Solr是基于Lucene实现的全文搜索程序。官网是http://lucene.apache.org/solr/
安装
从官网下载的Solr,是一个压缩包文件,没有安装向导程序,直接解压,然后在bin目录中通过命令行即可启动。
解压之后得到的如下的目录结构:
- bin // 存放启动脚本
- contrib // 非Solr的第三方提供的包
- dist // Solr源代码编译产生的包
- docs // Solr文档
- example // 存放示例文件,通过这里提供的示例文件来学习Solr
- license // 存放法律协议
- server // 存放服务程序,Solr内嵌了jetty程序
练习1 索引Techproducts示例数据
练习目标:通过本次练习,学会如何启动Solr,如何建立索引,如何使用索引搜索。
启动SolrCloud
Unix平台通过bin/solr start -e cloud启动;Windows平台通过bin\solr.cmd start -e cloud启动。
命令执行后出现一个交互式会话,你根据提示配置Solr。
solr-8.1.0:$ ./bin/solr start -e cloud
Welcome to the SolrCloud example!
This interactive session will help you launch a SolrCloud cluster on your local workstation.
To begin, how many Solr nodes would you like to run in your local cluster? (specify 1-4 nodes) [2]:
首先提示你选择节点数量,默认是2。练习情况下直接选择默认值2,回车进入一下项。
Ok, let's start up 2 Solr nodes for your example SolrCloud cluster.
Please enter the port for node1 [8983]:
设置节点1的端口。
Please enter the port for node2 [7574]:
设置节点2的端口。
Starting up 2 Solr nodes for your example SolrCloud cluster.
Creating Solr home directory /solr-8.1.0/example/cloud/node1/solr
Cloning /solr-8.1.0/example/cloud/node1 into
/solr-8.1.0/example/cloud/node2Starting up Solr on port 8983 using command:
"bin/solr" start -cloud -p 8983 -s "example/cloud/node1/solr"Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=34942). Happy searching!
Starting up Solr on port 7574 using command:
"bin/solr" start -cloud -p 7574 -s "example/cloud/node2/solr" -z localhost:9983Waiting up to 180 seconds to see Solr running on port 7574 [\]
Started Solr server on port 7574 (pid=35036). Happy searching!INFO - 2017-07-27 12:28:02.835; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready
至此Solr已经正确启动了,下面开始建立索引,但是在建立索引之前必须要建立一个collection,目前可以理解collection为索引的容器。
Now let's create a new collection for indexing documents in your 2-node cluster.
Please provide a name for your new collection: [gettingstarted]
这里提示你创建一个collection,默认的collection名字为gettingstarted,这里我们输入techproducts,因为我们示例就是这个,后面操作都是围绕这个名称进行的。
How many shards would you like to split techproducts into? [2]
提示你选择分片数量,默认值进行下一步。
How many replicas per shard would you like to create? [2]
指定每个分片上的索引备份数量,此举是为了避免发生故障丢失数据。选择默认值进行下一步。
Please choose a configuration for the techproducts collection, available options are:
_default or sample_techproducts_configs [_default]
为collection选择配置文件。选择默认值进行下一步。
Uploading /solr-8.1.0/server/solr/configsets/_default/conf for config techproducts to ZooKeeper at localhost:9983
Connecting to ZooKeeper at localhost:9983 ...
INFO - 2017-07-27 12:48:59.289; org.apache.solr.client.solrj.impl.ZkClientClusterStateProvider; Cluster at localhost:9983 ready
Uploading /solr-8.1.0/server/solr/configsets/sample_techproducts_configs/conf for config techproducts to ZooKeeper at localhost:9983Creating new collection 'techproducts' using command:
http://localhost:8983/solr/admin/collections?action=CREATE&name=techproducts&numShards=2&replicationFactor=2&maxShardsPerNode=2&collection.configName=techproducts{
"responseHeader":{
"status":0,
"QTime":5460},
"success":{
"192.168.0.110:7574_solr":{
"responseHeader":{
"status":0,
"QTime":4056},
"core":"techproducts_shard1_replica_n1"},
"192.168.0.110:8983_solr":{
"responseHeader":{
"status":0,
"QTime":4056},
"core":"techproducts_shard2_replica_n2"}}}Enabling auto soft-commits with maxTime 3 secs using the Config API
POSTing request to Config API: http://localhost:8983/solr/techproducts/config
{"set-property":{"updateHandler.autoSoftCommit.maxTime":"3000"}}
Successfully set-property updateHandler.autoSoftCommit.maxTime to 3000SolrCloud example running, please visit: http://localhost:8983/solr
至此collection已经建立成功。最后一行提示告诉我们可以访问http://localhost:8983/solr站点,试试访问该站点,看看都有什么吧!
