原来用markdown写的,公式编辑比较麻烦。所以正常公式版本可以戳以下链接https://www.zybuluo.com/hainingwyx/note/386105
程序和数据的下载地址:http://www.tipdm.org/tj/661.jhtml
欢迎转载,转载注明出处即可。如有错误,请指正。
Python数据分析简介
Python入门
运行:cmd下"python hello.py"
基本命令:
# for 循环
s = 0
for k in range(101): #1-100
s = s + k
print s
# 函数
def add2(x):
return x+2
print add2(1)
def add2(x=0, y=0):
return [x+2, y+2] #返回列表
def add3(x, y):
return x+3, y+3 #双重返回
a,b = add3(1, 2)
# 匿名函数
f = lambda x : x+2 #定义函数f(x)= x+2
g = lambda x, y : x+y #定义函数g(x,y)= x+y, g(1,2)结果为3
# 数据结构
# a, b是列表
# 列表函数cmp(a, b) len(a) max(a) min(a) sum(a) sorted(a)
# 列表对象方法 a.append(1) a.count(1) a.extend([1,2]) a.index(1) a.insert(2,1) a.pop(1)
b = a # b是a的别名
b = a[:] #数据复制
# 列表解析
a = [1, 2, 3]
b = []
for i in a:
b.append(i+2)
# 等价于
a =[1, 2, 3]
b =[i + 2 for i in a]
# 集合
d = {'today' : 20, "tomorrow" : 30} #创建
d['today'] #访问
# 其他创建方法
dict(['today', 20], ['tomorrow', 30])
dict.fromkeys(['today', 'tomorrow'], 20)
# 集合
s = {1, 2, 2, 4}
s = set([1,2,2,4]) #自动去除多余的值
# 函数式编程 lambda, map, reduce, filter
b = map(lambda x :x+2, a)
b = list(b);
#2.x中不需要,3.x中需要,因为map仅仅创建了一个待运行的命令容器,只有其他函数调用时才返回结果
# map命令将函数逐一运用到map列表的每个元素中,,最后返回一个数组,效率比for循环高一点
# reduce函数用于递归运算
reduce(lambda x, y: x*y, range(1, n+1))
# filter 用于筛选列表中符合条件的元素
b = filter(lambda x :x > 5 and x <8, range(10))
b = list(b) # 同map
# 导入库
import math
math.sin(1)
import math as m
m.sin(1)
from math import exp as e
e(1)
sin(1) #出错
from math import * #直接导入,大量导入会引起命名冲突,不建议
exp(1)
sin(1)
# 导入future特征(2.x)
# 将print变为函数形式,即用print(a)格式输出
from __future__ import print_function
# 3.x中3/2=1.5, 3//2=1;2.x中3/2=1
from __future__ import division
第三方库
安装
Windows中
pip install numpy
或者下载源代码安装
python setup.py install
Pandas默认安装不能读写Excel文件,需要安装xlrd和xlwt库才能支持excel的读写
pip install xlrd
pip install xlwt
StatModel可pip可exe安装,注意,此库依赖于Pandas和patsy
Scikit-Learn是机器学习相关的库,但是不包含人工神经网络
model.fit() #训练模型,监督模型fit(X,y),非监督模型fit(X)
# 监督模型接口
model.predict(X_new) #预测新样本
model.predict_proba(X_new) #预测概率
model.score() #得分越高,fit越好
# 非监督模型接口
model.transform() #从数据中学到新的“基空间”
model.fit_transform() #从数据中学到新的基,并按照这组基进行转换
Keras是基于Theano的强化的深度学习库,可用于搭建普通神经网络,各种深度学习模型,如自编码器,循环神经网络,递归神经网络,卷积神经网络。Theano也是一个Python库,能高效实现符号分解,速度快,稳定性好,实现了GPU加速,在密集型数据处理上是CPU的10倍,缺点是门槛太高。Keras的速度在Windows会大打折扣。
Windows下:安装MinGWindows--安装Theano---安装Keras--安装配置CUDA
Gensim用来处理语言方面的任务,如文本相似度计算、LDA、Word2Vec等,建议在Windows下运行。
Linux中
sudo apt-get install python-numpy
sudo apt-get install python-scipy
sudo apt-get install python-matplotlib
使用
Matplotlib默认字体是英文,如果要使用中文标签,
plt.rcParams['font.sans-serif'] = ['SimHei']
保存作图图像时,负号显示不正常:
plt.rcParams['axes.unicode_minus'] = False
数据探索
脏数据:缺失值、异常值、不一致的值、重复数据
异常值分析
- 简单统计量分析:超出合理范围的值
- 3sigma原则:若正态分布,异常值定义为偏差超出平均值的三倍标准差;否则,可用远离平均值的多少倍来描述。
- 箱型图分析:异常值定义为小于Q_L-1.5IQR或者大于Q_U +1.5IQR。Q_L是下四分位数,全部数据有四分之一比他小。Q_U是上四分位数。IQR称为四分位数间距,IQR=Q_U-Q_L
#-*- coding: utf-8 -*-
import pandas as pd
catering_sale = '../data/catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure() #建立图像
p = data.boxplot() #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象
#用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
#xy表示要标注的位置坐标,xytext表示文本所在位置
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图
分布分析
定量数据的分布分析:求极差(max-min),决定组距和组数,决定分点,列出频率分布表,绘制频率分布直方图。
