这几天看了看操作系统,顺便研究了一下Python的协程,下面就是做的一点笔记
协程是什么?
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。协程相当于一个特殊的函数,可以在某个地方挂起,并且可以重新在挂起处继续运行。
协程不被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行),这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
一个线程内的多个协程是串行执行的,不能利用多核,所以,显然,协程不适合计算密集型的场景。协程适合I/O 阻塞型。
Python的协程
Python的协程有这么三种
- 由生成器变形来的
yield/send - Python 3.4版本引入的
@asyncio.coroutine和yield from - Python 3.5版本引入的
async/await
生成器变形来的 yield/send
在写这个之前,先要知道Python的生成器,讲生成器之前又要先讲下迭代器。
迭代器
在Python中,实现了iter方法的对象即为可迭代对象,可迭代对象能提供迭代器。
实现了next方法的对象称为迭代器,Python2里面是实现next方法。因为迭代器也属于可迭代对象,所以说迭代器也要实现iter方法,即迭代器需要同时实现iter和next两个方法。
关于可迭代对象和迭代器的区别,参考https://blog.csdn.net/liangjisheng/article/details/79776008,这里就不多讲了。
直接讲迭代器了。
class Miracle:
def __init__(self,name,age):
self.__name = name
self.__age = age
def __next__(self):
self.__age += 1
if self.__age > 778:
raise StopIteration
return self.__age
def set(self,age):
self.__age = age
def __iter__(self):
return self
m = Miracle("Miracle778",770)
上面定义了一个类,实现了__next__、__iter__方法,故这个类的对象是迭代器。迭代器可以调用内置方法next(另一种写法是obj.__next__()),进行一次迭代。我们如果用上面的代码的上下文环境执行 next(m)语句,会输出771。
如果next方法被调用,但迭代器没有值可以返回的话,就会引发一个StopIteration异常,我们这里手动抛出该异常,主要是为了避免无限迭代。
我们可以知道,使用next()方法,迭代器会返回它的下一个值,那如果我们需要遍历所有迭代器的值,那岂不是要调用n次next()方法了吗?但还好,可以使用for循环进行遍历。
class Miracle:
def __init__(self,name,age):
self.__name = name
self.__age = age
def __next__(self):
self.__age += 1
if self.__age > 778:
raise StopIteration
return self.__age
def set(self,age):
self.__age = age
def __iter__(self):
return self
m = Miracle("ye",770)
for i in m:
print(i)
输出:
771
772
773
774
775
776
777
778
可以看到上面的for i in m,这里发生的过程如下
Python解释器会在第一次迭代时自动调用iter(obj),之后的迭代会调用迭代器的next方法,for语句会自动处理最后抛出的StopIteration异常。
也就是说,也可以这样写for i in iter(m),执行结果与for i in m一样。
此外,因为迭代器也属于可迭代对象,于是也能使用内置方法list(),将对象转换成列表。
m.set(770)
t = list(m)
print(t)
输出:
[771,772,773,774,775,776,777,778]
迭代器就简单讲到这里了。下面简单讲下生成器
生成器
生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面的类一样写__iter__()和__next__()方法了,只需要一个yiled关键字。 生成器一定是迭代器(反之不成立)
def fib():
print("正在执行")
prev, curr = 0, 1
while True:
yield curr
prev, curr = curr, curr + prev