索引Techproducts数据
这里使用的原始数据存放在example/exampledocs下,使用下面的命令索引数据。
unix
solr-8.1.0:$ bin/post -c techproducts example/exampledocs/*
windows
C:\solr-8.1.0> java -jar -Dc=techproducts -Dauto example\exampledocs\post.jar example\exampledocs\*
命令执行时会看到如下提示。
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/techproducts/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
POSTing file books.csv (text/csv) to [base]
POSTing file books.json (application/json) to [base]/json/docs
POSTing file gb18030-example.xml (application/xml) to [base]
POSTing file hd.xml (application/xml) to [base]
POSTing file ipod_other.xml (application/xml) to [base]
POSTing file ipod_video.xml (application/xml) to [base]
POSTing file manufacturers.xml (application/xml) to [base]
POSTing file mem.xml (application/xml) to [base]
POSTing file money.xml (application/xml) to [base]
POSTing file monitor.xml (application/xml) to [base]
POSTing file monitor2.xml (application/xml) to [base]
POSTing file more_books.jsonl (application/json) to [base]/json/docs
POSTing file mp500.xml (application/xml) to [base]
POSTing file post.jar (application/octet-stream) to [base]/extract
POSTing file sample.html (text/html) to [base]/extract
POSTing file sd500.xml (application/xml) to [base]
POSTing file solr-word.pdf (application/pdf) to [base]/extract
POSTing file solr.xml (application/xml) to [base]
POSTing file test_utf8.sh (application/octet-stream) to [base]/extract
POSTing file utf8-example.xml (application/xml) to [base]
POSTing file vidcard.xml (application/xml) to [base]
21 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/techproducts/update...
Time spent: 0:00:00.822
至此索引已经建立,下面尝试搜索吧!
基础搜索
还记得前面的站点吧,打开它,选择techproducts核,选择query菜单。

尝试去探索上面的页面,探索他的功能,尝试立即界面元素的含义。
。。。。
除了通过后台管理界面搜索之外,我们还可以通过Restful API搜索,例如:
curl "http://localhost:8983/solr/techproducts/select?indent=on&q=*:*"
搜索一个词语
下面尝试搜索foundation关键词。
如果你使用curl,则为:
curl "http://localhost:8983/solr/techproducts/select?q=foundation"
搜索结果为:
{ "responseHeader":{ "zkConnected":true, "status":0, "QTime":8, "params":{ "q":"foundation"}}, "response":{"numFound":4,"start":0,"maxScore":2.7879646,"docs":[ { "id":"0553293354", "cat":["book"], "name":"Foundation", "price":7.99, "price_c":"7.99,USD", "inStock":true, "author":"Isaac Asimov", "author_s":"Isaac Asimov", "series_t":"Foundation Novels", "sequence_i":1, "genre_s":"scifi", "_version_":1574100232473411586, "price_c____l_ns":799}] }}
字段搜索
字段搜索即把搜索范围限制在单一字段或多个字段之内,而不是全文搜索,这种方式更加的精确。下面看看怎样进行字段搜索。
假设我们要搜索electronics关键词,在搜索界面的q输入框输入关键词,然后得到的搜索结果如下:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":6,