定性数据的分布分析:饼图或条形图
对比分析
统计量分析
集中趋势度量:均值、中位数、众数
离中趋势度量:极差、标准差、变异系数、四份位数间距
变异系数为:s表示标准差,x表示均值
#-*- coding: utf-8 -*-
#餐饮销量数据统计量分析
from __future__ import print_function
import pandas as pd
catering_sale = '../data/catering_sale.xls' #餐饮数据,一列为日期,一列为销量
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data = data[(data[u'销量'] > 400)&(data[u'销量'] < 5000)] #过滤异常数据
statistics = data.describe() #保存基本统计量
print(statistics)
print("--------------")
statistics.loc['range'] = statistics.loc['max']-statistics.loc['min'] #极差
statistics.loc['var'] = statistics.loc['std']/statistics.loc['mean'] #变异系数
statistics.loc['dis'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距
print(statistics)
周期性分析
贡献度分析
又称帕累托分析,原理是帕累托法则,即20/80定律,同样的投入放在不同的地方会产生不同的收益。
#-*- coding: utf-8 -*-
#菜品盈利数据 帕累托图
from __future__ import print_function
import pandas as pd
#初始化参数
dish_profit = '../data/catering_dish_profit.xls' #餐饮菜品盈利数据,菜品ID,菜品名 盈利
data = pd.read_excel(dish_profit, index_col = u'菜品名')
data = data[u'盈利'].copy()#保留两列数据
data.sort(ascending = False)
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure()
data.plot(kind='bar')
plt.ylabel(u'盈利(元)')
p = 1.0*data.cumsum()/data.sum()
p.plot(color = 'r', secondary_y = True, style = '-o',linewidth = 2)
plt.annotate(format(p[6], '.4%'), xy = (6, p[6]), xytext=(6*0.9, p[6]*0.9),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
#添加注释,即85%处的标记。这里包括了指定箭头样式。
plt.ylabel(u'盈利(比例)')
plt.show()
相关性分析
途径:绘制散点图、散点图矩阵、计算相关系数
Pearson相关系数:要求连续变量的取值服从正态分布。
$$
\begin{cases}
{|r|\leq 0.3}&\text{不存在线性相关}\
0.3 < |r| \leq 0.5&\text{低度线性相关}\
0.5 < |r| \leq 0.8&\text{显著线性相关}\
0.8 < |r| \leq 1&\text{高度线性相关}\
\end{cases}
$$
相关系数r的取值范围[-1, 1]
Spearman相关系数:不服从正态分布的变量、分类或等级变量之间的关联性可用该系数,也称等级相关系数。
对两个变量分别按照从小到大的顺序排序,得到的顺序就是秩。R_i表示x_i的秩次,Q_i表示y_i的秩次。
判定系数:相关系数的平方,用来解释回归方程对y的解释程度。
#-*- coding: utf-8 -*-
#餐饮销量数据相关性分析
from __future__ import print_function
import pandas as pd
catering_sale = '../data/catering_sale_all.xls' #餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data.corr() #相关系数矩阵,即给出了任意两款菜式之间的相关系数
data.corr()[u'百合酱蒸凤爪'] #只显示“百合酱蒸凤爪”与其他菜式的相关系数
data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺']) #计算“百合酱蒸凤爪”与“翡翠蒸香茜饺”的相关系数
数据探索函数
| 方法名 | 函数功能 |
|---|---|
| D.sum() | 按列计算总和 |
| D.mean() | 计算算数平均 |
| D.var() | 方差 |
| D.std() | 标准差 |
| D.corr(method = ' pearson') | Spearman(Pearson)相关系数矩阵 |
| D.cov() | 协方差矩阵 |
| D.skew() | 偏度(三阶矩) |
| D.kurt() | 峰度(四阶距) |
| D.describe() | 给出样本的基础描述 |
D = pd.DataFrame([range(1,8), range(2, 9)])
D.corr(method = 'spearman') #计算相关系数矩阵
S1 = D.loc[0] #提取第一行
S2 = D.loc[1] #提取第二行
S1.corr(S2, method = 'pearson') #计算S1S2的相关系数
D = pd.DataFrame(np.random.randn(6, 5)) #产生6x5的表格
print D.cov()
print D[0].cov(D[1]) #计算第一列和第二列的方差
print D.skew() #D是DataFrame或者Series
print D.describe()
| 方法名 | 函数功能 |
|---|---|
| cumsum() | 依次给出前1-n个数的和 |
| cumprod() | 依次给出前1-n个数的积 |
| cummax() | 依次给出前1-n个数的最大值 |
| cummin() | 依次给出前1-n个数的最小值 |
| 方法名 | 函数功能 |
|---|---|
| rolling_sum() | 按列计算数据样本的总和 |
| rolling_mean() | 算数平均数 |
| rolling_var() | 方差 |
| rolling_std() | 标准差 |
| rolling_corr() | 相关系数矩阵 |
| rolling_cov() | 协方差 |
| rolling_skew() | 偏度 |
| rolling_kurt() | 峰度 |
D = pd.Series(range(0,20))
print D.cumsum()
