环境
CentOS-7-x86_64-Minimal-1708
原理

ELK 简介与安装
可以参考我之前的博客:集中式日志系统 ELK 协议栈__简介与安装
安装 filebeat
除了ELK 系统之外,我们需要 filebeat 来读取文件中的内容并发送给 ELK 系统。
(filebeat 实际上和 ELK 是同一家公司的,属于 Beats 类。)
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.1.1-x86_64.rpm
sudo rpm -vi filebeat-6.1.1-x86_64.rpm
rm filebeat-6.1.1-x86_64.rpm -f
构造数据源
为了进行日志分析的演示,需要动态地去构造访问数据,可以使用我写的一个简单的 Python 脚本,保存文件名为insert_fake_nginx_log.py。
Python 脚本中默认 Nginx 的日志路径为/var/log/nginx/access.log,如果你的日志文件不在这个路径,可根据实际情况修改。
# insert_fake_nginx_log.py
import datetime
import random
import time
def append_log_line_to_nginx(line_count):
curr_time = datetime.datetime.now().strftime('%d/%b/%Y:%H:%M:%S')
ip_list = [
'116.199.2.208', '116.199.2.196', '116.199.115.79', '101.53.101.172',
'47.94.23.128', '222.73.68.144', '120.27.49.85', '182.107.12.28',
'122.228.179.178', '182.129.240.254', '180.118.128.196', '106.75.25.3',
'113.140.25.4', '121.40.81.129', '121.31.139.10', '182.129.240.254',
'122.228.179.178', '117.90.2.225', '121.40.127.145', '120.76.77.152',
'59.51.121.191', '119.5.0.7', '123.177.20.80', '121.31.101.225',
'106.75.56.87', '223.241.78.253', '210.77.22.203', '58.56.149.198',
'125.67.75.53', '223.241.116.7', '121.232.144.131', '111.155.116.226',
'183.140.83.39', '111.40.84.73', '111.40.84.73', '120.8.232.135',
]
request_list = [
'GET /tasks/',
'POST /tasks/'
'PUT /tasks/26925b7335f0869824469f27b4e3167a/',
'GET /tasks/26925b7335f0869824469f27b4e3167a/',
'GET /tasks/26925b7335f0869824469f27b4e3167b/upload/',
'GET /tasks/26925b7335f0869824469f27b4e3167b/download/',
]
agent_list = [
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; WOW64; '
'Trident/7.0; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063',
'PostmanRuntime/6.4.1',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
]
response_list = [
'200', '401', '403', '404', '500',
]
with open('/var/log/nginx/access.log', 'a') as f:
for _ in range(line_count):
f.write('%s - - [%s +0800] "%s HTTP/1.1" %s 25 "-" "%s" "-"\n' % (
random.choice(ip_list),
curr_time,
random.choice(request_list),
random.choice(response_list),
random.choice(agent_list))
)
if __name__ == '__main__':
print('running...')
while True:
append_log_line_to_nginx(random.randint(1, 100))
time.sleep(random.randint(1, 5))
配置 filebeat
新建配置文件
vi /etc/filebeat/nginx_log_reader.yml
配置文件内容及说明如下
filebeat.prospectors:
- type: log
paths:
- /var/log/nginx/access.log # nginx 访问日志路径
fields: # 添加额外字段
log_type: nginx # 额外字段,一个键值对
fields_under_root: true # 该值默认为 false,即将上面添加的额外字段放在根键"field"下,此处将该值设置为 true,则表示将额外字段直接放在根键中
output.logstash: # 输出到 Logstash 中
hosts: ["localhost:5044"] # Logstash 的 IP 和 Port
启动之前写的 Python 脚本,不断地往 Nginx 日志文件中写入 log
python insert_fake_nginx_log.py
开启 filebeat
cd /usr/share/filebeat/
filebeat -e -c nginx_log_reader.yml -d "publish"
此时 filebeat 将会去尝试连接 Logstash 的端口5044,但我们没有启用 Logstash 的 Beats 插件,所以会显示以下错误信息
2018/01/27 09:19:01.645646 output.go:74: ERR Failed to connect: dial tcp 127.0.0.1:5044: getsockopt: connection refused
配置 Logstash
进入 Logstash 目录
cd /usr/share/logstash
创建配置文件
vi nginx_log.yml
配置文件如下,后面会对配置文件进行详细说明
input {
beats {
port => "5044"
}
}
filter{
if [log_type] == "nginx" {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}"}
remove_field => ["message", "beat"]
}
geoip {
source => "clientip"
}
date {
locale => "en-US"
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
remove_field => ["timestamp"]
}
}
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-nginx_log"
}
}
Logstash 配置文件说明
Logstash 配置文件基本结构
Logstash 分为三个部分,input、filter、output,每一个部分都提供了很多插件,三者之间关系如下,filter可根据需求跳过:
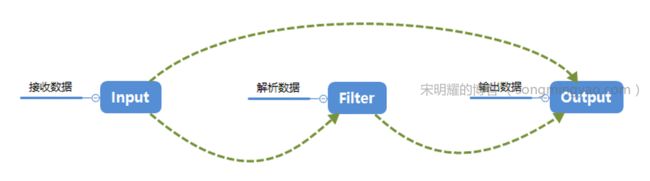
配置文件也分为三个部分,其中filter部分可以省略
input {
...
}
filter{
...
}
output {
...
}
配置文件语法
配置文件中,我们可以在filter和output中使用一些语法。
使用变量
表示顶级字段时,可以这样使用
[fieldname]
表示嵌套字段时,可以这样使用
[top-level field][nested field]
使用条件语句
可以使用if/else if/else 条件语句,也可以嵌套
if EXPRESSION {
...
}
else if EXPRESSION {
...
}
else {
...
}
在条件语句中可以使用的逻辑操作符:
-
==,!=,<,>,<=,>= -
=~,!~ -
in,not in -
and,or,nand(与非,都为真则False,其它情况都是True),xor(异或,相同为False,不同为True) !-
()分组
使用系统环境变量
使用环境变量
`${var}`
当环境变量未定义时使用默认值
${var:default_value}
如果在 logstash 启动后,系统的环境变量更新了,则需要去重启 logstash 才能使用到新的环境变量
input
官方输入插件文档导航见:官方文档 - Logstash 输入插件
此处我们使用的插件是beats,一般只需要设置port项以指定传输的端口号即可
input {
beats {
port => "5044"
}
}
filter{
...
}
output {
...
}
filter
官方解析插件文档导航见:官方文档 - Logstash 解析插件
此处我们使用了三个解析插件: grok、geoip和date。
input {
...
}
filter{
if [log_type] == "nginx" {
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}"}
remove_field => ["message", "beat"]
}
geoip {
source => "clientip"
}
date {
locale => "en-US"
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
remove_field => ["timestamp"]
}
}
}
output {
...
}
解析插件之 Grok
grok {
match => { "message" => "%{HTTPD_COMBINEDLOG}"}
remove_field => ["message", "beat"]
}
Nginx 的日志结构是这样的
180.118.128.196 - - [18/Jan/2018:01:20:31 +0800] "PUT /workers/ HTTP/1.1" 401 25 "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E)" "-"
可以看到,这是一堆字符串,而我们需要输出到 Elasticsearch 中的数据结构是 JSON,而 Grok 解析插件就可以将这一堆字符串解析为 JSON 格式。
Grok 解析的原理是将字符串中的字符通过解析模式(本质为正则表达式)提取出来,然后再赋值给一个个变量,从而构造成 JSON。
Github - Grok 内置的120种解析模式
Grok 中解析模式的语法是%{SYNTAX:SEMANTIC}。
-
SYNTAX是与文本匹配的模式名称,比如180.118.128.196将会被匹配为IP。 -
SEMANTIC是需要给这段文本匹配的标识符,即变量名。
除此之外,还可以在后面加上你想指定的数据类型,比如%{NUMBER:num:int},目前只支持指定数据格式为int或float,如不设置则将默认匹配为str。
Nginx 的日志格式可以直接使用官方提供的解析模式HTTPD_COMBINEDLOG
180.118.128.196 - - [18/Jan/2018:01:20:31 +0800] "PUT /workers/ HTTP/1.1" 401 25 "-" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E)" "-"
HTTPD_COMMONLOG %{IPORHOST:clientip} %{HTTPDUSER:ident} %{HTTPDUSER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
HTTPD_COMBINEDLOG %{HTTPD_COMMONLOG} %{QS:referrer} %{QS:agent}
解析插件之 GeoIP
geoip {
source => "clientip"
}
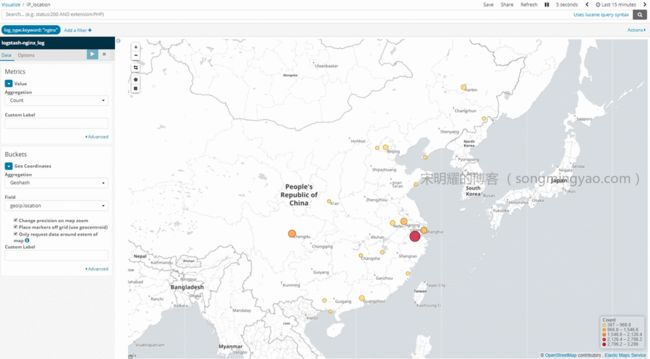
GeoIP 解析插件可以将 IP 地址解析为地理位置,基于 Maxmind GeoLite2 数据库。
下图为经过 GeoIP 解析过的 IP 地址在 Kibana (后面会详细说明)中的展现
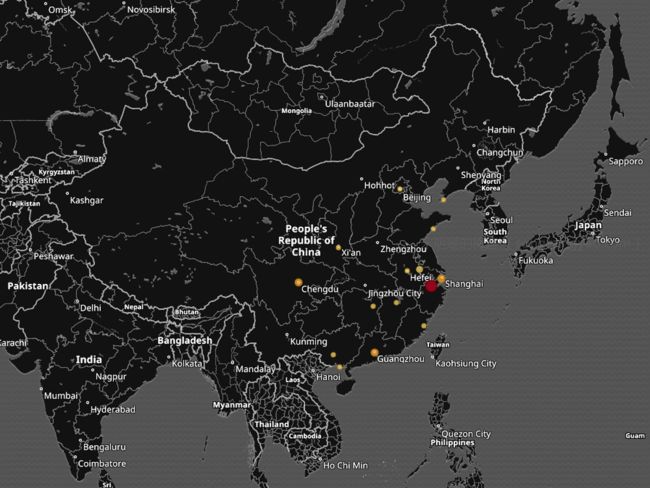
解析插件之 Date
date {
locale => "en-US"
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
remove_field => ["timestamp"]
}
locale
字符串类型,区域设置,一般设定为en-US
match
列表类型,要去解析为日期的字段名称及格式。格式有以下几种
-
ISO8601可以解析类似2018-01-29T09:48:01.101Z的格式 -
UNIX可以解析整型和浮点型(带毫秒)的 UNIX 时间,如1326149001/1326149001.132 -
UNIX_MS可以解析整型的毫秒级别的 UNIX 时间,如1366125117000 -
TAI64N可以解析tai64n类型的时间,格式为@4000000052f88ea32489532c,不常见。
除此之外,还可以直接使用 Joda 时间库类处理,格式定义如下:
年
yyyy,四位数的年,如2018
yy,两位数的年,如18月
M,最小位数的月份,如1,12
MM,两位数的月份,如01,12
MMM,缩写的月份单词,如Jan,Dec
MMMM,完整的月份单词,如January,December天
d,最小位数的天,如1,31
dd,两位数的天,如01,31小时
H,最小位数的小时,如0,24
HH,两位数的小时,如00,24分钟
m,最小位数的分钟,如0,59
mm,两位数的分钟,如00,59秒
s,最小位数的秒,如0,59
ss,最大位数的秒,如00,59毫秒
S,十分之一秒,如毫秒为012的话,表现为0
SS,百分之一秒,如毫秒为012的话,表现为01
SSS,千分之一秒,如毫秒为012的话,表现为012一年中的第几周
w,最小位数的周,如1,52
ww,两位数的周,如01,52一年中的第几天
D,最小位数的天,如1,365一周中的第几天
e,最小位数的天,以数字表示,如1,7
E/EE/EEE,缩写的周单词,如Mon,Sun
EEEE,完整的周单词,如Monday,Sunday
target
字符串类型,如要去解析的字段名,缺省值为@target
timezone
字符串类型,时区,如Asia/Shanghai
tag_on_failure
列表类型,指定如果解析失败的话,添加到tag字段的值,默认为["_dateparsefailure"]。
一般不做修改。
output
官方输出插件文档导航见:官方文档 - Logstash 输出插件
此处我们使用了两个输出插件,stout和elasticsearch
input {
...
}
filter{
...
}
output {
stdout { codec => rubydebug }
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-nginx_log"
}
}
stdout { codec => rubydebug }可以将所有的输出信息打印到终端。
elasticsearch就是把信息输出到 Elasticsearch 中,一般只需要设置两项,hosts和index。
-
hosts指定了 Elasticsearch 的 IP 和端口号,为列表形式,有多个则可以指定多个; -
index指定了数据输出到 Elasticsearch 后,赋予给 Elasticsearch 的索引值,用以对不同文档进行拆分。建议以logstash-为前缀,否则需要手动地去设定 Elasticsearch 模板。
启动 Logstash
cd /usr/share/logstash
bin/logstash -f nginx_log.yml --config.reload.automatic
--config.reload.automatic的意思是,当配置文档发生修改时,自动重启。
当你启动时,会报以下错误
[ERROR] 2018-01-29 10:29:39.982 [[main]-pipeline-manager] elasticsearch - Failed to install template. {:message=>"Template file '' could not be found!", :class=>"ArgumentError", :backtrace=>["/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-output-elasticsearch-9.0.2-java/lib/logstash/outputs/elasticsearch/template_manager.rb:31:in `read_template_file'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-output-elasticsearch-9.0.2-java/lib/logstash/outputs/elasticsearch/template_manager.rb:17:in `get_template'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-output-elasticsearch-9.0.2-java/lib/logstash/outputs/elasticsearch/template_manager.rb:7:in `install_template'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-output-elasticsearch-9.0.2-java/lib/logstash/outputs/elasticsearch/common.rb:57:in `install_template'", "/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-output-elasticsearch-9.0.2-java/lib/logstash/outputs/elasticsearch/common.rb:26:in `register'", "/usr/share/logstash/logstash-core/lib/logstash/output_delegator_strategies/shared.rb:9:in `register'", "/usr/share/logstash/logstash-core/lib/logstash/output_delegator.rb:43:in `register'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:343:in `register_plugin'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:354:in `block in register_plugins'", "org/jruby/RubyArray.java:1734:in `each'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:354:in `register_plugins'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:743:in `maybe_setup_out_plugins'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:364:in `start_workers'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:288:in `run'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline.rb:248:in `block in start'"]}
这是因为 Elasticsearch 未启动,无法找到对应的模板,等会将 Elasticsearch 启动就好了。
配置 Elasticsearch
按照安装步骤切换到非root账户后,直接启动
cd /usr/share/elasticsearch
bin/elasticsearch
配置 Kibana
按照安装步骤修改host为0.0.0.0后,直接启动
cd /usr/share/kibana
bin/kibana
在 Kibana 中创建索引
-
打开浏览器,在地址栏输入
yourdomain:5601(记得将yourdomain修改为安装了 Kibana 机器的 IP)
 Alt text
Alt text -
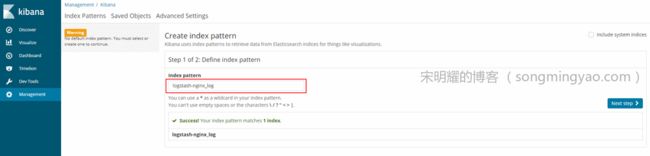
进入
Management-Index Patterns
 Alt text
Alt text -
在创建页面的
Index Patterns输入框内输入logstash-nginx_log,即我们之前在 Logstash中创建的索引
 Alt text
Alt text -
点击下一步之后,在
Time Filter field name下拉框内选择@timestamp作为时间轴的参数
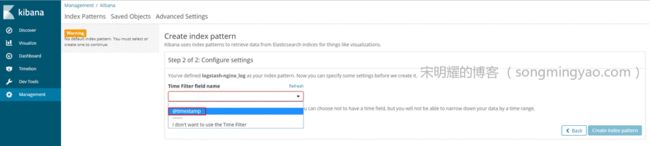 Alt text
Alt text -
成功创建索引
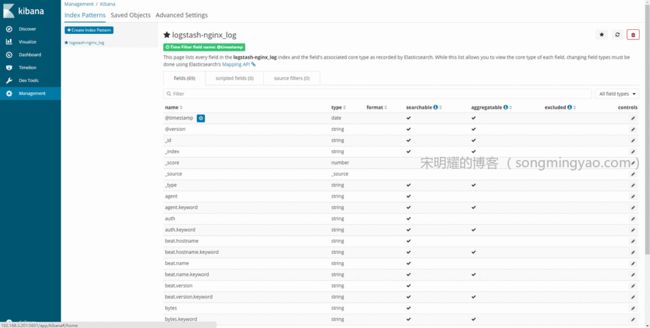 Alt text
Alt text
查看 Discover 页面
-
切换到
Discover页面,可以看到 nginx 的access.log中的日志已经被解析为一个个键值对了。
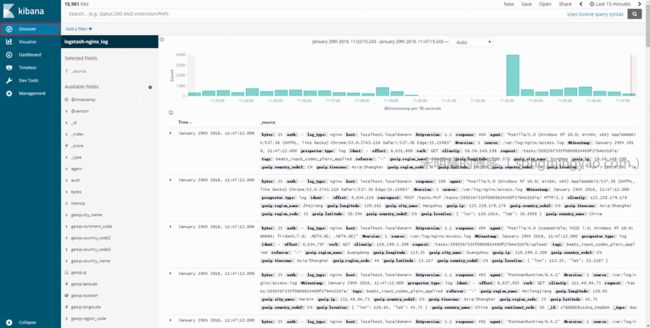 Alt text
Alt text -
展开一个文档,可以看到键值对的明细
 Alt text
Alt text
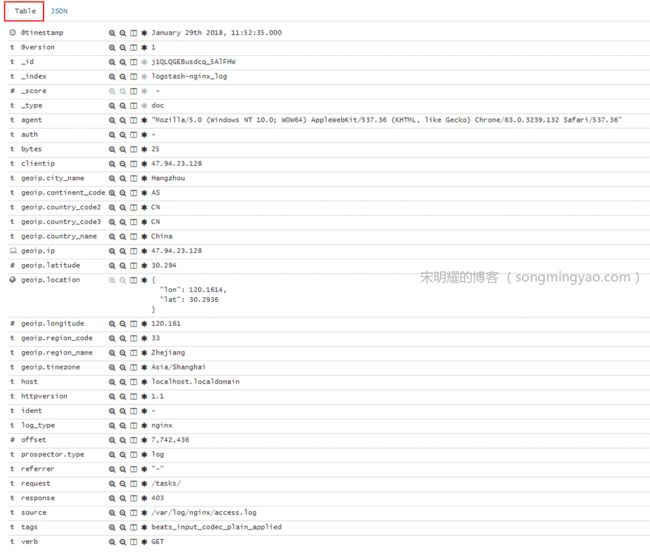 Alt text
Alt text
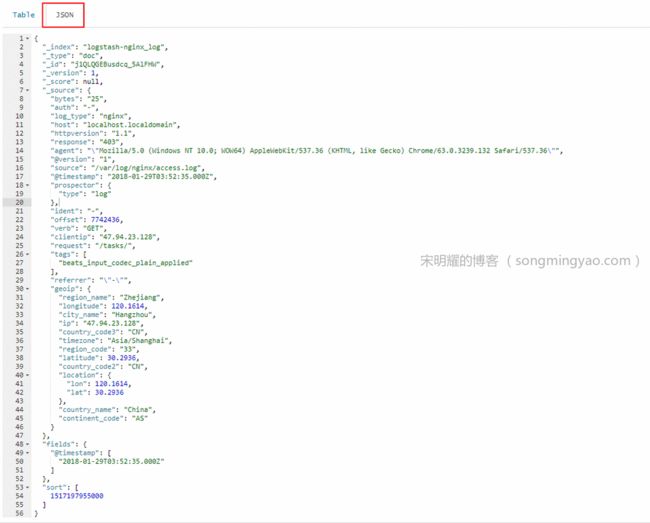 Alt text
Alt text -
在右上角可以选择要显示的时间段,有相对时间段和绝对时间段,也可以在
Quick中快速选择
 Alt text
Alt text -
可以设置页面自动刷新,设定每隔一段时间就自动去获取最新的数据
 Alt text
Alt text -
在左上角可以设置筛选字段来对当前数据进行选择,比如只想要响应为200的数据
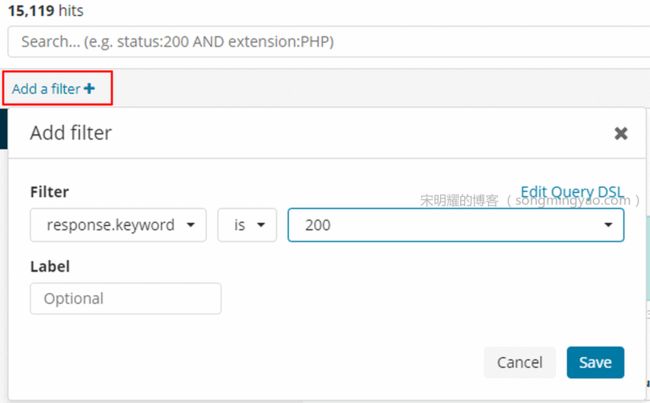 Alt text
Alt text
制作更直观的视图
-
切换到
Visualize,点击Create a visualization,可以看到有很多种表格形式供选择。
 Alt text
Alt text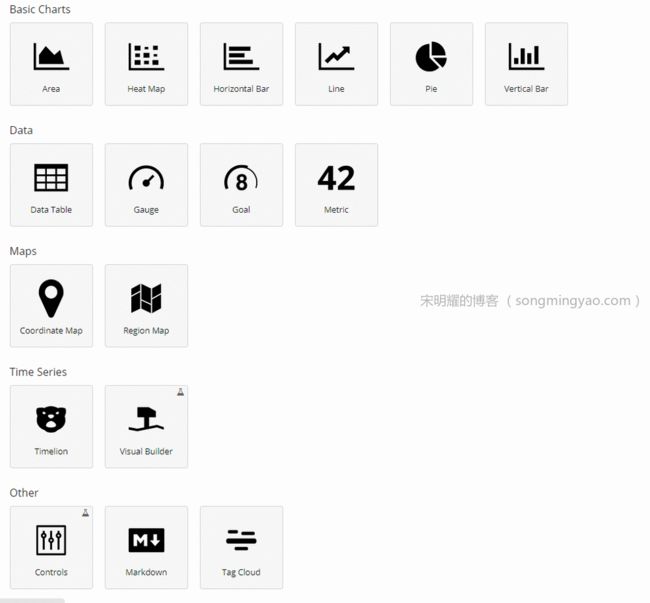 Alt text
Alt text -
首先制作历史访问量视图,选择
Area
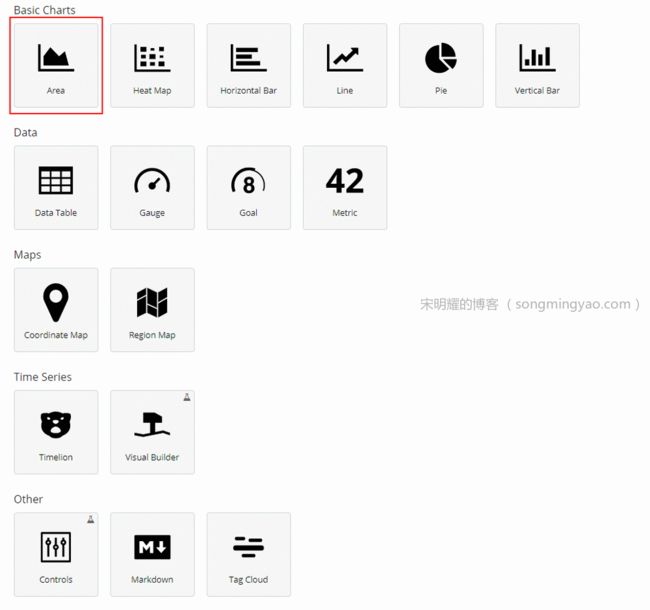 Alt text
Alt text -
选择数据来源的索引,即我们之前创建好的
logstash-nginx_log
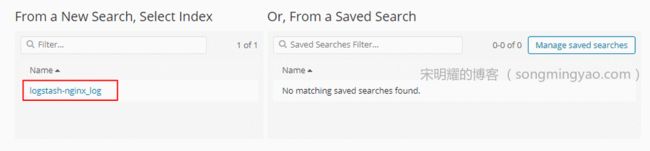 Alt text
Alt text -
首先对数据来源的
log_type进行筛选,虽然我们现在只有一个log_type,即nginx
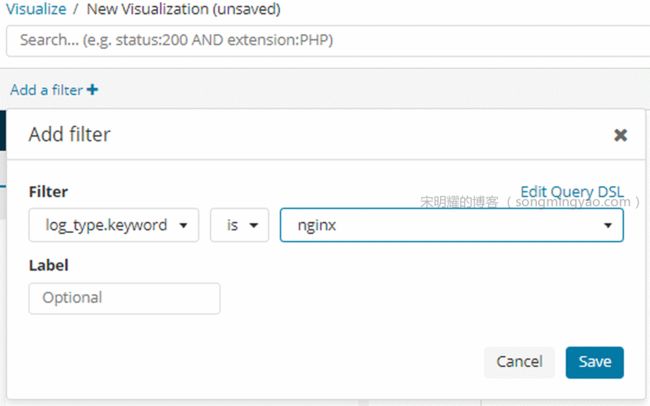 Alt text
Alt text -
选择 Y 轴要展示的数据,此处我们要统计访问量,就选择默认的
Count,并重命名为PV,然后点击上方的箭头使之生效
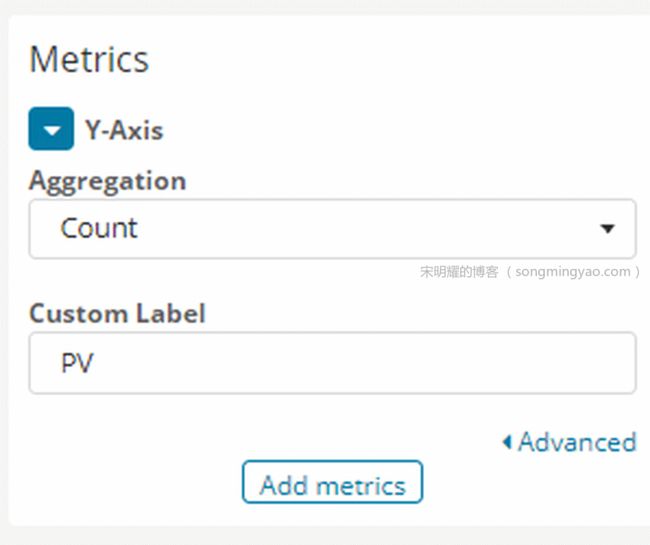 Alt text
Alt text -
然后选择 X 轴要展示的数据,此处我们需要访问历史数据,则需要选择时间来作为参数
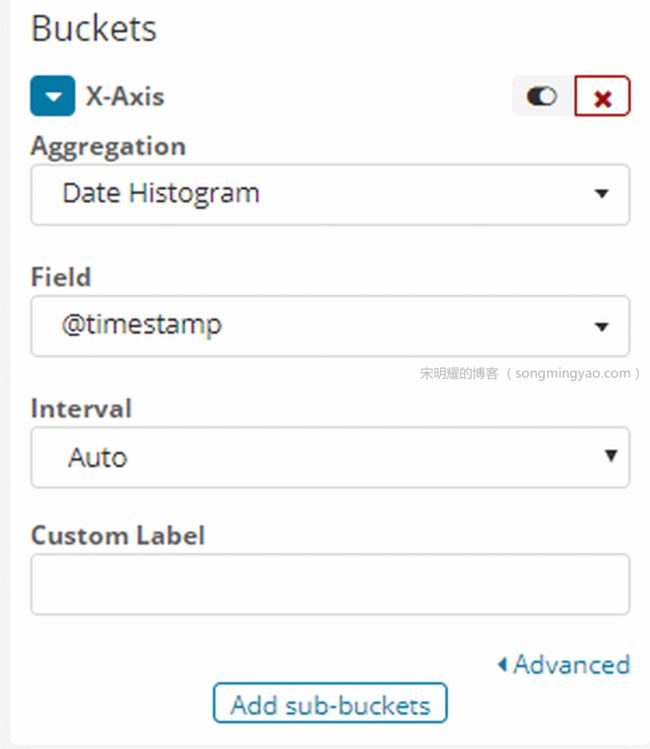 Alt text
Alt text -
点击上方的蓝色箭头,就可以在右侧看到历史访问量的视图了
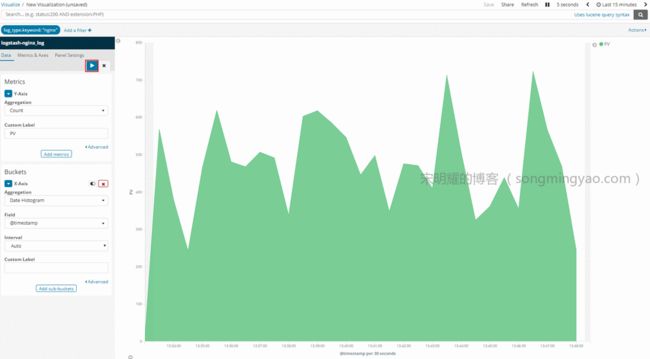 Alt text
Alt text -
点击右上角的
Save,即可将视图保存下来,以备后面放入Dashborad中
 Alt text
Alt text 其它视图操作类似,不作赘述,仅贴出具体配置截图
-
PV Total(Metric)
 Alt text
Alt text -
UV History(Line)
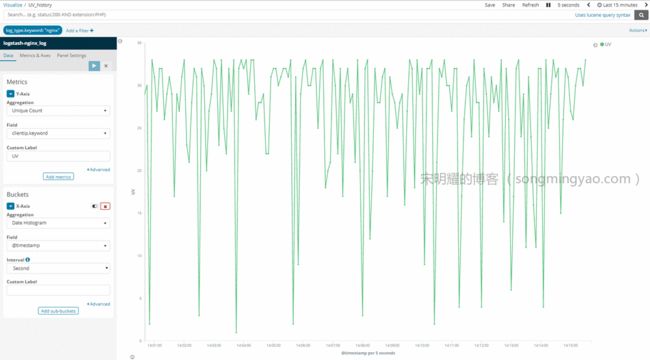 Alt text
Alt text -
UV Total(Metric)
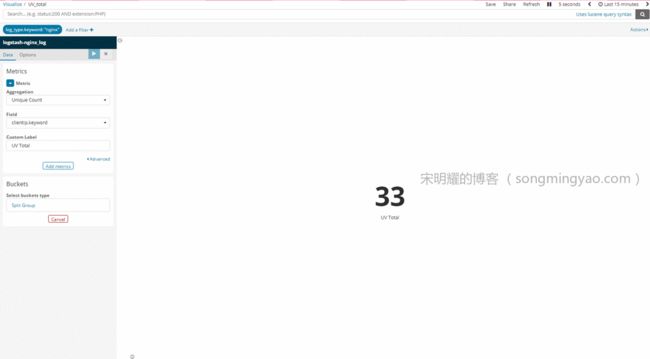 Alt text
Alt text -
IP Location(Coordinate Map)
 Alt text
Alt text -
Agent Pie(Pie)
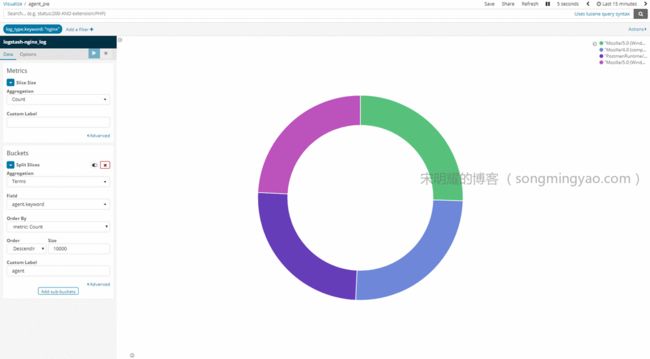 Alt text
Alt text -
Response Count(Horizontal Bar)
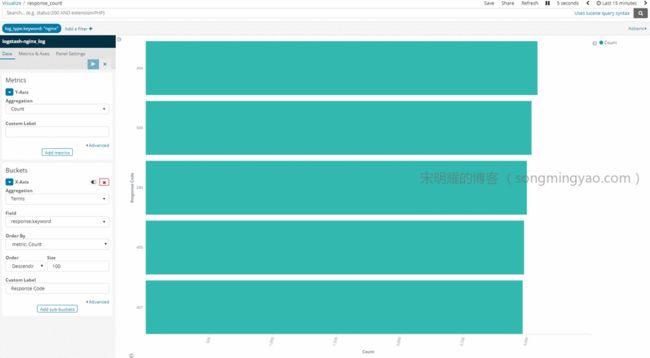 Alt text
Alt text
制作仪表板
-
切换到
Dashboard,点击Create a dashboard,点击Add以添加视图
 Alt text
Alt text Alt text
Alt text -
将我们刚才创建的视图全部添加进仪表板
 Alt text
Alt text -
将它们的大小和位置进行调整
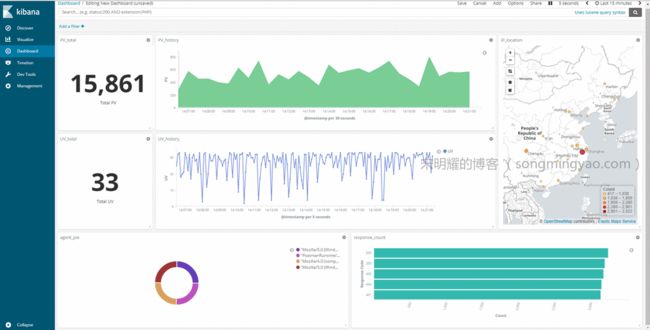 Alt text
Alt text -
在右上角选择要显示的时间范围
 Alt text
Alt text -
选择自动刷新的时间间隔
 Alt text
Alt text -
可以在选项中选择隐藏视图标题,以让仪表板更一体化
 Alt text
Alt text -
保存时,勾选
Store time with dashboard以保存刚才的时间设置
 Alt text
Alt text -
点击右上角的
Full screen,可以让仪表板全屏,可以再按下F11,使浏览器全屏,最终效果如下图
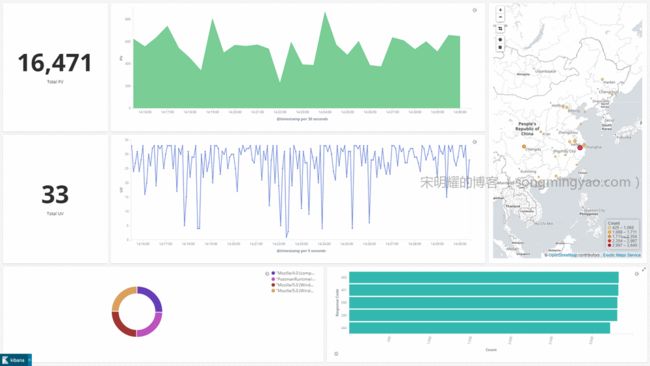 Alt text
Alt text
扩展
- Elasticsearch 官方文档
- Logstash 官方文档
- Kibana 官方文档
- Beats 官方文档
博客更新地址
- 宋明耀的博客 [ 第一时间更新 ]
- 知乎专栏 Python Cookbook
- 知乎专栏 DevOps - BetterWorld
- 流月0的文章