"params":{
"q":"electronics"}},
"response":{"numFound":14,"start":0,"maxScore":1.5579545,"docs":[
{
"id":"IW-02",
"name":"iPod & iPod Mini USB 2.0 Cable",
"manu":"Belkin",
"manu_id_s":"belkin",
"cat":["electronics",
"connector"],
"features":["car power adapter for iPod, white"],
"weight":2.0,
"price":11.5,
"price_c":"11.50,USD",
"popularity":1,
"inStock":false,
"store":"37.7752,-122.4232",
"manufacturedate_dt":"2006-02-14T23:55:59Z",
"_version_":1574100232554151936,
"price_c____l_ns":1150}]
}}
结果显示更命中了14个文档,下面我们把搜索的范围限制在cat字段,输入的关键词为cat:electronics,得到的结果如下:
{ "responseHeader":{ "zkConnected":true, "status":0, "QTime":6, "params":{ "q":"cat:electronics"}}, "response":{"numFound":12,"start":0,"maxScore":0.9614112,"docs":[ { "id":"SP2514N", "name":"Samsung SpinPoint P120 SP2514N - hard drive - 250 GB - ATA-133", "manu":"Samsung Electronics Co. Ltd.", "manu_id_s":"samsung", "cat":["electronics", "hard drive"], "features":["7200RPM, 8MB cache, IDE Ultra ATA-133", "NoiseGuard, SilentSeek technology, Fluid Dynamic Bearing (FDB) motor"], "price":92.0, "price_c":"92.0,USD", "popularity":6, "inStock":true, "manufacturedate_dt":"2006-02-13T15:26:37Z", "store":"35.0752,-97.032", "_version_":1574100232511160320, "price_c____l_ns":9200}] }}
结果显示命中了12个文档,说明字段搜索起了作用,在看看得出的文档的cat字段是否含有electronics关键词,发现有,说明结果正确。
在搜索界面上显示了本次搜索的url,如果你想使用curl,可以直接拷贝上面生产的url,此处不在列出。
短语搜索
短语是包含多个词的文本,词语直接使用空格分隔,例如“CAS latency”,它包含了两个词,分别是cas和latency。下面看看如何搜索短语。(注意这里的词和短语的概念是英文概念,中文稍有不同)
如果你使用curl,注意单词之间使用+号连接,如:
curl "http://localhost:8983/solr/techproducts/select?q=\"CAS+latency\""
得到的结果如下:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":7,
"params":{
"q":"\"CAS latency\""}},
"response":{"numFound":2,"start":0,"maxScore":5.937691,"docs":[
{
"id":"VDBDB1A16",
"name":"A-DATA V-Series 1GB 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) System Memory - OEM",
"manu":"A-DATA Technology Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"features":["CAS latency 3, 2.7v"],
"popularity":0,
"inStock":true,
"store":"45.18414,-93.88141",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|0.9 memory|0.1",
"_version_":1574100232590852096},
{
"id":"TWINX2048-3200PRO",
"name":"CORSAIR XMS 2GB (2 x 1GB) 184-Pin DDR SDRAM Unbuffered DDR 400 (PC 3200) Dual Channel Kit System Memory - Retail",
"manu":"Corsair Microsystems Inc.",
"manu_id_s":"corsair",
"cat":["electronics",
"memory"],
"features":["CAS latency 2, 2-3-3-6 timing, 2.75v, unbuffered, heat-spreader"],
"price":185.0,
"price_c":"185.00,USD",
"popularity":5,
"inStock":true,
"store":"37.7752,-122.4232",