print pd.rolling_sum(D, 2) #依次对相邻两项求和
| 方法名 | 函数功能 |
|---|---|
| plot() | 绘制线性二维图,折线图 |
| pie() | 绘制饼形图 |
| hist() | 绘制二维条形直方图,可现实数据的分配情形 |
| boxplot() | 绘制箱型图 |
| plot(logy = True) | 绘制y轴的对数图形 |
| plot(yerr = error) | 绘制误差条形图 |
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure(figsize = (7, 5)) #创建图像区域,指定比例
plt.show() #显示作图结果
############################################################################################
x = np.linspace(0, 2*np.pi, 50)
y = np.sin(x)
plt.plot(x, y, 'bp--') #蓝色带星虚线plt.show()
############################################################################################
labels = 'Frogs', 'Hogs', 'Dogs', 'Logs'
sizes = [15, 30, 45, 10] #每一块的比例
colors = ['yellowgreen', 'gold', 'lightskyblue', 'lightcoral']
explode = (0, 0.1, 0, 0)
plt.pie(sizes, explode = explode, labels = labels, colors = colors, autopct =
'%1.1f%%', shadow = True, startangle = 90)
plt.axis('equal') #显示为圆
plt.show()
############################################################################################
x = np.random.randn(1000) #1000个服从正态分布的随机数
plt.hist(x, 10) #分成10组
plt.show()
############################################################################################
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
x = np.exp(np.arange(20)) #原始数据
plt.subplot(121)
plt.plot(range(0,20), x, label = u"原始数据图")
plt.legend()
plt.subplot(122)
plt.semilogy(range(0,20), x, label = u"对数数据图")
plt.legend()
plt.show()
############################################################################################
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
error = np.random.random(10) #定义误差条例
y = pd.Series(np.sin(np.arange(10)))
y.plot(yerr = error)
plt.show()
数据预处理
数据清洗
包括:删除原始数据中的无关数据、重复数据,平滑噪声数据,处理缺失值。
拉格朗日插值法:
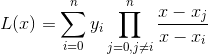
当插值节点增减时,插值多项式就会发生变化,在实际计算中不方便。
牛顿插值法:P(x)是牛顿插值逼近函数,R(x)是误差函数
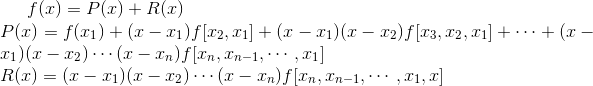
Python的Scipy库中只提供了拉格朗日插值法的函数(实现上比较容易)
#-*- coding: utf-8 -*-
# 插值时存在问题,不同的位置选取的数据点不一样,并且保证最后的数据是正确的
# 目前没有考虑连续脏数据的情况
#拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = '../data/catering_sale.xls' #销量数据路径
outputfile = '../tmp/sales.xls' #输出数据路径
data = pd.read_excel(inputfile) #读入数据
data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5,插值不要超过20
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数,y是长度为10的列表
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值多项式,代入n得到插值结果
#逐个元素判断是否需要插值
k = 2
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
if (j >= k) and (j < len(data) - k):
y = data[i][list(range(j-k, j)) + list(range(j+1, j+1+k))] #取数,y是长度为10的列表
elif j < k :
y = data[i][list(range(0, j)) + list(range(j+1, 2 * k + 1))]
elif j >= len(data) - k:
y = data[i][list(range(len(data) - 1 - 2 * k, j)) + list(range(j+1, len(data)))]
y = y[y.notnull()] #剔除空值
data[i][j] = lagrange(y.index, list(y))(j) #插值并返回插值多项式,代入j得到插值结果
data.to_excel(outputfile) #输出结果,写入文件
数据集成
包括实体识别,冗余属性识别
数据变化
简单函数变换
规范化
- 离差标准化(最小最大规范化)
- 标准差标准化
- 小数定标规范化:属性值映射在[-1, 1]之间
#-*- coding: utf-8 -*-
#数据规范化
import pandas as pd
import numpy as np
datafile = '../data/normalization_data.xls' #参数初始化
data = pd.read_excel(datafile, header = None) #读取数据,矩阵
print (data - data.min())/(data.max() - data.min()) #最小-最大规范化,按列出路
