为源和目标IP文档的非零端口号。
如果恰好有一个端口小于1025,并且这个端口不为零,那么这个特性将作为源和目标IP文档的端口号。
如果两个端口都是非零的,并且严格小于1025,那么这个特性将作为源和目标IP文档的“111111”。
如果两个端口都大于或等于1025,那么对于源和目标IP文档,这个特性都被赋予为“333333”。
3、协议
使用日志条目中给定的字符串
4、每天的时间
使用时间戳的小时部分
5、总字节数
使用框架长度下落入的bin编号的字符串,使用以下截断值定义的bin:(0,1,2,4,8,…)
6、数据包数量
使用框架长度下落入的bin编号的字符串,使用以下截断值定义的bin:(0,1,2,4,8,…)
例子:
(1)以源端口1066、目的端口301、协议TCP形式给出的记录,一天中的时间为小时3,字节为1026,发送包10个。
单词:“301_TCP_3_12_5”是为源IP文档创建的。
单词:“-1_301_TCP_3_12_5”是为目标IP文档创建的。
(2)源端口1194、目的端口1109、协议给定UDP、一天时间、小时7、字节传输1026、数据包发送1个。
这个词:“333333 _udp_7_12_1”创建的源和目标IP文档
七、DNS
DNS日志条目被简化为一个单词,并插入到与进行DNS查询的客户端IP相关联的文档中。该词的创建如下:
特征(单词中的字母)
1、分析DNS查询名称:
如果属于Alexa top 100 million list,使用“1”
如果属于用户域,使用“2”
(注:英特尔公司域名为intel)
否则,使用“0”
2、帧长度
使用框架长度下落入的bin编号的字符串,使用以下截断值定义的bin:(0,1,2,4,8,…)
3、每天的时间
使用时间戳的小时部分
4、子域名长度
使用框架长度下落入的bin编号的字符串,使用以下截断值定义的bin:(0,1,2,4,8,…)
5、字符串熵子域名
使用框架长度下落入的bin编号的字符串,使用以下截断值定义的bin:
(0.0,0.3,0.6,0.0,1.2,1.5,1.8,2.1,2.4,2.7,3.0,3.3,3.6,3.9,4.2,4.5,4.8,5.1,5.4,20)
6、子域的周期数
使用框架长度下落入的bin编号的字符串,使用以下截断值定义的bin:(0,1,2,4,8,…)
7、DNS查询类型
使用日志条目中给出的字符串
8、DNS查询响应代码
使用日志条目中给出的字符串
八、代理
代理日志条目被简化为一个单词,并插入到与发出代理请求的客户端IP相关联的文档中。该词的创建如下:
特征(单词中的字母)
1、分析DNS查询名称:
如果属于Alexa top 100 million list,使用“1”
如果属于用户域,使用“2”
(注:英特尔公司域名为intel)
否则,使用“0”
2、每天的时间
使用时间戳的小时部分
3、请求方法
使用日志条目中给出的字符串(如 “Get”、“Post”等等)
4、URI的字符串熵
使用框架长度下落入的bin编号的字符串,使用以下截断值定义的bin:(0.0,0.3,0.6,0.0,1.2,1.5,1.8,2.1,2.4,2.7,3.0,3.3,3.6,3.9,4.2,4.5,4.8,5.1,5.4,20)
5、顶级内容类型
使用日志条目中给出的字符串(如 “图像”、“二进制”)
6、用户代理输入训练数据的频率
使用字符串的本数字(0 -∞)的熵值下降,使用以下截止值定义的垃圾箱:
(0、1、2、4、8、16、32、…)
7、响应代码
在日志条目中使用字符串
关于Spot-ml的进一步说明
1、关于创建词的说明
与给定值相关联的bin编号被指定为截断值数组中第一个条目的索引,该条目的值小于或等于该条目。例如,将属于bin编号0的值由不等式定义:value <= cut_off_array(0),而位于bin编号1中的值由不等式定义:cut_off_array(0) < value <= cut_off_array(1)。
2、LDA的实现
我们目前使用Spark-MLlib实现潜在的Dirichlet分配。
3、用户反馈
如果用户确定某个连接的某些特性值是可接受的,并且被错误地分类,Spot允许用户提供反馈,以便生成一个新的模型,不再标记类似事件为可疑事件。
在UI中,用户可以指定选择的特性:源ip、目的地ip、源端口和目的端口;给予用户严重性评分为“3”(意味着低优先级)。此操作将导致低优先级指定与所有日志条目(来自从Spot-ml返回的最可疑条目的集合)相关联,这些条目具有与所选特性相匹配的特性值。然后将这些日志条目存储到csv文件中。然后将该文件中的日志条目(每个条目被插入到下一批数据中,这些数据由spot.conf中的DUPFACTOR设置的值决定)的次数。因此,简化到特定单词的日志条目(匹配反馈日志简化到的单词)随后将被视为正常,因为现在数据中出现了大量这样的单词。