环境:Windows 10、 java version "1.8.0_144" 、 Python 3.6.3、 jieba 0.39
方法一:jieba分词+词云工具(WordArt.com)
一、获取短评数据
对获取到的短评进行数据的清洗与整理,将数据放入名为review.txt文件里:

整理后的短评文件示图
二、利用jieba进行分词
分词主代码(review.py)
from __future__ import print_function, unicode_literals
import jieba
jieba.load_userdict("userdict.txt") #自定义词典
path = 'review.txt' #存放短评数据的文件
file_in = open(path, 'r',encoding='UTF-8') #打开review.txt文件,对文件进行读操作
content = file_in.read()
import jieba.analyse
try:
jieba.analyse.set_stop_words('stop.txt') #停用词词典
tags = jieba.analyse.extract_tags(content, topK=50, withWeight=True) #选择前50个关键词,并计算对应权重
for v, n in tags:
print (v + '\t' + str(int(n * 10000))) #权重是小数,为了凑整,乘以10000,也可以直接输出,但数据看起来会复杂点
finally:
file_in.close() # 关闭文件
停用词词典(stop.txt):
经过多次分词,将分词结果中常常出现的且意义不大的词加入到停用词词典,提高分词的结果的高效和有效性,(注:一个词一行,并且保存文件时需要以utf-8形式保存)下面是部分停用词举例:
一部
片子
真的
这部
还是
这样
不是
非常
最后
看到
这个
呜呜
就是
什么
但是
可以
觉得
有点
每个
很多
一种
所有
其实
有些
已经
观众
上映
值得
后半段
人物
意义
韩国
这种
问题
剧本
自己
配角
……
自定义词典(userdict.txt):
短评中出现了两部相关电影的名字,但是jieba分词没有分出来因此在自定义词典中进行定义如下:
达拉斯买家俱乐部
辛德勒名单
三、关键词提取结果
通过命令行进入到在对应的目录下输入:
python review.py
结果如下:
徐峥 817
煽情 722
题材 672
现实 576
王传君 481
药神 468
故事 404
达拉斯买家俱乐部 347
国产电影 301
真实 299
黄毛 276
穷病 267
周一围 267
社会 266
现实主义 259
希望 256
好看 229
程勇 214
改编 213
商业片 209
牧野 206
难得 189
泪点 160
过审 160
角色 149
宁浩 147
人性 146
不错 145
活着 142
感动 135
医保 134
原型 131
最佳 128
喜欢 121
四星 121
国产 120
良心 119
救世主 111
生命 109
法律 107
点映 107
感人 103
水准 103
审查 100
票房 100
药厂 96
批判 94
进步 94
2018 93
谭卓 93
四、词云制作
1.打开WordArt.com,选择import,将上面的结果粘贴到对应的地方