print (data - data.mean())/data.std() #零-均值规范化
print data/10**np.ceil(np.log10(data.abs().max())) #小数定标规范化
连续属性离散化
等宽法(至于相同宽度)、等频法(将相同数量的记录放进每个区间)、基于聚类分析的方法(K-means)
import pandas as pd
from sklearn.cluster import KMeans #引入KMeans
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
datafile = '../data/discretization_data.xls' #参数初始化
data = pd.read_excel(datafile) #读取数据
data = data[u'肝气郁结证型系数'].copy()
k = 4 #分为4类
d1 = pd.cut(data, k, labels = range(k)) #等宽离散化,各个类比依次命名为0,1,2,3
#等频率离散化
w = [1.0*i/k for i in range(k+1)] #为describe确定分位数0%,25%,50%,75%,100%
w = data.describe(percentiles = w)[4:4+k+1] #使用describe函数自动计算分位数并取出分位数
w[0] = w[0]*(1-1e-10) #确保比最小值小
d2 = pd.cut(data, w, labels = range(k))
kmodel = KMeans(n_clusters = k, n_jobs = 1) #建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data.reshape((len(data), 1))) #训练模型
c = pd.DataFrame(kmodel.cluster_centers_).sort(0) #输出聚类中心,并且排序(默认是随机序的)
w = pd.rolling_mean(c, 2).iloc[1:] #相邻两项求中点,作为边界点
w = [0] + list(w[0]) + [data.max()] #把首末边界点加上
d3 = pd.cut(data, w, labels = range(k))
def cluster_plot(d, k): #自定义作图函数来显示聚类结果
plt.figure(figsize = (8, 3))
for j in range(0, k):
plt.plot(data[d==j], [j for i in d[d==j]], 'o')
plt.ylim(-0.5, k-0.5)
return plt
cluster_plot(d1, k).show()
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()
属性构造:比如利用供入电量和供出电量计算线损率。
#-*- coding: utf-8 -*-
#线损率属性构造
import pandas as pd
#参数初始化
inputfile= '../data/electricity_data.xls' #供入供出电量数据
outputfile = '../tmp/electricity_data.xls' #属性构造后数据文件
data = pd.read_excel(inputfile) #读入数据
data[u'线损率'] = (data[u'供入电量'] - data[u'供出电量'])/data[u'供入电量']
data.to_excel(outputfile, index = False) #保存结果
小波变换
用于非平稳信号的时频分析。基于小波变换的主要方法有:多尺度空间能量分布特征提取、多尺度空间的模极大值特征提取、小波包变换的特征提取、适应性小波神经网络的特征提取。
小波基函数:Harry小波基,db系列小波基,均值为0。积分为0.
小波变换:a是伸缩因子,b是平移因子,对小波基函数进行伸缩和平移变换
任意函数f(t)的连续小波变换(CWT)为:
在约束条件下有逆变换:
python中scipy本身提供了信号处理函数,更好的信号处理库是PyWavelets(pywt)。
#小波特征变换提取代码
import pywt #导入PyWavelets
from scipy.io import loadmat #mat是MATLAB专用格式,需要用loadmat读取它
#参数初始化
inputfile= '../data/leleccum.mat' #提取自Matlab的信号文件
mat = loadmat(inputfile)
signal = mat['leleccum'][0]
coeffs = pywt.wavedec(signal, 'bior3.7', level = 5)
#返回结果为level+1个数字,第一个数组为逼近系数数组,后面的依次是细节系数数组
数据规约
属性规约:合并属性,逐步向前选择,逐步向后删除,决策树归纳,主成分分析。
主成分分析步骤:
- 设原始变量X_1,X_2,..., X_p的n次观测数据矩阵为:
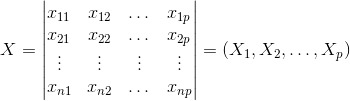
- 将数据矩阵按列进行中心标准化
- 求相关系数矩阵R,$$R=(r_{ij})_{p\times p}$$
其中,
-
求R的特征方程
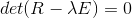
的特征根
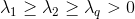
- 确定主成分个数m:alpha根据实际问题确定,一般取0.8
- 计算m个相应的单位特征向量:
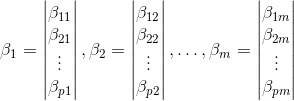
- 计算主成分:
import pandas as pd
from sklearn.decomposition import PCA
#参数初始化
inputfile = '../data/principal_component.xls'
outputfile = '../tmp/dimention_reducted.xls' #降维后的数据
data = pd.read_excel(inputfile, header = None) #读入数据
pca = PCA()
pca.fit(data)
print pca.components_ #返回模型的各个特征向量
print pca.explained_variance_ratio_ #返回各个成分各自的方差百分比
#由上面可以看出前4个已经占了97%
pca = PCA(3)
pca.fit(data)
low_d = pca.transform(data) #降低唯独
pd.DataFrame(low_d).toexcel(outputfile) #保存结果
pca.inverse_transform(low_d) #复原数据
数值规约:通过选择替代的、较小的数据来减少数据量。
Python主要数据预处理函数
| 函数名 | 函数功能 |
|---|---|
| interpolate | 一维、高维数据插值 |
| unique | 去除数据终端额重复数据 |
| isnull | 判断是否空值 |
