总结:
- 数据集:声学场景分类任务,使用DCASE2019_task_1b的数据集,共10000个训练集和5000个验证集,做好了数据的处理工作。
- 特征提取:特征提取采用python_speech_features库提取log-mel特征,帧长20ms,帧移10ms,频率维度80,对标签进行one-hot处理。
- 使用keras自带的ResNet50在不区分设备的情况下跑出61.63%的结果,但是训练过程中验证集正确率波动十分明显,因此个人认为意义不大。
- 阅读并复现了McDonnell的方法。
- 该参赛者使用librosa提取log-mel特征,帧长2048个采样点,帧移1024个采样点,频率维度128,并且对特征进行了一阶差分和二阶差分。
- 值得注意的是,其没有将设备进行区分训练,因此方法的鲁棒性会很好。
- 其将128维特征分成低频的64维和高频的64维,在网络中并行训练最后进行拼接。
- 数据增强采用Mixup。
- 网络模型使用残差卷积网络。
- 在训练过程中动态调整学习率。
- 64个epoch时达到了73%的正确率,相信在510个epoch时性能还会有提升。
- 发现的问题:由于我和McDonnell提取的特征稍有不同,但是性能差别明显。
- 我的特征+ResNet50:性能可达到60%
- McDonnell特征+ResNet50:15%左右
- 我的特征+作者的模型:62%
- McDonnell特征+作者的模型:73%。
该问题需要在下面的工作中进行分析。
下一步计划:
- Mixup是一个很好的数据增强方法,因为训练集和测试集语料仅有15000条,每条10秒,数据量并不大。我想在这一步中引入GAN来提取音频的纯净特征,可以在这一点上进行尝试。
- keras自带的ResNet50只是一个暂时的baseline,需要引用再调整出一个性能较好的模型
- 音频特征提取需要进行进一步的研究。个人认为音频特征的提取对分类结果的影响十分明显,但现在并没有弄懂什么样的特征才真正适合该任务,只是按照通用的方法来进行特征提取工作
2019.11.18
1.处理好了DCASE2019数据集,已将数据按a、b、c设备分类。
2.对音频提取特征。
音频都是10s的数据。特征采用80维的log-fbank,帧长20ms,帧移10ms,因此每个音频共999帧。
在提取过程中发现有的音频裁出了1000帧,为保证矩阵的维度,因此只保留前999帧,最终输入网络的数据维度是( , 999, 80, 1)
3.对标签进行one-hot处理。
4.使用keras自带的ResNet50训练a设备。
暂时最好情况达到54%正确率。

2019.11.19
-
昨日数据跑了100个epoch,最好效果达到66.70%

- 阅读论文《BOOSTING NOISE ROBUSTNESS OF ACOUSTIC MODEL VIA DEEP ADVERSARIAL TRAINING》
论文想要使用GAN提取纯净语音的特征,而在我的任务中,a设备由于数据量大、录音设备精度高,因此可以理解为纯净的语音,我们就可以用类似的方法提取b、c设备的纯净特征(相似于设备a)。文中提到了论文《Triple Generative Adversarial Nets》提出三重GAN,以引入用于分类和分类条件生成的三个组件。 - 改用DenseNet169跑100个epoch,最好到65.91%
- 阅读《深度学习500问》第七章GAN
这个目标函数可以分为两个部分来理解:
第一部分:判别器的优化通过 实现, 为判别器的目标函数,其第一项 表示对于从真实数据分布中采用的样本 ,其被判别器判定为真实样本概率的数学期望。对于真实数据分布 中采样的样本,其预测为正样本的概率当然是越接近1越好。因此希望最大化这一项。第二项 表示:对于从噪声 分布当中采样得到的样本,经过生成器生成之后得到的生成图片,然后送入判别器,其预测概率的负对数的期望,这个值自然是越大越好,这个值越大, 越接近0,也就代表判别器越好。
第二部分:生成器的优化通过 来实现。注意,生成器的目标不是 ,即生成器不是最小化判别器的目标函数,二是最小化判别器目标函数的最大值,判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度(详情可以参阅附录的推导),JS散度可以度量分布的相似性,两个分布越接近,JS散度越小。
2019.11.20
- 阅读《Investigating Generative Adversarial Networks based Speech Dereverberation for Robust Speech Recognition》
发现自己阅读论文能力不足,需要锻炼,阅读一遍之后,每句话能大概读懂是什么意思,但是回想一下论文都讲了哪些事情却什么也想不起来。 -
