进半年,大量学习和实践深度学习方面的知识,因此希望把所学的知识进行总结梳理,帮助更多同路的人。在这里连载文章,希望得到更多的人的支持。同时感谢港理工的佳佳博士与我一起完成这本书,一路过来,谢谢。
2.3 使用ANN对医疗数据分类
IBM在2015年5月宣布推出Watson Health服务,收集健康数据交给Watson超级计算机进行分析。目前IBM Waston Health最主要的应用便是在癌症的诊疗上,通过对医学影像的分析和学习,帮助医生做出对癌症患者的精准诊断。另外一方面,在每一个国家的医疗资源都是十分稀缺的,如何提高基层医生的诊疗水平显得至关重要。我们并不需要智能诊疗会取代医生,因为医疗也并不是简单的诊断,医生更重要的价值还在于对诊断结果的解释、说明和信用背书,但让智能诊疗系统辅助医生诊断,则无疑会大大提高普通医生的诊断水平和诊断效率,降低误诊率。
因此,人工智能对于辅助医生的工作来说,越显得非常重要。例如:医生可以根据人工智能给出女性最佳生育期的建议,不再仅仅基于她们的年龄,而是基于一系列相关的个人身体指标。
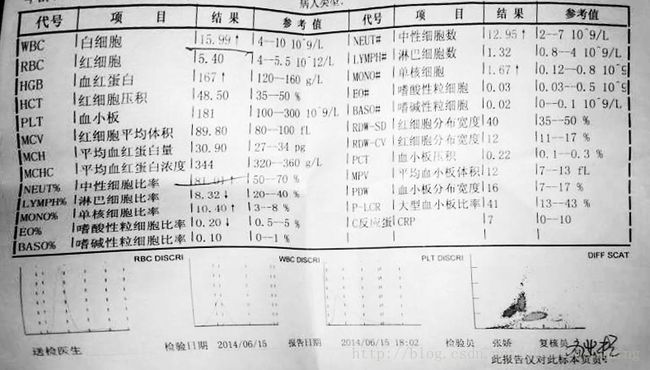
以现代医疗检测报告为例,很多时候我们去医院抽血、检查细胞病变等检查之后,检查室开出一张看不懂的表格如图2.3.1,上面有白细胞、链球菌、血小板的参数,医生通过检查这些参数值得大小和变化,可以预测判断该病人是否患有某种病原体。
下面我们将把类似的医疗数据作为背景:首先给出对的医疗检测数据进行数学模型的转换,然后通过构建一个三层的人工神经网络ANN对已有的医疗数据进行训练, 得到该医疗数据的分类模型,然后对新的数据进行预测其所属分类,因为人工神经网络的隐层对数据的分类存在较大影响,因此最后探讨隐层的神经元节点数对实际的数据有如何的影响。
2.3.1 准备数据:从医疗数据到数学模型
假设本次血液检测项目只有链球菌x1和葡萄球菌x2两种,对于不同的球菌组合,会出现不同的病原体(不同的病症)。假设有两个分类,分别是病原体I和病原体II,病原体I、病原体II分别用用蓝色、红色表达;x轴表示链球菌的值,y轴表示葡萄球菌的值。在本例程这里的数据已经归一化处理过后,因此数据的分布集中在[-2, 2]之间(想要了解更多关于归一化操作请参考机器学习实践[1])。
我们的目标是通过训练一个三层的人工神经网络ANN模型,对给出不同血液检测项目(x1、x2)的数据进行分类。值得注意的是,因为很多时候医疗数据是线性不可分的,因此我们并不能够简单地使用一条直线对数据进行划分。这意味着不能够用线性分类器来分类,例如Logistic分类器、贝叶斯分类器等,否则分类的数据精度和回召率过低,会对真实的医疗诊断结果造成巨大的影响。
使用神经网络的好处就是不需要去担心特征工程问题,隐层会自动地去寻找特征。
from sklearn import linear_model
from sklearn import datasets
import sklearn
import numpy as np
import matplotlib.pyplot as plt
# 在notebook内显示plt图
%matplotlib inline
def plot_decision_boundary(pred_func, data, labels):
'''绘制分类边界图'''
# 设置最大值和最小值并增加0.5的边界(0.5 padding)
x_min, x_max = data[:, 0].min() - 0.5, data[:, 0].max() + 0.5
y_min, y_max = data[:, 1].min() - 0.5, data[:, 1].max() + 0.5
h = 0.01
# 生成一个点阵网格,点阵间距离为h
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 预测整个网格当中的函数值
z = pred_func(np.c_[xx.ravel(), yy.ravel()])
z = z.reshape(xx.shape)
# 绘制轮廓和训练样本
plt.contourf(xx, yy, z, cmap=plt.cm.Spectral)
plt.scatter(data[:, 0], data[:, 1], s=40, c=labels, cmap=plt.cm.Spectral)
np.random.seed(0)
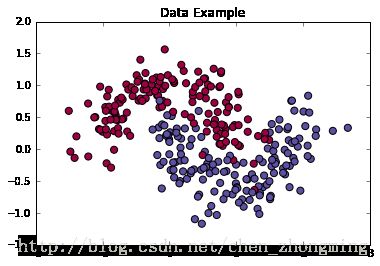
X, y = datasets.make_moons(300, noise=0.25) # 300个数据点,噪声设定0.3