| notnull | 判断是否非空值 |
| PCA | 主成分分析 |
| random | 生成随机矩阵 |
f = scipy.interpolate.lagrange(x,y) #一维数据的拉格朗日插值
f(2) #计算插值结果
###################################################################
D = pd.Series([1,2,1,3,5])
D.unique()
np.uinque(D) #这时候D可以是list,array,Series
###################################################################
D.isnull() #D是series对象,返回布尔Series,D[D.isnull()]找到空值
###################################################################
np.random.rand(k,m,n) #0-1均匀分布
np.random.randn(k,m,n) #标准正态分布
挖掘建模
分类与预测
常用算法:回归分析、决策树、人工神经网络、贝叶斯网络、支持向量机。
Logistic回归
Logistic函数:
回归模型:
#-*- coding: utf-8 -*-
#逻辑回归 自动建模
import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
from sklearn.linear_model import RandomizedLogisticRegression as RLR
#参数初始化
filename = '../data/bankloan.xls'
data = pd.read_excel(filename)
x = data.iloc[:,:8].as_matrix()##变成矩阵
y = data.iloc[:,8].as_matrix()
rlr = RLR() #建立随机逻辑回归模型,筛选变量
rlr.fit(x, y) #训练模型
rlr.get_support() #获取特征筛选结果,也可以通过.scores_方法获取各个特征的分数
print(u'通过随机逻辑回归模型筛选特征结束')
#join() 表示连接,使用逗号,括号内必须是一个对象。如果有多个就编程元组,或是列表。
print(u'有效特征为:%s' % ','.join(data.columns[rlr.get_support()]))
x = data[data.columns[rlr.get_support()]].as_matrix() #筛选好特征
lr = LR() #建立逻辑货柜模型
lr.fit(x, y) #用筛选后的特征数据来训练模型
print(u'逻辑回归模型训练结束。')
print(u'模型的平均正确率为:%s' % lr.score(x, y)) #给出模型的平均正确率,本例为81.4%
Scikit-Learn提供了REF包可以用于特征消除。还提供了REFCV,可以通过交叉验证来对特征进行排序。
决策树
ID3、C4.5、CART算法
ID3:在决策树的各级节点上都用信息增益作为判断标准进行属性的选择,使得在每个节点上都能获得最大的类别分类增益,使分类后的额数据集的熵最小,这样使得树的平均深度最小,从而有效地提高了分类效率。
步骤:
- 对当前样本集合,计算所有属性的信息增益
- 选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集
- 若子样本集的类别只有单个,则分支为叶节点;否则对子样本集循环调用本算法
#-*- coding: utf-8 -*-
#使用ID3决策树算法预测销量高低
import pandas as pd
from sklearn.tree import export_graphviz
from sklearn.externals.six import StringIO
from sklearn.tree import DecisionTreeClassifier as DTC
#参数初始化
inputfile = '../data/sales_data.xls'
data = pd.read_excel(inputfile, index_col = u'序号') #导入数据
#数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用-1来表示“坏”、“否”、“低”
data[data == u'好'] = 1
data[data == u'是'] = 1
data[data == u'高'] = 1
data[data != 1] = -1
x = data.iloc[:,:3].as_matrix().astype(int)
y = data.iloc[:,3].as_matrix().astype(int)
dtc = DTC(criterion='entropy') #建立决策树模型,基于信息熵
dtc.fit(x, y) #训练模型
#导入相关函数,可视化决策树。
#导出的结果是一个dot文件,需要安装Graphviz才能将它转换为pdf或png等格式。
with open("tree.dot", 'w') as f:
f = export_graphviz(dtc, feature_names = ['tianqi', 'zhoumo', 'cuxiao'], out_file = f)
#f = export_graphviz(dtc, feature_names = [u'天气', u'周末', u'促销'], out_file = f)
#文本打开指定中文字体
#edge [fontname = "SimHei"];/*添加,指定中文为黑体*/
#node [fontname = "SimHei"];/*添加,指定中文为黑体*/
#安装Graphviz
#在命令行中编译
人工神经网络
#-*- coding: utf-8 -*-
#使用神经网络算法预测销量高低
import pandas as pd
#参数初始化
inputfile = '../data/sales_data.xls'
data = pd.read_excel(inputfile, index_col = u'序号') #导入数据
#数据是类别标签,要将它转换为数据
#用1来表示“好”、“是”、“高”这三个属性,用0来表示“坏”、“否”、“低”
data[data == u'好'] = 1
data[data == u'是'] = 1
data[data == u'高'] = 1
data[data != 1] = 0
x = data.iloc[:,:3].as_matrix().astype(int)
y = data.iloc[:,3].as_matrix().astype(int)
from keras.models import Sequential
from keras.layers.core import Dense, Activation
model = Sequential() #建立模型
model.add(Dense(3, 10))
model.add(Activation('relu')) #用relu函数作为激活函数,能够大幅提供准确度