不区分设备,将所有数据一齐进行训练,网络使用还是ResNet50,最高达到61.63%。
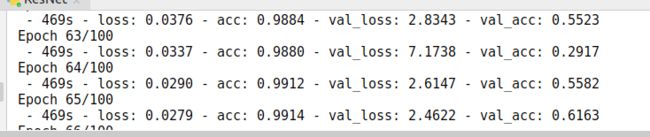
2019.11.21
阅读《Speech Enhancement Generative Adversarial Network》
引用其中的一句话:
对于传统的机器学习方法,我们一般会先定义一个模型让数据去学习。(比如:假设我们知道原始数据是高斯分布的,只是不知道高斯分布的参数,这个时候我们定义一个高斯分布,然后利用数据去学习高斯分布的参数,最终得到我们的模型),但是大家有没有觉得奇怪,感觉你好像事先知道数据该怎么映射一样,只是在学习模型的参数罢了。GAN则不同,生成模型最后通过噪声生成一个完整的真实数据(比如人脸),说明生成模型已经掌握了从随机噪声到人脸数据的分布规律。有了这个规律,想生成人脸还不容易,然而这个规律我们事先是不知道的,我们也不知道,如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。突然有一个想法
我试听了abc三种设备录制出来的音频,三种音频最明显的差别就是音量,a设备精度最高但音量最低,人耳很难辨别出场景,我认为是设备质量过好,滤掉了很多场景中的杂音,但这些可能是被忽略掉的有用信息,遂决定单独再跑一下b、c设备的数据。
- 用ResNet50跑b设备,正确率在40%左右。
- 用ResNet50跑c设备,正确率在43%左右。
问过师兄,师兄说不要太主观地去听,因为机器理解的和人理解的不同。
我应该再去看看DCASE上人们的做法。
- DCASE上其他人的情况
Kosmider是做的很出色的,提交的四个网络占据了前四名。他提出的思想是对音频提取完特征后进行频谱增强,并且大量使用模型融合,投票方式。但是没有公开代码。
McDonnell的做法是将3个子任务都实现了,而且使用单一模型。亮点是,作者认为高频和低频有不同的特征,因此使用网络学习一半儿高频的知识,再学习另一半的低频知识,拼接成128维的特征向量。
2019.11.22
读完了McDonnell的技术报告,并且他提供了源码,开始复现。
2019.11.23
在McDonnell的代码中发现,他将三个子任务进行了整合,代码可以将三个子任务同时实现。
① csv文件读取时直接用sep='\t'将制表符拆分,encoding='ASCII'以该格式读取,读取时直接用表头['filename'].tolist()获取到列表,这一段之前我在实现时用了很长一段代码才实现,作者只用了一行,非常值得学习。
② 用的librosa库进行特征提取,但是没有将提取好的特征进行保存,这一段可以修改一下。
③ 作者用到了Warm Restart,这一段要查一查
④ 需要再巩固一下特征提取的几个参数。
2019.11.24
敲完了作者的代码,但是其中有许多东西需要细致地理解。
2019.11.25
1.作者代码中有大量的特征维度操作处理,有必要再去温习下特征提取的维度意义。
- 改写特征提取那一部分。因为如果每次运行都提取,则会占用大量CPU资源。
- 调整好了程序,已经成功运行。
- 再来梳理一下作者提取特征的一些参数。
LM_train[i,:,:,channel]= librosa.feature.melspectrogram(stereo[:,channel],
sr=sr,
n_fft=NumFFTPoints,
hop_length=HopLength,
n_mels=NumFreqBins,
fmin=0.0,
fmax=sr/2,
htk=True,
norm=None)
- stereo:输入的数据
- sr:采样率。在这里是44100
- n_fft:窗口大小。在这里是2048
- hop_length:帧移。在这里是窗口的一半,即1024
- n_mels:产生的梅尔带数。这里是128
- fmin:最低频率。这里是0
- fmax:最高频率,默认是采样率的一半。
- htk:使用HTK公式代替Slaney
- norm:如果为1,则将三角mel权重除以mel带的宽度(区域归一化)。 否则,保留所有三角形的峰值为1.0
- 很多DCASE参赛者都使用了Mixup方法,因此有必要阅读这篇论文《Mixup: Beyond empirical risk minimization》
2019.11.26
- 机器学习-->期望风险、经验风险与结构风险之间的关系
出处:机器学习-->期望风险、经验风险与结构风险之间的关系
① 经验风险:
所谓的经验风险最小化便是让这个式子最小化,注意这个式子中累加和的上标N表示的是训练样例集中样本的数目。 经验风险是对训练集中的所有样本点损失函数的平均最小化,经验风险越小说明模型f(X)对训练集的拟合程度越好.
