前言
系统环境:CentOS7
本文假设你已经安装了virtualenv,并且已经激活虚拟环境ENV1,如果没有,请参考这里:使用virtualenv创建python沙盒(虚拟)环境
目标
使用scrapy的命令行工具创建项目以及spider,使用Pycharm编码并在虚拟环境中运行spider抓取http://quotes.toscrape.com/中的article和author信息, 将抓取的信息存入txt文件。
正文
1.使用命令行工具创建项目并指定项目路径,具体用法为
scrapy startproject [project_dir]
项目名称
[project_dir]项目路径,缺省时默认为当前路径
本文中quotes为项目名称,PycharmProjects/quotes为项目路径
(ENV1) [eason@localhost ~]$scrapy startprojectquotesPycharmProjects/quotes
New Scrapy project 'quotes', using template directory '/home/eason/ENV1/lib/python2.7/site-packages/scrapy/templates/project', created in:
/home/eason/PycharmProjects/quotes
You can start your first spider with:
cd PycharmProjects/quotes
scrapy genspider example example.com
(ENV1) [eason@localhost ~]$
2.进入项目路径并创建spider,命令的具体用法为
scrapy genspider [-t template]
[-t template] 指定生成spider的模板,可用模板有如下4种,缺省时默认为basic
basic
crawl
csvfeed
xmlfeed
设定spider的名字
设定allowed_domains和start_urls
本文的spider名称为quotes_spider
(ENV1) [eason@localhost ~]$cd PycharmProjects/quotes
(ENV1) [eason@localhost quotes]$scrapy genspiderquotes_spiderquotes.toscrape.com
Created spider 'quotes_spider' using template 'basic' in module:
quotes.spiders.quotes_spider
(ENV1) [eason@localhost quotes]$
至此,创建项目以及spider的工作已经完成了。
3.在Pycharm中打开上面刚刚创建的项目
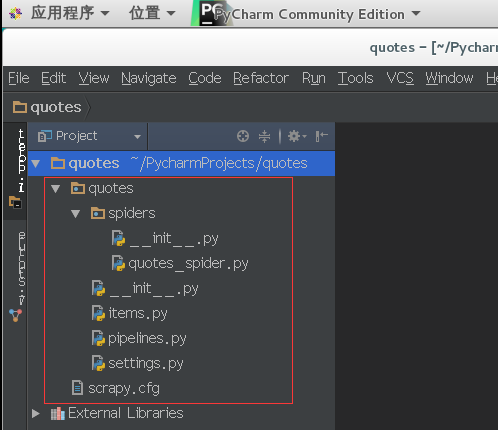
红框内为我们刚才创建项目的目录结构
├── quotes
│ └── spiders
│ └── __init__.py
| └── quotes_spider.py
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
└── scrapy.cfg
参考官网文档的解释如下:
quotes/
project's Python module, you'll import your code from here(该项目的python模块。之后您将在此加入代码。)
quotes/spiders/
a directory where you'll later put your spiders(放置spider代码的目录.用来将网页爬下来)
quotes/spiders/quotes_spider.py
刚才自动生成的spider文件
quotes/items.py
project items definition file(项目中的item文件,其实就是要抓取的数据的结构定义)
quotes/pipelines.py
project pipelines file(项目的pipelines文件,在这里可以定义将抓取的数据以何种方式保存)
quotes/settings.py
project settings file(项目的设置文件)
scrapy.cfg
deploy configuration file(项目配置文件)
4.此时打开quotes_spider.py 文件会报错,提示找不到scrapy的模块,这是因为当前pycharm是在全局环境打开该项目,而我全局环境并没有安装scrapy,所以下面更改项目设置,让pycharm能使用虚拟环境的包和模块

依次点击菜单栏的File-->Settings打开设置界面,Project Interpreter下拉选择当前已经激活的虚拟环境,可能你那边的路径不一样,本文是/home/eason/ENV1/bin/python

选好以后点击OK,重新打开quotes_spider.py发现已经不报错了。
5.编辑items.py定义数据结构
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class QuotesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
article=scrapy.Field()
author=scrapy.Field()
pass
5.编辑quotes_spider.py添加爬取规则
# -*- coding: utf-8 -*-
import scrapy
from ..items import QuotesItem
class QuotesSpiderSpider(scrapy.Spider):
name = "quotes_spider"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
items=[]
articles=response.xpath("//div[@class='quote']")
for article in articles:
item=QuotesItem()
content=article.xpath("span[@class='text']/text()").extract_first()
author=article.xpath("span/small[@class='author']/text()").extract_first()
item['article']=content.encode('utf-8')
item['author'] = author.encode('utf-8')
items.append(item)
return items
6.编辑pipelines.py,确定数据保存方法,本文为写到文本文件result.txt中
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class QuotesPipeline(object):
def process_item(self, item, spider):
#爬取的数据保存在/home/eason/PycharmProjects/quotes/路径下
f = open(r"/home/eason/PycharmProjects/quotes/result.txt", "a")
f.write(item['article']+'\t' +item['author']+'\n')
f.close()
return item
7.为了让pipeline.py生效,还需要在settings.py文件中注册
# -*- coding: utf-8 -*-
# Scrapy settings for quotes project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'quotes'
SPIDER_MODULES = ['quotes.spiders']
NEWSPIDER_MODULE = 'quotes.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'quotes.pipelines.QuotesPipeline': 300,
}
8.在Pycharm中打开Terminal,激活虚拟环境并运行spider
[eason@localhost quotes]$source /home/eason/ENV1/bin/activate
(ENV1) [eason@localhost quotes]$scrapy crawl quotes_spider
9.爬取完成后,会在/home/eason/PycharmProjects/quotes/路径下生成result.txt文件,打开result.txt后内容如下

10.Done!