model.add(Dense(10, 1))
model.add(Activation('sigmoid')) #由于是0-1输出,用sigmoid函数作为激活函数
model.compile(loss = 'binary_crossentropy', optimizer = 'adam', class_mode = 'binary')
#编译模型。由于我们做的是二元分类,所以我们指定损失函数为binary_crossentropy,以及模式为binary
#另外常见的损失函数还有mean_squared_error、categorical_crossentropy等,请阅读帮助文件。
#求解方法我们指定用adam,还有sgd、rmsprop等可选
model.fit(x, y, nb_epoch = 1000, batch_size = 10) #训练模型,学习一千次
yp = model.predict_classes(x).reshape(len(y)) #分类预测
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(y,yp).show() #显示混淆矩阵可视化结果
算法评价:相对误差、均方误差、识别准确度、识别精确率、ROC曲线
聚类分析
K-Means算法
#-*- coding: utf-8 -*-
#使用K-Means算法聚类消费行为特征数据
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
#参数初始化
inputfile = '../data/consumption_data.xls' #销量及其他属性数据
outputfile = '../tmp/data_type.xls' #保存结果的文件名
k = 3 #聚类的类别
iteration = 500 #聚类最大循环次数
data = pd.read_excel(inputfile, index_col = 'Id') #读取数据
data_zs = 1.0*(data - data.mean())/data.std() #数据标准化
model = KMeans(n_clusters = k, n_jobs = 1, max_iter = iteration) #分为k类,并发数4
model.fit(data_zs) #开始聚类
#简单打印结果
r1 = pd.Series(model.labels_).value_counts() #统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) #找出聚类中心
r = pd.concat([r2, r1], axis = 1) #横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(data.columns) + [u'类别数目'] #重命名表头
print(r) #打印分类中心和分类数量
#详细输出原始数据及其类别
r = pd.concat([data, pd.Series(model.labels_, index = data.index)], axis = 1) #详细输出每个样本对应的类别
r.columns = list(data.columns) + [u'聚类类别'] #重命名表头
r.to_excel(outputfile) #保存分类结果
def density_plot(data): #自定义作图函数
p = data.plot(kind='kde', linewidth = 2, subplots = True, sharex = False)
[p[i].set_ylabel(u'密度') for i in range(k)]
plt.legend()
return plt
pic_output = '../tmp/pd_' #概率密度图文件名前缀
for i in range(k):
density_plot(data[r[u'聚类类别']==i]).savefig(u'%s%s.png' %(pic_output, i))
聚类算法评价:purity评价法、RI评价法、F值评价法
| 对象名 | 函数功能 |
|---|---|
| KMeans | K均值聚类 |
| AffinityPropagation | 吸引力传播聚类 |
| SpectralClustering | 谱聚类,由于KMeans |
| AgglomerativeClustering | 层次聚类 |
| DBSCAN | 具有噪声的基于密度的聚类算法 |
| MeanShift | 均值漂移聚类算法 |
| BIRCH | 层次聚类算法,可以处理大规模数据 |
先用对应的函数建立模型,然后使用fit方法训练模型,之后用label_方法给出样本数据的标签,或者用predict方法预测新的输入的标签。
TENSE:提供一种有效地数据降维的方式,在2维或者3维战士聚类结果。
#-*- coding: utf-8 -*-
#接k_means.py
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
tsne = TSNE()
tsne.fit_transform(data_zs) #进行数据降维
tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) #转换数据格式
#不同类别用不同颜色和样式绘图
d = tsne[r[u'聚类类别'] == 0]
plt.plot(d[0], d[1], 'r.')
d = tsne[r[u'聚类类别'] == 1]
plt.plot(d[0], d[1], 'go')
d = tsne[r[u'聚类类别'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.show()
关联分析
常用算法:Apriori、FP-Tree、Eclt算法、灰色关联法
Ariori算法
支持度:
,A、B同时发生的概率
置信度:
A发生B发生的概率
同时满足最小支持度和最小置信度称满足强规则
算法步骤:
- 扫描事物集,得到没个候选项的支持度
- 比较候选支持度与最小支持度,得到1项频繁集L_1
- 由L_1产生候选项集C_2,并计算支持度
- 比较候选支持度和最小支持度,得到2项频繁集L_2
- 类推,直至不能产生新的候选项集
#-*- coding: utf-8 -*-
from __future__ import print_function
import pandas as pd
#自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r
#寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果
support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0
while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数
#创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T