② 期望风险:我们知道未知的样本数据(
- 经验风险是局部的,基于训练集所有样本点损失函数最小化的。
- 期望风险是全局的,是基于所有样本点的损失函数最小化的。
- 经验风险函数是现实的,可求的;
- 期望风险函数是理想化的,不可求的;
③ 结构风险:结构风险是对经验风险和期望风险的折中,在经验风险函数后面加一个正则化项(惩罚项)便是结构风险。
相比于经验风险,结构风险多了一个惩罚项是一个大于0的系数。J(f)表示的是是模型f的复杂度。
经验风险越小,模型决策函数越复杂,其包含的参数越多,当经验风险函数小到一定程度就出现了过拟合现象。也可以理解为模型决策函数的复杂程度是过拟合的必要条件,那么我们要想防止过拟合现象的方式,就要破坏这个必要条件,即降低决策函数的复杂度。也即,让惩罚项J(f)最小化,现在出现两个需要最小化的函数了。我们需要同时保证经验风险函数和模型决策函数的复杂度都达到最小化,一个简单的办法把两个式子融合成一个式子得到结构风险函数然后对这个结构风险函数进行最小化。
- Mixup
出处:【论文阅读】mixup: BEYOND EMPIRICAL RISK MINIMIZATION
经验风险最小化(ERM)存在这样的一个问题:只要模型能够记住每个样本,就可以最小化经验风险。因此一旦出现和模型分布轻微不同的数据,表现就会很差。其实就是过拟合了。.
这篇文章的主要贡献在于提出了一种通用的临近分布,mixup:
其中,,对于任意的。简而言之,从mixup分布采样出数据集:
这里(xi,yi)和(xj,yj)是从数据集中随机采样得到的任意两个样本。α是一个超参数,用于控制混合的程度。当α越接近于0时,分布越倾向于集中在(0,1)的两端,越大时分布越均匀。极限情况α=0时等价于没有采用本方法。 - 阅读Paul Primus, David Eitelsebner的技术报告
① 特征提取:
降采样到22050Hz,窗长2048采样点,帧移512采样点。取40-22050HZ的信息,频率维度256,共431帧。
② 领域自适应:
A样本的分布称为源域,将B和C样本的分布称为目标域
③ LOSS:
使用MI Loss,即分类的Categorical Cross Entropy (CCE)loss和领域自适应的loss进行结合:
④ Model:
Kaggle上排名靠前的先进CNN架构。
参考《The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification》
⑤ Training:
epoch:250