比如说上面的代码,函数fib里面出现了yield关键字,则这个函数即为生成器。函数的返回值是一个生成器对象。当执行f=fib()返回的是一个生成器对象,此时函数体中的代码并不会执行,只有显示或隐示地调用next的时候才会真正执行里面的代码。
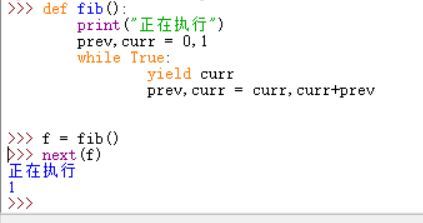
如上图,执行了next后,函数里面代码才被执行,所以生成器更能节省内存和CPU。
开头说到,生成器也是一种特殊的迭代器,故生成器也可以被迭代,如下图。

从上面的例子可以看到,通过yield语句返回迭代值,整个过程如下
在 for 循环执行时,每次循环都会执行 fib 函数内部的代码,执行到 yield curr 语句时,fib 函数就返回一个迭代值,下次迭代时,代码从 yield curr 的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。
上面我们用到的都是使用yield语句抛出迭代值,如:yield curr,其实yield语句也能用来赋值。
def consume():
while True:
i = yield
print("消费者",i)
看到上面这个例子中的i = yield语句,我们可以在函数外调用send函数对i进行赋值,不过在调用send函数之前,必须先要“激活”该生成器,使其执行到yield语句处。
下面我们就来调用一下send函数,运行一下。
def consume():
print("consume函数被激活")
while True:
i = yield
print("消费者",i)
consumer = consume() # 生成器
next(consumer) # 激活生成器,使其运行到yield函数处
for i in range(7):
consumer.send(i)

send函数跟next函数类似,把值传输进去,然后函数运行yield语句后面的代码,直至再次遇上yield,然后中断,等待下一个send或者next函数的运行。
因此,send函数也能用于生产器激活,不过激活的时候,要send(None)才行,此外send函数的返回值和next一样,都是yield抛出的当前迭代值。
yield/send 协程
上面讲生成器最后举的例子,可视为yield/send型协程。
yield会使当前函数即协程暂停,这不同于线程的阻塞,协程的暂停完全由程序控制,协程暂停的时候,CPU可以去执行另一个任务,等待所需要的值准备好后由send传入再继续执行。
@asyncio.coroutine和yield from型协程
这类协程和async/await差不多,所以就不讲了,直接讲Python 3.5版的async/await
async/await
在Python3.5中引入的async和await,可以将他们理解成asyncio.coroutine/yield from的完美替身。当然,从Python设计的角度来说,async/await让协程表面上独立于生成器而存在,将细节都隐藏于asyncio模块之下,语法更清晰明了。
先看到async关键字的使用情况
- async def 定义协程函数或者异步生成器
- async for 异步迭代器
- async with 异步上下文管理器
先看到async def定义的函数的两种情况
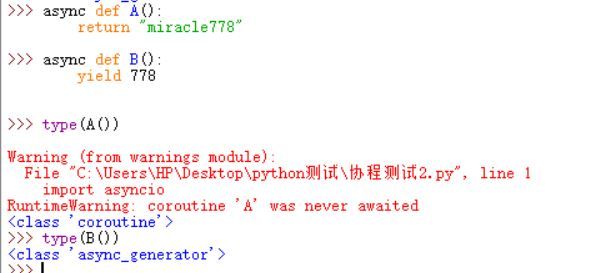
我们可以看到,图中的A函数是用return返回的,类型为协程类型,B函数 里面包含yield关键字,类型为异步生成器。
所以以async def开头声明的,函数代码里不含yield的是协程函数,含yield的是异步生成器。异步生成器可以用async for进行迭代。
import asyncio
async def Miracle():
print('Miracle778')
await asyncio.sleep(1)
for i in range(666,677):
yield i
async def get():
m = Miracle()
async for i in m:
i+=100
print(i)
loop = asyncio.get_event_loop()
loop.run_until_complete(get())
loop.close()
看到上面代码,最后三行是运行协程所需要的,后面会讲,我们来看到Miracle函数里的yield部分,如上面所说,这种函数是异步生成器,可以用async for迭代(见get函数),这里迭代了666 - 676 十个数,get函数里会把这十个数加100然后打印。执行结果如下图

async for迭代异步生成器介绍好了,下面我们再返回去看到协程函数,刚刚的截图里面,当我们输入type(A())的时候,Python shell有一个警告,RuntimeWarning: coroutine 'A' was never awaited。