"manufacturedate_dt":"2006-02-13T15:26:37Z",
"payloads":"electronics|6.0 memory|3.0",
"_version_":1574100232584560640,
"price_c____l_ns":18500}]
}}
组合搜索
默认情况下,你在单次查询中搜索多个关键词或者说搜索一个短语,那么只要文档中出现其中一个词就表示命中。匹配词越多的文档得分越高,出现在结果集中越靠前。例如我们要搜索alice bob这条短语,首次分词器得出两个词alice和bob,如果一个文档中含有alice,则命中这个文档。如果一个文档中同时含有alice和bob,则这个文档出现在结果集的前面。
如果你希望一个词必须出现在文档中,那么可以在那个词的前面加上前缀+号;反之,如果不希望一个词出现在文档中,那么可以在那个词的前面加上前缀-号。例如我们希望搜索结果中同时包含alice和bob,关键词可以这样组合+alice +bob。
如果你使用curl,则+ -号需要进行编码。例如:
curl "http://localhost:8983/solr/techproducts/select?q=%2Belectronics%20%2Bmusic"
总结
至此,我们已经学会了如何启动Solr,如何建立索引,如何搜索等操作。下一个练习我们将学习更多的概念和操作,如聚类搜索、schema管理。
如果你不希望继续下一个练习,希望清除数据,停止Solr,可以通过下面命令:
bin/solr delete -c techproducts
bin/solr stop -all
练习2 修改schema并建立影片数据索引
该练习基于练习1建立的索引,目标是学会修改schema和聚类搜索。
重启Solr
如果你关闭了Solr,那么需要重新启动Solr。如果你没有关闭,可以直接跳到下一节。
./bin/solr start -c -p 8983 -s example/cloud/node1/solr
接着再启动第二个节点,并指明如何连接到Zookeeper。
./bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983
创建一个新的Collection
本次练习使用全新的数据,因此最好新建一个collection。
bin/solr create -c films -s 2 -rf 2
为影片数据准备schemaless
_default配置有两个特性:
- managed schema 它只能通过Solr的Schema API修改,不能手动修改。Solr的Schema API支持修改字段、字段类和其他schema规则类型。
- field guessing 它配置在solrconfig.xml文件中,用于自动猜测字段。
这种特性听上去很好,但是如果猜错了就会很麻烦,因此不推荐在生产环境中使用。也可以混合使用猜测和自定义,对于重要字段自定义,剩余不重要的字段使用猜测特性以减少配置。
创建一个name字段
影片数据的字段通常有:ID、导演姓名、影片名称、上映日期、类型等。
打开example/films文件,你会发现第一个影片的名称为.45,2006年上映,如果我们使用字段猜测,那么Solr就会认为名称是一个浮点类型,但实际是字符串类型,因此后续的解析将会失败。因此在建立索引之前,我们首先要设置字段name的类型为字符串类型,设置方法可以通过curl和后台管理系统。
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}' http://localhost:8983/solr/films/schema
该命令创建一个text_general类型的字段,字段名称为name,字段是非多值的,并且可以被存储。
使用后台管理系统创建字段:
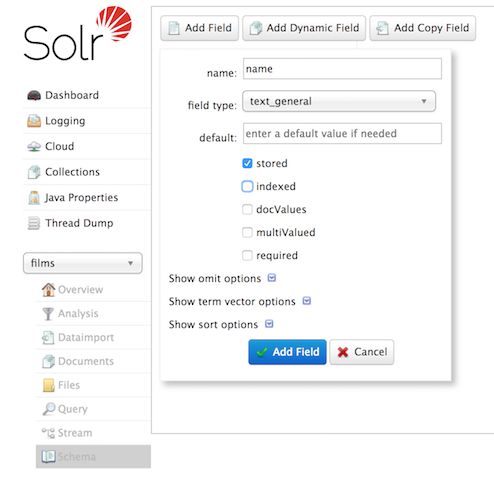
创建catchall复制字段
在练习1,当我们搜索的时候并没有指定一个字段,是因为默认的配置文件为我们创建了一个复制字段text,复制字段是拷贝其他字段的值创建的。当没有指定搜索字段时,它就作为默认的搜索字段。然而我们现在使用的配置文件没有为我们创建一个复制字段,但是我们需要这样一个字段,因此要创建一个。
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-copy-field" : {"source":"*","dest":"_text_"}}' http://localhost:8983/solr/films/schema
建立影片数据索引
影片数据位于example/films目录下,有三种格式JSON、XML和CSV,选择其中一个建立索引。
bin/post -c films example/films/films.json
C:\solr-8.1.0> java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films\*.json
聚类搜索
聚类搜索支持对搜索结果进行分类,并可以计算每类结果个数。
Field Facets
除了返回搜索结果,还返回文章数量。
在管理界面的搜索页,如果你勾选了facet复选框,将会看到三个选项。

搜索所有文章,勾选facet选项,并在facet.field中输入genre_str字段,如果你只想看到聚类数量,可以把rows指定为0。
curl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=true&facet.field=genre_str"
结果如下:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":11,
"params":{
"q":"*:*",
"facet.field":"genre_str",
"rows":"0",
"facet":"true"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{