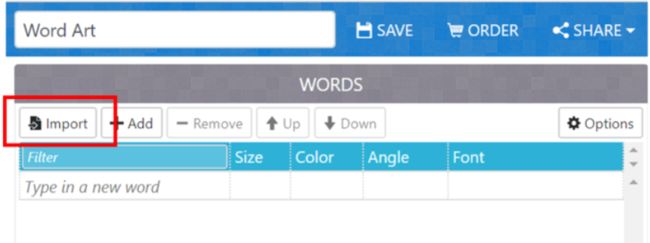
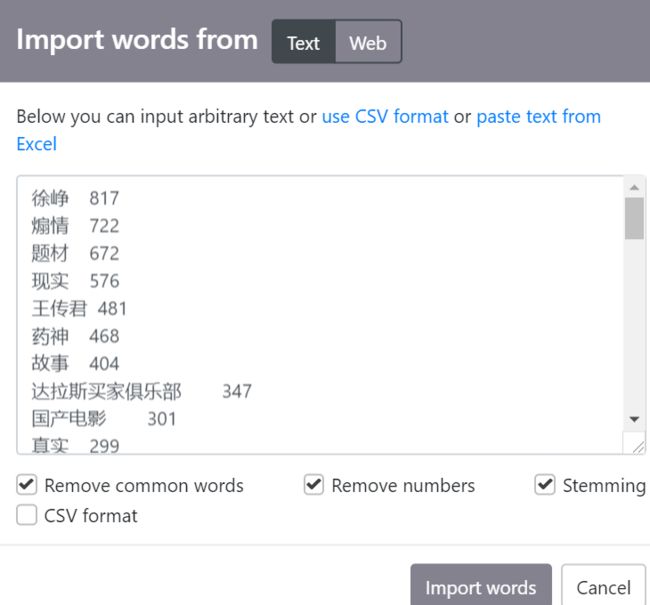
2.选择词云的形状,可以点击Add image自己添加:
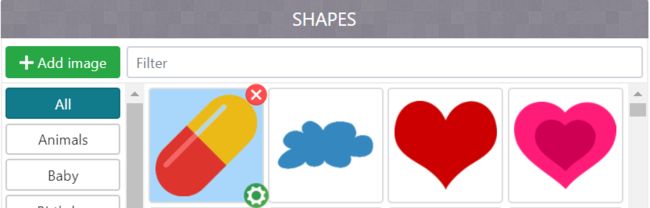
image.png
3.选择字体,这个工具是没有中文字体的,所以需要添加,在网上下载一种字体,点击Add font添加

4.点击VIsualize,完成词云制作,
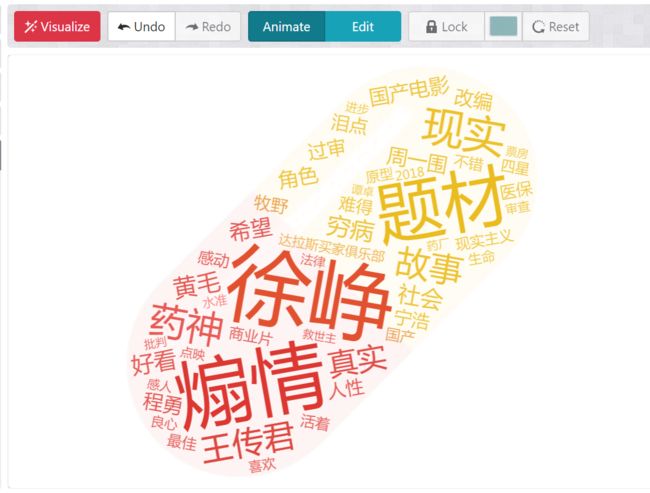
方法二:Python+jieba+WordCloud
一、安装wordcloud、scipy、matplotlib等库
eg:
pip install wordcloud
二、利用python第三方库+jieba进行词云制作
from os import path
from wordcloud import WordCloud, ImageColorGenerator
import jieba.analyse
import matplotlib.pyplot as plt
from scipy.misc import imread
class cloud:
def __init__(self, filename, image_filename, font_filename):
self.d = path.dirname(__name__)
jieba.load_userdict("userdict.txt") # 自定义词典
content = open(path.join(self.d, filename), 'r',encoding='UTF-8').read()
jieba.analyse.set_stop_words('stop.txt') # 停用词词典
tags = jieba.analyse.extract_tags(content, topK=50, withWeight=False)
self.text = " ".join(tags)
# 需要显示的背景图片
self.img = imread(path.join(self.d, image_filename))
self.wc = WordCloud(font_path=font_filename, background_color='white',
max_words=300, mask=self.img, max_font_size=40,
random_state=42)
self.wc.generate(self.text)
def show_wc(self):
#显示生成词云图
# 让词的颜色和图片的颜色一样
img_color = ImageColorGenerator(self.img)
plt.imshow(self.wc.recolor(color_func=img_color))
plt.axis("off")
plt.show()
def save_wc(self, out_filename):
self.wc.to_file(path.join(self.d, out_filename)) #保存到当前目录下
if __name__ == '__main__':
wc = cloud("review.txt", "m.png", "msyh.ttf")
wc.show_wc()
wc.save_wc('output.jpg')
词云制作结果:
