网上关于Mac原生系统CDH5搭建的千篇一律,对于Hadoop/Linux小白的我来说,终于在各种百度后,搭建CDH5成功。为了让其他想要自学Hadoop又在网上四处碰壁的兄弟们少走弯路。我把我的搭建步骤和经验教训分享给大家。祝大家可以早入Hadoop的坑。
先上效果图:

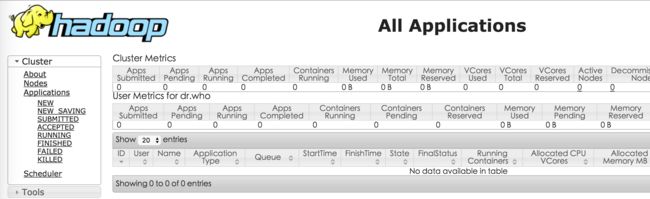
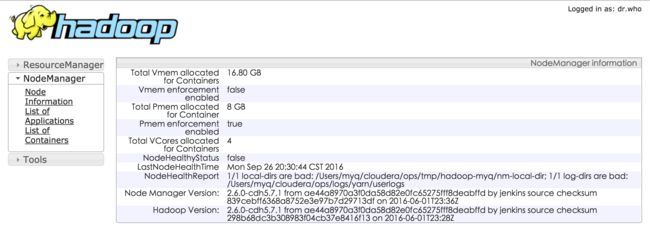
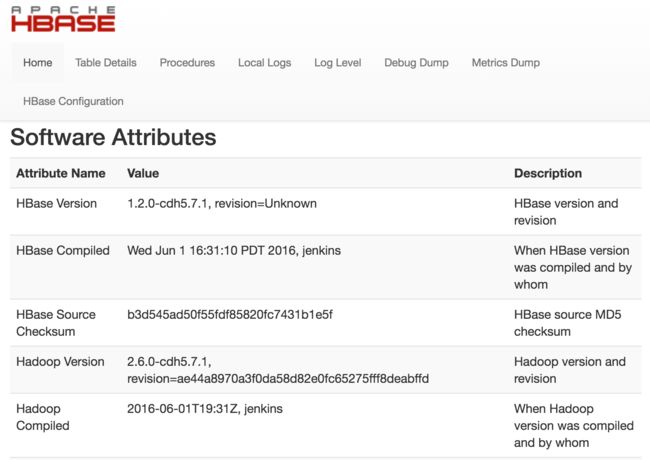
下面开始正式的教程:
参考来源 How-to: Install CDH on Mac OSX 10.9 Mavericks
全是一步一步来的,所有截图都是自己截的,而且会提到很多初学者容易犯的问题,尽可能提到每一个细节。O(∩_∩)O
1.安装JDK
JDK 1.8 下载地址
2.本地ssh登录
打开 系统偏好设置-->共享 ,选中远程登录。

打开终端,执行:(此步骤为生成、管理和转换认证密钥)
ssh-keygen -t rsa -P ""
然后执行,会要求输入本机密码。
ssh localhost
输入密码后,如果显示最后一次登录时间,则登录成功。
3.下载 CDH Hadoop 压缩包
我这里提供的是cdh5.7.1版本,就是我亲测版本。如果想下载其他版本可以到CDH5下载地址下载。
hadoop-2.6.0-cdh5.7.1.tar.gz
hbase-1.2.0-cdh5.7.1.tar.gz
hive-1.1.0-cdh5.7.1.tar.gz
zookeeper-3.4.5-cdh5.7.1.tar.gz
4.搭建CDH环境
打开终端,执行下面指令,及在User/你的用户名/ 下建立目录结构。想看发生了什么,请在执行命令前移至你用户名文件夹下,看变化。
mkdir -p ~/cloudera/lib ~/cloudera/cdh5.7 ~/cloudera/ops/dn ~/cloudera/ops/logs/hadoop ~/cloudera/ops/logs/hbase ~/cloudera/ops/logs/yarn ~/cloudera/nn ~/cloudera/pids ~/cloudera/tmp ~/cloudera/zk
步骤3下载的文件拷贝到User/你的用户名/cloudera/lib目录下,然后执行下面指令(下面指令为解压步骤3下载的压缩文件):
tar -xvf hadoop-2.6.0-cdh5.7.1.tar.gz
tar -xvf hbase-1.2.0-cdh5.7.1.tar.gz
tar -xvf hive-1.1.0-cdh5.7.1.tar.gz
tar -xvf zookeeper-3.4.5-cdh5.7.1.tar.gz
可以看到lib目录下出现四个解压后的文件。然后在命令行输入(到cdh5.7文件夹):
cd ~/cloudera/cdh5.7
然后执行以下命令(本命令为在cdh5.7文件夹下创建lib中刚才解压的四个文件夹的快捷方式):
ln -s ~/cloudera/lib/hadoop-2.6.0-cdh5.7.1 hadoop
ln -s ~/cloudera/lib/hbase-1.2.0-cdh5.7.1 hbase
ln -s ~/cloudera/lib/hive-1.1.0-cdh5.7.1 hive
ln -s ~/cloudera/lib/zookeeper-3.4.5-cdh5.7.1 zookeeper
现在来确认一下现在cloudera文件夹下目录结构如下(此时下载的放在lib中的压缩文件可以删除):
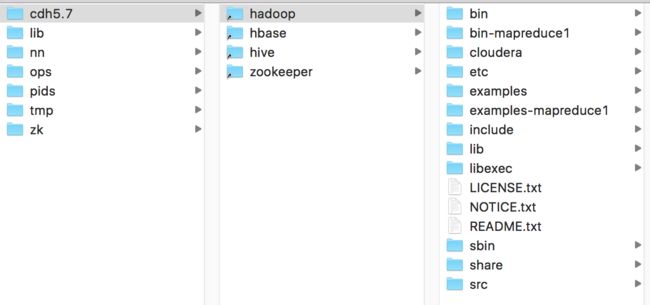
5.编辑配置文件profile
执行下面指令:
vi ~/.bash_profile
然后进行编辑,添加下面指令在配置文件中添加PATH:
CDH="cdh5.7"
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.x_xx.jdk/Contents/Home"(这里jdk1.8.x_xx.jdk处改为你电脑的java版本,查看java版本可以用指令java -version来查看)
export HADOOP_HOME="/Users/你的用户名/cloudera/${CDH}/hadoop"
export HBASE_HOME="/Users/你的用户名/cloudera/${CDH}/hbase"
export HIVE_HOME="/Users/你的用户名/cloudera/${CDH}/hive"
export HCAT_HOME="/Users/你的用户名/cloudera/${CDH}/hive/hcatalog"
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZK_HOME}/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:${HCAT_HOME}/bin:${PATH}
然后最容易有问题的一步来了。我在这儿耗了很长时间。/(ㄒoㄒ)/~~
分别依次执行(!!!先看下面备注)
vi $HADOOP_HOME/etc/hadoop/core-site.xml
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
vi $HBASE_HOME/conf/hbase-site.xml
vi $HBASE_HOME/conf/hbase-env.sh
备注: 每执行上面的一句 把里面的内容替换为github上对应文件的内容,也可以不用vi指令修改,可以自己根据文件路径找到对应文件进行内容编辑,链接如下:(☆☆注意一定要把文件中所有的jordanh替换为你的用户名!!!!!因为jordanh是原作者的用户名)
$HADOOP_HOME/etc/hadoop/core-site.xml
$HADOOP_HOME/etc/hadoop/hdfs-site.xml
$HADOOP_HOME/etc/hadoop/yarn-site.xml
$HADOOP_HOME/etc/hadoop/mapred-site.xml
$HADOOP_HOME/etc/hadoop/hadoop-env.sh
$HBASE_HOME/conf/hbase-site.xml
$HBASE_HOME/conf/hbase-env.sh
6.运行
只要上面的步骤都没有问题,那么你已经基本成功了。
终端中执行命令:
hdfs namenode -format
然后执行下面命令:
vi $HADOOP_HOME/libexec/hadoop-config.sh
编辑这个文件找到# Attempt to set JAVA_HOME if it is not set这一行,把下面的几句话改成:

启动服务
start-dfs.sh
start-yarn.sh
start-hbase.sh
mr-jobhistory-daemon.sh start historyserver
启动后,没有报错,则启动成功。
可打开下面服务管理地址进行测试:
HDFS:http://localhost:50070/dfshealth.html
Yarn Scheduler:http://localhost:8088/cluster
Yarn NodeManager:http://localhost:8042/node
HBase:http://localhost:60010/master.jsp
想要停止服务则输入一下指令:
stop-all.sh
sh $HADOOP_HOME/sbin/stop-dfs.sh
sh $HADOOP_HOME/sbin/stop-yarn.sh
sh $HBASE_HOME/bin/stop-hbase.sh
到这里就结束了,有问题可以留言问我~祝大家一遍成功!