之前写的爬虫,无论是单线程,多线程异步等都是在自己的电脑上运行。
好处是单个爬虫方便管理,调试;但当有了大量的URL需要爬取,用分布式爬虫无疑是最好的选择。
我的测试代码以实习僧网为目标网站,约2w个URL,单个scrapy与3个scrapy-redis分布式时间比约为 5: 1
这篇文章会通过一个例子详细介绍scrapy-redis原理及其实现过程。
0.安装scrapy_redis
windows、ubuntu安装请参看:http://blog.fens.me/linux-redis-install/
centos7安装请参看:https://www.cnblogs.com/zjl6/p/6742673.html
注意:建议设置redis密码进行远程连接,或者添加安全组规则ip白名单,直接暴露端口容易被黑。
1.首先介绍一下:scrapy-redis框架
scrapy-redis:一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能。
github地址: https://github.com/darkrho/scrapy-redis
一篇知乎介绍《scrapy-redis 和 scrapy 有什么区别?》
2.再介绍一下:分布式原理
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为master,而把用于跑爬虫程序的机器称为slave。
我们知 道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了。
我们在master上搭建一个redis数据库(注意这个数据库只用作url的存储,不关心爬取的具体数据,不要和后面的mongodb或者mysql混淆),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置slave上scrapy-redis获取url的地址为master地址。这样的结果就是,尽管有多个slave,然而大家获取url的地方只有一个,那就是服务器master上的redis数据库。
并且,由于scrapy-redis自身的队列机制,slave获取的链接不会相互冲突。这样各个slave在完成抓取任务之后,再把获取的结果汇总到服务器上(这时的数据存储不再在是redis,而是mongodb或者 mysql等存放具体内容的数据库了)
这种方法的还有好处就是程序移植性强,只要处理好路径问题,把slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情。
3.分布式爬虫的实现:
1.使用两台机器,一台是win10,一台是ubuntu16.04,分别在两台机器上部署scrapy来进行分布式抓取一个网站
2.ubuntu16.04的ip地址为39.106.155.194,用来作为redis的master端,win10的机器作为slave
3.master的爬虫运行时会把提取到的url封装成request放到redis中的数据库:“dmoz:requests”,并且从该数据库中提取request后下载网页,再把网页的内容存放到redis的另一个数据库中“dmoz:items”
4.slave从master的redis中取出待抓取的request,下载完网页之后就把网页的内容发送回master的redis
5.重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,再把master的redis中的“dmoz:items”数据库写入到mongodb中
6.master里的reids还有一个数据“dmoz:dupefilter”是用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),是防止重复抓取的
(注:master与salve已经安装了MongoDB,Redis,scrapy,MySQL。)
4.完整实现过程
1、完成编码,多复制几份,把其中一份放到ubuntu作为master,其他几份留在windows作slave
2、启动master端scrapy,向master的redis中添加url,添加完成后master会继续运行爬虫,从redis取url进行抓取,数据存入master mongodb
3、启动多个slave爬虫,slave会远程向master redis中取url采集数据,采集数据会实时存入master mongodb中。
新建一个scrapy项目,完成常规的爬虫编码。
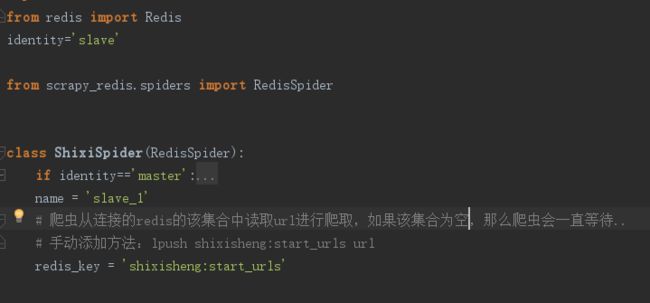
开始改动代码实现分布式爬虫,首先引入RedisSpider,把原来继承自scrapy.spider改为继承RedisSpider。
添加redis_key = 'shixisheng:start_urls' ;这里的redis_key实际上就是一个变量名,master爬虫爬到的所有URL都会保存到redis中这个名为“readcolorspider:start_urls”的列表下面,slave爬虫同时也会从这个列表中读取后续页面的URL。这个变量名可以任意修改。
修改设置settings.py
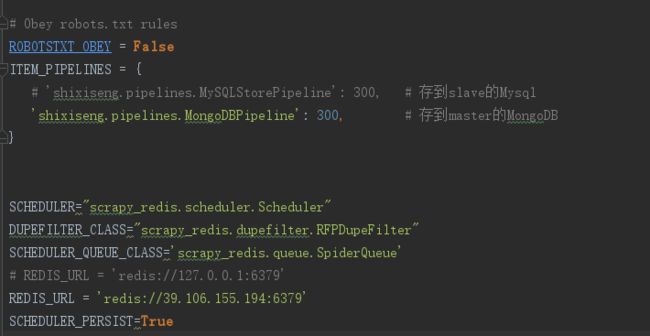
①Scheduler,首先是Scheduler的替换,这个东西是Scrapy中的调度员。在settings.py中添加以下代码:
SCHEDULER="scrapy_redis.scheduler.Scheduler"
②去重
DUPEFILTER_CLASS="scrapy_redis.dupefilter.RFPDupeFilter"
③不清理Redis队列
SCHEDULER_PERSIST=True
如果这一项为True,那么在Redis中的URL不会被Scrapy_redis清理掉,这样的好处是:爬虫停止了再重新启动,它会从上次暂停的地方开始继续爬取。但是它的弊端也很明显,如果有多个爬虫都要从这里读取URL,需要另外写一段代码来防止重复爬取。
如果设置成了False,那么Scrapy_redis每一次读取了URL以后,就会把这个URL给删除。这样的好处是:多个服务器的爬虫不会拿到同一个URL,也就不会重复爬取。但弊端是:爬虫暂停以后再重新启动,它会重新开始爬。
④设置redis地址
启用本地redis: REDIS_URL = 'redis://127.0.0.1:6379'
启用远程redis: REDIS_URL = 'redis://39.106.155.194:6379'其他设置(可选)
爬虫请求的调度算法
爬虫的请求调度算法,有三种情况可供选择:
①队列
SCHEDULER_QUEUE_CLASS='scrapy_redis.queue.SpiderQueue'
如果不配置调度算法,默认就会使用这种方式。它实现了一个先入先出的队列,先放进Redis的请求会优先爬取。
②栈
SCHEDULER_QUEUE_CLASS='scrapy_redis.queue.SpiderStack'
这种方式,后放入到Redis的请求会优先爬取。
③优先级队列
SCHEDULER_QUEUE_CLASS='scrapy_redis.queue.SpiderPriorityQueue'
这种方式,会根据一个优先级算法来计算哪些请求先爬取,哪些请求后爬取。这个优先级算法比较复杂,会综合考虑请求的深度等各个因素。
呼~~配置完这些,爬虫就可以正常工作了,slave从master取url采集数据,当master redis中"shixisheng:start_urls"和"slave_1:requests"都为空时,爬虫会暂停等待,直到redis中有新的url。若再无新url添加进来,就可以在此刻结束程序。
分布式爬虫状态与对应的redis中集合的变化

该聊聊数据存储的问题了
两种方法:
- 1.各存各的,master仅提供待爬取url,slave采集后数据存在slave本地,最后把数据汇总即可,这样一来数据就存在了master一部分,各slave一部分,如果slave比较多,数据的汇总也比较麻烦。
- 2.各个slave采集数据的同时把数据实时的发送到master,这样数据只存在于master,而slave就充当了真正意义上的“slave”————“干完就走,两袖清风”
显然第二种办法比较好,master即master,slave即slave。
该项目数据库选用了mongodb。(也实现了存Mysql,下文会讲)
针对不同类型数据可以根据具体需求来选择不同的数据库存储。结构化数据可以使用mysql节省空间,非结构化、文本等数据可以采用mongodb等非关系型数据提高访问速度。具体选择可以自行百度谷歌,有很多关于sql和nosql的对比文章。
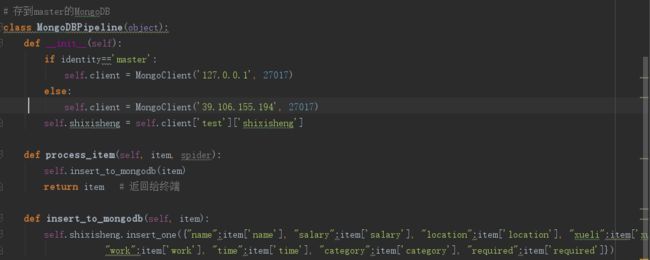
写入master mongodb代码(piplines.py)
写入slave mysql代码(piplines.py)
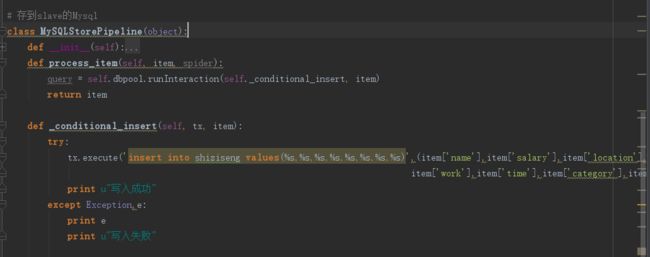
上图是save to slave mysql ,如需save to master请在MySQLStorePipeline更改数据库连接配置。
settings.py文件
master mongodb部分截图:

本项目已上传到github,欢迎友情加star: https://github.com/TimeAshore/scrapy_redis_sxs/
本人也比较小白 学术尚浅,如有什么问题,欢迎提出来共同进步。
参考文章:
http://blog.csdn.net/howtogetout/article/details/51633814
https://www.cnblogs.com/zjl6/p/6742673.html
http://blog.csdn.net/zhou_1997/article/details/52624468
http://python.jobbole.com/86328/
redis基本操作
进入本地redis:
redis-cli (linux)
在Redis安装目录运行redis-cli (win)
连接到远程redis:
redis-cli -h 39.106.155.194 -p 6379 (linux)
在Redis安装目录运行redis-cli -h 39.106.155.194 -p 6379 (win)
清空redis:flushdb
查看集合:keys *
转载需注明原文章地址:https://www.jianshu.com/p/674d90294f9c