plt.scatter(X[:,0], X[:,1], s = 50, c = y, cmap=plt.cm.Spectral, edgecolors="Black")
plt.title('Data Example')
plt.show()
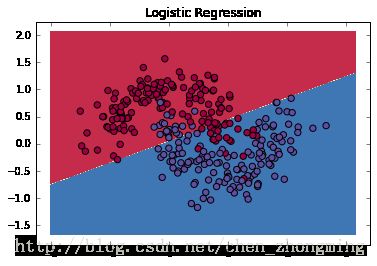
逻辑回归结果
下图显示了我们逻辑回归分类器的分类结果,逻辑回归算法直接用直线将数据分隔开两类,明显这样的分类结果是远远不能满足真实情况的。
# 使用scikit-learn的线性回归分类器
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, y)
# 显示分类结果
plot_decision_boundary(lambda x: clf.predict(x), X, y)
plt.title("Logistic Regression")
2.3.2 建立人工神经网络模型
为了解决现实情况更多线性不可分的数据,我们需要建立一个三层神经网络,输入层、隐层、输出层。
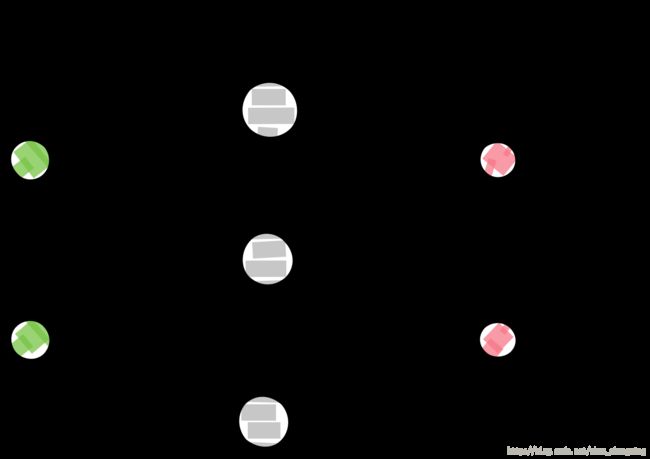
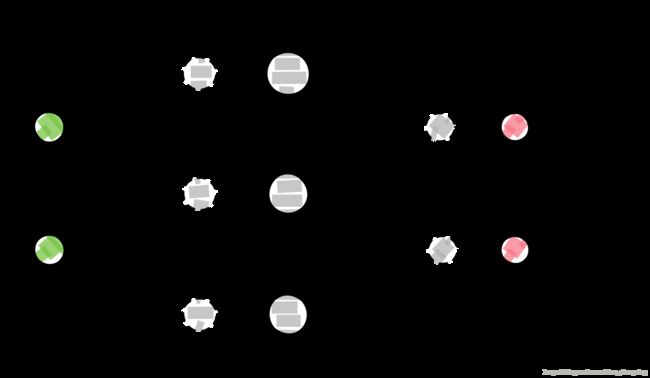
其中输入层(第一层)中的神经节点数目由输入数据的维数决定,例子有链球菌x1和葡萄球菌x2,因此数据维度是2,输入有两个神经元节点。同理,输出层(第三层)中的节点数目由我们的分类数决定,例子里为病原体I(0)和病原体II(1),因此输出层有两个神经元。该神经网络如图2.3.4所示。
根据实际情况我们可以增加隐层数和每一隐层的节点数,当隐层越多、隐层节点越多,能够处理更加复杂数据模型,但是伴随着是更大的开销:
1.更多隐层意味着我们的网络模型越大,引入更多的权值参数,占用更多GPU显存;
2.参数数量越多,数据过度拟合的可能性就越大,网络就有可能不稳定,预测效果反而下降;
那么如何选择适当的隐层数呢?每层隐藏层的神经元数应该设置多少呢?这是一个工程问题,不同的数据会有不一样的结果,所以作者觉得神经网络的设计是一种工程艺术,我们需要去尝试、训练、预测、评估,才能最终决定整个网络模型的形态,感受深度学习的魅力所在。
在隐层我们需要一个激活函数,激活函数把输出层转换成为下一层的输入层。非线性的激活函数能够让我们去处理非线性的问题。常用的有tanh函数、sigmoid函数或者ReLUs函数。例子里我们选择使用tanh函数,你也可以尝试把tanh函数换成其他函数查看输出。
最后通过softmax分类器把激活函数的输出分数转换成为概率。
Softmax分类器
预测网络
人工神经网络的预测使用向前反馈操作,我们可以理解为激活函数和矩阵乘法的操作。假设输入x是二维,我们可以根据计算公式得到输出分类结果$\hat{y}$:
$z_1=xW_1+b_1$
$a_1=tanh(Z_1)$
$z2=a_1W_2+b_2$
$a_2=\hat{y}=softmax(Z_2)$
$z_i$是第$i$层的输入,$a_i$是第$i$层激活函数处理后的输出。$W_1,b_1,W_2,b_2$是神经网络的参数,用来学习和训练用的数据,这里可以把它们当做在网络中的的矩阵。图2.3.5是图2.3.4的展开。如果在隐层中使用100个神经元节点,那么有$W_1\in\mathbb{R}^{2100}, b_1\in\mathbb{R}{100},W_2\in\mathbb{R}{1002}, b_2\in\mathbb{R}^{2}$,从上面的公式可以看出来增加隐层的节点数会大量的增加网络
的参数。
参数学习
学习参数意味着需要找$W_1,b_1,W_2,b_2$,使得我们的数据误差最小。那么如何定义误差?我们称这个检测误差的函数叫做损失函数(loss function)。这里我们使用较为常用交叉熵损失函数(也叫做负对数似然函数)。如果我们有N个训练样本和对应C个分类,那么预测值$\hat{y}$与实际值y的损失是:
$$L(y,\hat{y})=-\frac{1}{N}\sum_{n\in N}\sum_{i\in C}y_{n,i}{log\hat{y}_{n,i}}$$
当实际值$y$与预测值$\hat{y}$之间的概率分布差别越大,损失就越大。因此通过寻找好的权重参数,最大限度地减少损失,提高数据分类的准确性。
例子里我们使用梯度下降算法去找损失函数的最小值,使用一个固定的学习速率实现批量梯度下降算法(在实际工程当中通常是使用随机梯度下降或minibatch梯度下降算法的)。
梯度下降首先需要对神经网络模型用到的参数进行求导:$\frac{\partial L}{\partial W_1},\frac{\partial L}{\partial b_1},\frac{\partial L}{\partial W_2},\frac{\partial L}{\partial b_2}$。而求得这些梯度则使用著名的BP算法,在这里不在给出推导过程,而是直接使用推导后的公式:
$\delta _3=\hat{y}-y$
$\delta _2=(1-tanh2z_1)*\delta_3W_2T$
$\frac{\delta L}{\delta W_2}=\alpha _1^T \delta_3$
$\frac{\delta L}{\delta b_2}=\delta _3$
$\frac{\delta L}{\delta w_1}=x^T\delta _2$
$\frac{\delta L}{\delta b_1}=\delta _2$
2.3.3 Python实现ANN
首先定义一些梯度下降的时候用到的一些变量:
class Config:
input_dim = 2 # 输入的维度
output_dim = 2 # 输出的分类数
epsilon = 0.01 # 梯度下降学习速度
reg_lambda = 0.01 # 正则化强度
下面的损失函数的实现,通过这个函数我们观察模型训练的效果:
def calculate_loss(model, X, y):
'''
损失函数
'''
num_examples = len(X) # 训练集大小
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 正向传播计算预测值
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 计算损失值
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# 对损失值进行归一化(可以不加)
data_loss += Config.reg_lambda / 2 * \
(np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1. / num_examples * data_loss
接下来实现预测函数,预测的时候只需要对模型进行一次向前传播,然后返回分类结果中概率最大的一项:
def predict(model, x):
'''
预测函数
'''
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 向前传播
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
接下是整个人工神经网络模型的函数,这个函数实现了使用向后传播算法来计算批量梯度下降,使用了2.3.2中参数学习的公式:
def ANN_model(X, y, nn_hdim, num_passes=20000, print_loss=False):
'''
网络学习函数,并返回网络
- nn_hdim: 隐层的神经元节点(隐层的数目)
- num_passes: 梯度下降迭代次数
- print_loss: 是否显示损失函数值
'''
num_examples = len(X) # 训练的数据集
model = {} # 模型存储定义
# 随机初始化参数
np.random.seed(0)
W1 = np.random.randn(Config.input_dim, nn_hdim) / np.sqrt(Config.input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, Config.output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, Config.output_dim))
# display_model({'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2})
# 批量梯度下降
for i in xrange(0, num_passes + 1):
# 向前传播
z1 = X.dot(W1) + b1 # M_200*2 .* M_2*3 --> M_200*3
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2 # M_200*3 .* M_3*2 --> M_200*2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 向后传播
delta3 = probs # 得到的预测值
delta3[range(num_examples), y] -= 1 # 预测值减去实际值