这个警告信息说协程A永远不会等待,我们知道,协程最大的特点就是,在运行过程中,可以挂起然后去执行别的任务,待所需的条件满足后,再返回来执行挂起位置后续代码。而挂起操作,前面的yield/send型协程靠的是yield语句,这里的async/await则是靠await语句了。所以每个async类型的协程函数里面,应该要有await语句,不然就失去特性了,和普通函数一样,没有交替执行。
上面把 async、await两个关键字介绍了下,还给了个代码示例,里面用到了asyncio的一些函数。所以下面就要介绍这些函数了。讲到这里,有必要放下asyncio库的官方文档了
另外再放几篇别的相关文章:
Python 的异步 IO:Asyncio 简介
通读Python官方文档之协程、Future与Task
Python3 异步协程函数async具体用法
想要详细了解asyncio可以看上面几个链接,我这里就只简单讲讲自己用到的函数。
我们上面讲到过,协程不能直接运行,需要创建一个事件循环loop,再把协程注册到事件循环轰中,然后开启事件循环才能运行。这几步分别涉及的函数有
1 、创建事件循环
loop = asyncio.get_event_loop()
asyncio.get_event_loop()
获取当前事件循环。 如果当前 OS 线程没有设置当前事件循环并且 set_event_loop() 还没有被调用,asyncio 将创建一个新的事件循环并将其设置为当前循环。
2、 将协程注册到事件循环并开启
loop.run_until_complete(future)
运行直到 future ( Future 的实例 ) 被完成。
如果参数是 coroutine object ,将被隐式调度为 asyncio.Task 来运行。
返回 Future 的结果 或者引发相关异常。在注册事件循环的时候,其实是run_until_complete方法将协程包装成为了一个任务(task)对象。所谓task对象是Future类的子类。保存了协程运行后的状态,用于未来获取协程的结果,关于Future、Task类的详情请看上面链接
asyncio.ensure_future(coroutine) 和 loop.create_task(coroutine)都可以创建一个task
也就是说,注册事件循环有三种写法# 写法一 直接传入coroutine obeject 类型参数,隐式调度 import asyncio async def mriacle(): await xxxxx loop = asyncio.get_event_loop() loop.run_until_complete(miracle())# 写法二 使用asyncio.ensure_future(coroutine) 创建task传入 async def mriacle(): await xxxxx loop = asyncio.get_event_loop() task = asyncio.ensure_future(miracle()) loop.run_until_complete(task)# 写法三 使用loop.create_task(coroutine) 创建task传入 async def mriacle(): await xxxxx loop = asyncio.get_event_loop() task = loop.create_task(miracle()) loop.run_until_complete(task)这里关于写法二和写法三做个解释,写法二和三,都是将协程生成一个task对象。
而run_until_complete的参数是一个futrue对象。当传入一个协程,其内部会自动封装成task,task是Future的子类。isinstance(task, asyncio.Future)将会输出True。
上面都是通过 run_until_complete 来运行 loop ,等到 future 完成,run_until_complete 也就返回了。但还可以通过另一个函数 loop.run_forever 运行loop。不同的是,该函数等到 future 完成不会自动退出,得需要 loop.stop() 函数退出,且 loop.stop 函数不能写在 loop.run_forever 后面,得写在协程函数里。具体见下面例子
# 协程miracle await 0.1s test await 0.3s,miracle执行的更快,
# 调用完loop.stop后,事件循环结束,故test没有执行完毕就退出了
import asyncio
async def miracle():
print("coroutine miracle start")