mini_batch:32
优化算法:Adam
学习率:初始为,如果B、C设备15个epoch也不增长,则学习率以0.5的系数减少。
如果学习率降低,将设备B和C的平均准确度重置为最佳模型,直到最后一个epoch。 进一步使用MixUp增强,将beta分布的参数设置为α=β= 0.2。
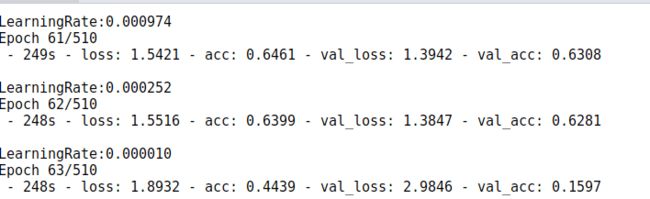
-
McDonnell的结果:


阅读《The Receptive Field as a Regularizer in Deep Convolutional Neural Networks for Acoustic Scene Classification》
改论文讲述了对CNN中感受野的调整对ASC任务的结果影响。将3 * 3调整到1 * 1。
2019.11.27
-
McDonnell的结果出来了,验证集最高能到69.88%
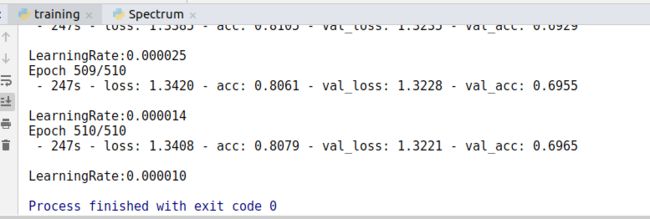
- 上面的效果其实并不是很理想,原以为可以做到70%以上。接下来想验证一下mixup的作用。
- 使用McDonnell提取的特征放入ResNet50中,发现十分类正确率只有20%左右,做进一步分析。
-
发现,我用之前的特征,验证集的准确率还是有保证的。
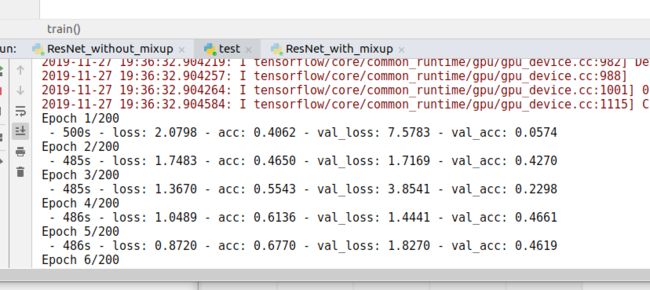
自己提取的特征与McDonnell的不同点:
① 我用的python_speech_features库;M使用的是librosa库
② 我用20ms作为窗长(882个点),10ms作为帧移;M用2048个点作为窗长,1024个点作为帧移。
2019.11.28
-
对比了一下是否添加mixup的结果:
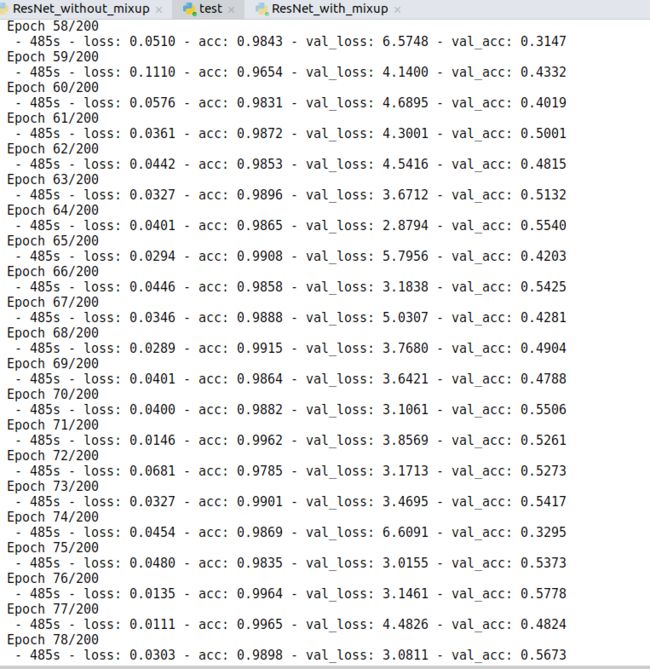 不添加Mixup
不添加Mixup
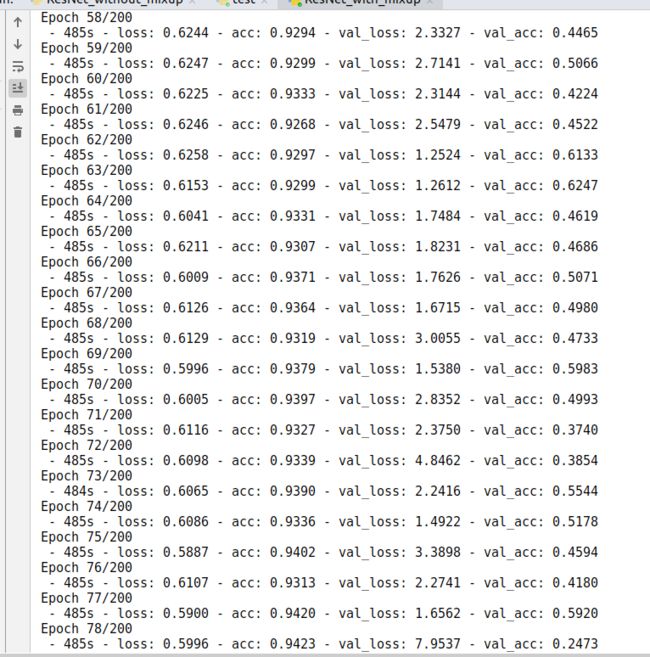 添加Mixup
添加Mixup -
在使用自己的特征跑McDonnell的程序时,发现模型模块写错了,修改。
McDonnell的特征在62epoch达到了73.28%的正确率。
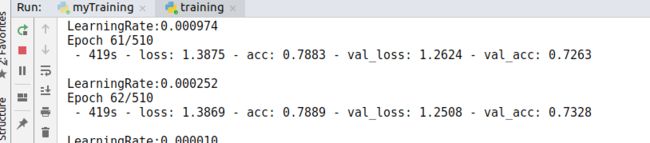 McDonnell
McDonnell
自己的特征在62epoch只达到了62%的正确率。
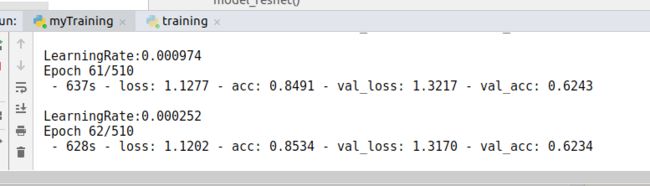 自己的
自己的