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW2 = (a1.T).dot(delta3) # W2的导数
db2 = np.sum(delta3, axis=0, keepdims=True) # b2的导数
dW1 = np.dot(X.T, delta2) # W1的导数
db1 = np.sum(delta2, axis=0) # b1的导数
# 添加正则化项
dW1 += Config.reg_lambda * W1
dW2 += Config.reg_lambda * W2
# 根据梯度下降值更新权重
W1 += -Config.epsilon * dW1
b1 += -Config.epsilon * db1
W2 += -Config.epsilon * dW2
b2 += -Config.epsilon * db2
# 把新的参数加入模型当中
model = {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" %
(i, calculate_loss(model, X, y)))
return model
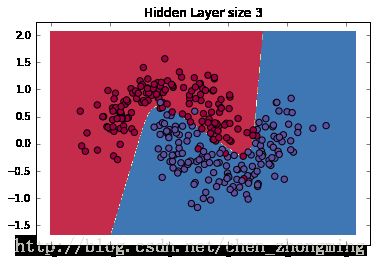
下面我们来看一下训练的网络只有隐层节点数只有三个的时候训练的结果:
model = ANN_model(X, y, 3, print_loss=True) # 建立三个神经元的隐层
plot_decision_boundary(lambda x: predict(model, x), X, y)
plt.title("Hidden Layer size 3")
Loss after iteration 0: 0.389105
Loss after iteration 1000: 0.120831
Loss after iteration 2000: 0.116688
Loss after iteration 3000: 0.115724
Loss after iteration 4000: 0.115322
Loss after iteration 5000: 0.115115
Loss after iteration 6000: 0.114996
Loss after iteration 7000: 0.114923
Loss after iteration 8000: 0.114876
Loss after iteration 9000: 0.114845
Loss after iteration 10000: 0.114825
Loss after iteration 11000: 0.114811
Loss after iteration 12000: 0.114801
Loss after iteration 13000: 0.114794
Loss after iteration 14000: 0.114789
Loss after iteration 15000: 0.114786
Loss after iteration 16000: 0.114784
Loss after iteration 17000: 0.114782
Loss after iteration 18000: 0.114781
Loss after iteration 19000: 0.114780
Loss after iteration 20000: 0.114779
2.3.4 隐层节点数对模型的影响
从上图可以看出人工神经网络模型的训练效果比Logistic回归的效果好很多,但是依然可以看出有个别数据的分类是错误的。接下来通过实际工程测试去深入了解隐层节点对模型的影响:
plt.figure(figsize=(16, 32))
hidden_layer_dimensions = [1, 2, 3, 4, 5, 15, 30, 50]
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer size %d' % nn_hdim)
model = ANN_model(X, y, nn_hdim)
plot_decision_boundary(lambda x: predict(model, x), X, y)
plt.show()

通过上图我们可以看到,隐层数在低维(4、5)的时候能够很好地表达数据的分类属性,隐层节点数越高,会造成过度拟合(如隐层数为50时)。造成这种原因是因为隐层数较低的时候会有更好的归一化表现,当隐层数正价的时候,归一化过度造成过度拟合。如果想要更好地评估这个医疗数据分类模型,更建议把数据分为训练集和测试集,然后检测测试集的效果。