await asyncio.sleep(0.1)
print("miracle end")
loop.stop()
async def test():
print("test start")
await asyncio.sleep(0.3)
print("test end")
loop = asyncio.get_event_loop()
task = loop.create_task(miracle())
task2 = loop.create_task(test())
loop.run_forever()
输出结果如下图

多个协程情况
上面 run_until_complete 传入的都只是一个task,当有多个协程的时候,该怎么传入呢
答案是用 asyncio.wait() asyncio.gather()函数
task1 = asyncio.ensure_future(demo1())
task2 = loop.create_task(demo2())
tasks = [task1,task2]
# asyncio.wait()
loop.run_until_complete(asyncio.wait(tasks))
# asyncio.gather()
loop.run_until_complete(asyncio.gather(*tasks))
asyncio库里还有一些用于 socket 编程函数,之前做网络编程实验的时候简单用过,具体见官方文档,这里就不讲了。
awaitable 对象
我们在上面举的代码例子里面的 await 后面都是加的asyncio.sleep函数或者是async def定义的协程,那么这个 await 右边能加些什么类型的对象呢? 我们可以试一下。
分隔线,以下几个是错误示例,错误示例,千万不要这样写*
本来是想着,如果一个协程读文件的时候,挂起让给另一个协程进行计算,然后等文件读完,返回去执行。但是,想法是好的,写起来难受,踩了好多坑,所以就有了下面几个错误示例,大家笑笑就好。。
# 错误写法一
import asyncio
import time
async def Read():
print("Read start")
f = open("C:\\Users\\HP\\Desktop\\1.gif",'rb')
await f.read()
print("Read end")
async def Calculate():
print("Calculate start")
start = time.time()
while time.time() - start < 2:
pass # 模拟计算消耗时间2s
await asyncio.sleep(0.1)
print("Calculate end")
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait([Read(),Calculate()]))
错误写法一,不清楚 await 右边能跟什么对象,所以直接 await f.read()了,于是有了报错
TypeError: object bytes can't be used in 'await' expression,报错信息说bytes型对象不能被用于await表达式,于是上官方文档搜搜 await 语法,找到了 PEP492文件 Coroutines with async and await syntax、英语版看不懂的这里还有个中文版可以结合参考参考PEP492翻译版
PEP492里有一段话,描述了什么是 awaitable

翻译一下就,await只接受awaitable对象,awaitable对象是以下的其中一个
1、由原生协程函数返回的原生协程对象 即使用 async def 声明的协程函数
2、由装饰器types.coroutine()装饰的一个“生成器实现的协程”对象
这里解释一下,"生成器实现的协程"就是指我们前面介绍的 yield from 这种类型
types.coroutune 是个装饰器,可以把生成器实现的协程 转化为与原生协程相兼容的形式,代码如下@types.coroutine def miracle(): i = yield from test() ···3、实现了await方法的对象(await方法返回的一个迭代器)
在asyncio库里面,有 Future 对象4、在CPython C API,有tp_as_async.am_await函数的对象,该函数返回一个迭代器(类似await方法)
报错原因
如果在async def函数之外使用await语句,会引发SyntaxError异常。这和在def函数之外使用yield语句一样。
如果await右边不是一个awaitable对象,会引发TypeError异常。
所以我们上面那样,直接调用 await f.read() 会引发TypeError异常。那应该怎么改呢?
回调 —— await 普通函数的方式
awaitable对象就上面那么几种情况,一个普通的函数的话,1跟2肯定就不符合了,只能是3——实现了__await__方法(class Future)
于是在官方文档里查看 Future 这一部分,发现有几个跟回调相关的函数。然后看了几个Demo后,我就写出了下面这段'错误代码',这段代码其实并没有错,但是他的执行时间跟顺序执行差不多,没有达到读文件的时候,cpu处理另一个计算任务的效果,原因等下在后面我会分析。
import asyncio
import time
def Read(future, f):
print("Read start")
start = time.time()
data = f.read()
print("Read用时",time.time()-start)
future.set_result("读取完毕")
f.close()
async def main(loop):
print("main start")
all_done = asyncio.Future() # 设置Future 对象
f = open("G:\\迅雷下载\\xxx.rmvb",'rb')
# 1.76Gb,读完时间大概20s左右
loop.call_soon(Read, all_done, f) # 安排Read函数尽快执行,后面是传入的参数
result = await all_done
# 若future对象完成,则会通过set_result函数设置并返回一个结果
print('returned result: {!r}'.format(result))
async def miracle():
print("miracle start")
await asyncio.sleep(0.1)
print("miracle running")
start = time.time()
while time.time() - start < 20: # 模拟计算20s
pass
print("miracle end")
event_loop = asyncio.get_event_loop()
start = time.time()
try:
event_loop.run_until_complete(asyncio.wait([miracle(),main(event_loop)]))
finally:
event_loop.close()
print("总用时",time.time()-start)
如上面代码示,这段代码是对错误代码1的改进,刚刚我们分析了await f.read()报错的原因,并且找到了解决方法,那就是把要进行的操作封装在一个函数里,这个函数要有一个接收Future对象的参数,然后协程函数里面,用asyncio.Future() 创建一个新的 Future 对象,然后用 loop.call_soon() 传入函数名及参数,安排我们之前封装的函数执行,然后就可以 await 传入的future对象,等待函数代码处理完成,通过 future.set_result() 设置并返回一个结果,await会接受这个结果。
所以我们可以得到 await 普通函数的方法,使用回调。
本来以为解决了这个问题,程序就能按我设想的那样子异步执行,读文件的时候挂起去执行另一个协程的计算,等文件读完后,再返回去处理。但事实却不是这样,本来按我的预想,给Read函数读的一个 1.7G的文件,读完需要20s左右,在读的时候挂起去执行miracle协程,miracle函数会空循环20s,然后再挂起,这时候Read函数和miracle协程都差不多要结束了,总时间应该是20多s。然而下面是运行结果图

可以看到,总运行时间为40s,没有达到异步的效果。对于这个问题,我后面搜了好久,分析了一下,得到结果如下
协程是用户自己控制切换的时机,不再需要陷入系统的内核态。而线程和进程,每次阻塞、切换都需要陷入系统调用,先让CPU跑操作系统的调度程序,然后再由调度程序决定该跑哪一个进程(线程)。
因为协程是用户自己写调度逻辑的,对CPU来说,协程其实是单线程,所以CPU不用去怎么调度、切换上下文。
因为我们这里main协程里用到了Python的内置文件操作,而Python内置文件操作调用的时候都是阻塞的,上面也说了,协程可视为单线程,因而一旦协程出现阻塞,将会阻塞整个线程,所以执行到读文件操作时,协程被阻塞,CPU只能等待文件读完。
所以说如果要达到上面的边读文件边计算的目的,还是用多线程。那么我们下面用多线程实现下
import threading
import time
def Read(f):
print("读文件线程开始\n")
start = time.time()
f.read()
end = time.time() - start
print("读文件线程结束,耗时",end)
start_main = time.time()
f = open("G:\\迅雷下载\\xx.rmvb",'rb')
th = threading.Thread(target=Read,args=(f,))
th.start()
print("主线程计算开始")
start = time.time()
while time.time()- start < 20: #模拟计算20s
pass
end = time.time()
print("主线程计算结束,耗时",end - start)
th.join()
print("总耗时",time.time()-start_main)
执行结果如下图

其实协程也可以调用多线程实现异步,通过loop.run_in_executor函数可以创建线程
import asyncio
import time
def Read(f):
print("Read start\n")
start = time.time()
f.read()
print("Read end 耗时",time.time()-start)
def miracle():
# 模拟计算
print("miracle start")
start = time.time()
while time.time() - start < 20:
pass
print("miracle end 耗时",time.time()-start)
async def main(f):
loop = asyncio.get_event_loop()
t = []
t.append(loop.run_in_executor(None,Read,f))
t.append(loop.run_in_executor(None,miracle))
for i in t:
await i
start = time.time()
f = open("G:\\迅雷下载\\xx.rmvb",'rb')
loop = asyncio.get_event_loop()
loop.run_until_complete(main(f))
print("总耗时",time.time()-start)
运行截图如下

总结
这协程、异步、多线程、阻塞I/O、非阻塞I/O,都要搞晕了。。。
就这样吧,留个大概印象,日后碰到了再回过头仔细研究。。。