"genre_str":[
"Drama",552,
"Comedy",389,
"Romance Film",270,
"Thriller",259,
"Action Film",196,
"Crime Fiction",170,
"World cinema",167]},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{}}}
这个结果截掉了一部分,但是不影响我们观察,可以看到返回结果显示了各种体裁的影片数量。Solr还提供了一个facet.mincount参数,用于控制返回分类的结果最小数量,即小于这个数量的分类不展示。
curl "http://localhost:8983/solr/films/select?=&q=*:*&facet.field=genre_str&facet.mincount=200&facet=on&rows=0"
Rang Facets
对于数字和日期类型的数据,我们通常希望使用范围来分类,而不是具体的值。例如价格数据的分类一般是这样的

影片的上映时间是一个日期类型,可以用来练习rang facets。
后台管理系统还不支持范围聚类,因此这里只有使用curl了。
curl 'http://localhost:8983/solr/films/select?q=*:*&rows=0'\
'&facet=true'\
'&facet.range=initial_release_date'\
'&facet.range.start=NOW-20YEAR'\
'&facet.range.end=NOW'\
'&facet.range.gap=%2B1YEAR'
结果如下
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":8,
"params":{
"facet.range":"initial_release_date",
"facet.limit":"300",
"q":"*:*",
"facet.range.gap":"+1YEAR",
"rows":"0",
"facet":"on",
"facet.range.start":"NOW-20YEAR",
"facet.range.end":"NOW"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{
"initial_release_date":{
"counts":[
"1997-07-28T17:12:06.919Z",0,
"1998-07-28T17:12:06.919Z",0,
"1999-07-28T17:12:06.919Z",48,
"2000-07-28T17:12:06.919Z",82,
"2001-07-28T17:12:06.919Z",103,
"2002-07-28T17:12:06.919Z",131,
"2003-07-28T17:12:06.919Z",137,
"2004-07-28T17:12:06.919Z",163,
"2005-07-28T17:12:06.919Z",189,
"2006-07-28T17:12:06.919Z",92,
"2007-07-28T17:12:06.919Z",26,
"2008-07-28T17:12:06.919Z",7,
"2009-07-28T17:12:06.919Z",3,
"2010-07-28T17:12:06.919Z",0,
"2011-07-28T17:12:06.919Z",0,
"2012-07-28T17:12:06.919Z",1,
"2013-07-28T17:12:06.919Z",1,
"2014-07-28T17:12:06.919Z",1,
"2015-07-28T17:12:06.919Z",0,
"2016-07-28T17:12:06.919Z",0],
"gap":"+1YEAR",
"start":"1997-07-28T17:12:06.919Z",
"end":"2017-07-28T17:12:06.919Z"}},
"facet_intervals":{},
"facet_heatmaps":{}}}
Pivot Facets
这种聚类也称为决策树,它支持多个字段嵌套聚类。例如我们像知道drama体裁的电影有多少位导演。
curl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=on&facet.pivot=genre_str,directed_by_str"
{"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":1147,
"params":{
"q":"*:*",
"facet.pivot":"genre_str,directed_by_str",
"rows":"0",
"facet":"on"}},
"response":{"numFound":1100,"start":0,"maxScore":1.0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{},
"facet_pivot":{
"genre_str,directed_by_str":[{
"field":"genre_str",
"value":"Drama",
"count":552,
"pivot":[{
"field":"directed_by_str",
"value":"Ridley Scott",
"count":5},
{
"field":"directed_by_str",
"value":"Steven Soderbergh",
"count":5},
{
"field":"directed_by_str",
"value":"Michael Winterbottom",
"count":4}}]}]}}}