support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1])
cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列
for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])]
for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n结果为:')
print(result)
return result
#######################################################33
#-*- coding: utf-8 -*-
#使用Apriori算法挖掘菜品订单关联规则
from __future__ import print_function
import pandas as pd
from apriori import * #导入自行编写的apriori函数
inputfile = '../data/menu_orders.xls'
outputfile = '../tmp/apriori_rules.xls' #结果文件
data = pd.read_excel(inputfile, header = None)
print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #1表示逐行转换。转换0-1矩阵的过渡函数
b = map(ct, data.as_matrix()) #用map方式执行,b是list
data = pd.DataFrame(b).fillna(0) #空值用0填充
print(u'\n转换完毕。')
del b #删除中间变量b,节省内存
support = 0.2 #最小支持度
confidence = 0.5 #最小置信度
ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符
find_rule(data, support, confidence, ms).to_excel(outputfile) #保存结果
时序模式
非平稳时间序列分析:许多非平稳序列差分后会显示出平稳序列的性质,这时称之为差分平稳序列,可以先做差分然后用ARMA模型进行拟合。这种方法称之为ARIMA模型。
#-*- coding: utf-8 -*-
#arima时序模型
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.tsa.stattools import adfuller as ADF
from statsmodels.graphics.tsaplots import plot_pacf
from statsmodels.stats.diagnostic import acorr_ljungbox
from statsmodels.tsa.arima_model import ARIMA
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
#参数初始化
discfile = '../data/arima_data.xls'
forecastnum = 5
#读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式
data = pd.read_excel(discfile, index_col = u'日期')
#时序图
data.plot()
plt.show()
plt.title('Time Series')
#自相关图
plot_acf(data).show()
#平稳性检测
print(u'原始序列的ADF检验结果为:', ADF(data[u'销量']))
#返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore
#差分后的结果
D_data = data.diff().dropna()
D_data.columns = [u'销量差分']
D_data.plot() #时序图
plt.show()
plot_acf(D_data).show() #自相关图
plot_pacf(D_data).show() #偏自相关图
print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分'])) #平稳性检测
#白噪声检验
print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1)) #返回统计量和p值
data[u'销量'] = data[u'销量'].astype(float)
#定阶
pmax = int(len(D_data)/10) #一般阶数不超过length/10
qmax = int(len(D_data)/10) #一般阶数不超过length/10
bic_matrix = [] #bic矩阵
for p in range(pmax+1):
tmp = []
for q in range(qmax+1):
try: #存在部分报错,所以用try来跳过报错。
tmp.append(ARIMA(data, (p,1,q)).fit().bic)
except:
tmp.append(None)
bic_matrix.append(tmp)
bic_matrix = pd.DataFrame(bic_matrix) #从中可以找出最小值
p,q = bic_matrix.stack().idxmin() #先用stack展平,然后用idxmin找出最小值位置。
print(u'BIC最小的p值和q值为:%s、%s' %(p,q))
model = ARIMA(data, (p,1,q)).fit() #建立ARIMA(0, 1, 1)模型
model.summary2() #给出一份模型报告
model.forecast(5) #作为期5天的预测,返回预测结果、标准误差、置信区间。
| 函数名 | 函数功能 |
|---|---|
| acf | 计算自相关系数 |
| plot_acf | 画自相关系数图 |
| pacf | 计算偏相关系数 |
| plot_pacf | 画图 |
| adfuller | 单位根检验 |
| diff | 差分运算 |
| ARIMA | 创建模型 |
| summary | 给出ARIMA模型的报告 |
| aic/bic/hqic | 计算ARIMA模型的指标 |
| forecast | 预测 |
| acorr_ljungbox | Ljung-Box检验,是否白噪声 |
autocorr = acf(data, unbiased = False, nlags = 40, qstat = False, fft = False, alpha = False)
# data 为观测值序列(时间序列),可以是DataFrame或者Series
h = adfuller(Series, maxlag = None, Regression = 'c', autolog = 'AIC', store = False, regresults =False)
D.diff() #D为Pandas的DataFrame或Series
arima = ARIMA(data, (p, 1, q)).fit() #data为输入的时间序列,p,q为对应的阶
amima.summary() #返回一份格式化的模型报告
arima.bic
a,b,c = arima.forecast(num) #num为要预测的天数,a为返回的预测值,b为预测误差,c为置信区间
离群点检测
方法:基于统计、基于邻近度、基于密度、基于聚类。
基于统计:一元正态分布若数据点在3倍标准差之外。
混合模型的离群点检测:数据的统计分布未知或者没有训练数据可用,很难建立模型。
基于原型的聚类:聚类所有的对象,然后评估对象属于簇的程度。如果删除一个对象导师制该目标显著改进,则可将该对象视为离群点。离群点可能形成小簇从而逃避检测。
#-*- coding: utf-8 -*-
#使用K-Means算法聚类消费行为特征数据
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
#参数初始化
inputfile = '../data/consumption_data.xls' #ID 和三个属性
k = 3 #聚类的类别
threshold = 2 #离散点阈值
iteration = 500 #聚类最大循环次数
data = pd.read_excel(inputfile, index_col = 'Id') #读取数据
data_zs = 1.0*(data - data.mean())/data.std() #数据标准化
model = KMeans(n_clusters = k, n_jobs = 1, max_iter = iteration) #分为k类,并发数4
model.fit(data_zs) #开始聚类
#标准化数据及其类别
r = pd.concat([data_zs, pd.Series(model.labels_, index = data.index)], axis = 1) #每个样本对应的类别
r.columns = list(data.columns) + [u'聚类类别'] #重命名表头
norm = []
for i in range(k): #逐一处理
norm_tmp = r[['R', 'F', 'M']][r[u'聚类类别'] == i]-model.cluster_centers_[i]
norm_tmp = norm_tmp.apply(np.linalg.norm, axis = 1) #求出绝对距离
norm.append(norm_tmp/norm_tmp.median()) #求相对距离并添加
norm = pd.concat(norm) #合并
norm[norm <= threshold].plot(style = 'go') #正常点
discrete_points = norm[norm > threshold] #离群点
discrete_points.plot(style = 'ro')
for i in range(len(discrete_points)): #离群点做标记
id = discrete_points.index[i]
n = discrete_points.iloc[i]
plt.annotate('(%s, %0.2f)'%(id, n), xy = (id, n), xytext = (id, n))#有标注的点是离群点
plt.xlabel(u'编号')
plt.ylabel(u'相对距离')
plt.show()
电力窃漏电用户自动识别
数据分析:
- 分布分析:用户类别窃漏电情况分布发现,非居民类不存在漏电情况。故可清理
- 周期性分析:找到一个正常的用户和漏电用户,分别观察规律。发现正常用户有明显的周期性。
数据预处理
- 数据清洗:过滤掉非居民类的数据和节假日数据。
- 缺失值处理:拉格朗日插补法进行插补
- 数据变换:用电趋势指标、5天平均线损率、告警指标计数
模型构建
- 用LM神经网络和CART决策树模型建模
- ROC曲线比较性能
航空公司客户价值分析
数据分析:缺失值分析和异常值分析,异常值看最大和最小值
数据预处理:
- 数据清洗,丢弃缺失值、票价为0折扣率不为0的数据
- 属性规约,删除不相关或者弱相关属性
- 数据变换:计算指标,并对数据进行标准化处理
模型构建
- K-Means算法对客户数据进行分群,分为5类。
- 结合图表对结果进行分析
中医证型关联规则挖掘
数据预处理
- 数据清洗:删除整理无效问卷
- 属性规约:将冗余属性和无关属性删除
- 数据变换:构造属性,并将属性离散化
模型构建
采用Apriori关联规则算法对模型的样本数据进行分析,以模型参数设置的最小支持度和最小置信度作为条件,输出关联规则结果。
基于水色图像的水质评价
数据预处理
- 图像切割:提取水样图像中间部分具有代表意义的图像
- 特征提取:颜色的一阶、二阶、三阶矩
模型构建
为提高区分度,将所有特征乘以常数k。然后建立支持向量机模型。
水质评价
对新增的水质图像作评价。
家用电器用户行为分析与事件识别
数据预处理
- 数据规约:去除无用的属性和状态
- 数据变换:确定用水事件的阈值
- 数据清洗
模型构建:训练神经网络
模型检验:使用测试数据
应用系统负载分析与磁盘容量预测
数据分析:通过时序图观察数据的平稳性和周期性
数据预处理
- 数据清洗:删除重复值
- 属性构造:合并属性
模型构建
- 检验平稳性,单位根检验
- 白噪声检验
- 模型识别:采用极大似然比方法进行模型的参数估计,采用BIC信息准则对模型进行定阶。ARIMA(0,1,1)
- 模型检验:检验模型残差序列是否为白噪声如果不是,说明还有未提取的有用信息,需要修改模型。
模型评价:计算平均绝对误差,均方根误差
电子商务网站用户行为分析及服务推荐
数据抽取:建立数据库--导入数据--搭建Python数据库操作环境
数据分析
- 网页类型分析
- 点击次数分析
- 网页排名
数据预处理
- 数据清洗:删除数据(中间页面网址、发布成功网址、登录助手页面)
- 数据变化:识别翻页网址并去重,错误分类网址手动分类,并进一步分类
- 属性规约:只选择用户和用户选择的网页数据
模型构建
基于物品的协同滤波算法:计算物品之间的相似度,建立相似度矩阵;根据物品的相似度和用户的历史行为给用户生成推荐列表。
相似度计算方法:夹角余弦、Jaccard系数、相关系数
财政收入影响因素分析及预测模型
数据分析
- 描述性统计分析
- 相关分析
模型构建
对于财政收入、增值税、营业税、企业所得税、政府性基金、个人所得税
- Adaptive-Lasso变量选择模型:去除无关变量
- 分别建立灰色预测模型与神经网络模型
基于基站定位数据的商圈分析
数据预处理
- 属性规约:删除冗余属性,合并时间属性
- 数据变换:计算工作日人均停留时间、凌晨、周末、日均等指标,并标准化。
模型构建
- 构建商圈聚类模型:采用层次聚类算法
- 模型分析:对聚类结果进行特征观察
电商产品评论数据情感分析
文本采集:八爪鱼采集器(爬虫工具)
文本预处理:
- 文本去重:自动评价、完全重复评价、复制的评论
- 机械压缩去词:
- 删除短句
文本评论分词:采用Python中文分词包“Jieba”分词,精度达97%以上。
模型构建
- 情感倾向性模型:生成词向量;评论集子集的人工标注与映射;训练栈式自编码网络
- 基于语义网络的评论分析
- 基于LDA模型的主题分析