
![TOC]
并查集操作的复杂度是log n。是一个衰减非常快的函数,即使n 很大,log n的结果也接近一个常数,不会超过5。
其实并查集顾名思义就是有“合并集合”和“查找集合中的元素”两种操作的关于数据结构的一种算法。
A case of its application
有n个人,每个人都有唯一的标签,分别是0,1,……,n – 1。已知0号得了一种传染病,这种病只要与人接触了就会传染,一传十十传百。我们统计了哪些人有过接触,求最终被感染的人是哪些?
假设我们给出的接触信息如下:
[[0, 1], [0, 2], [1, 3], [3, 4], [1, 2], [5, 4]]
先合并
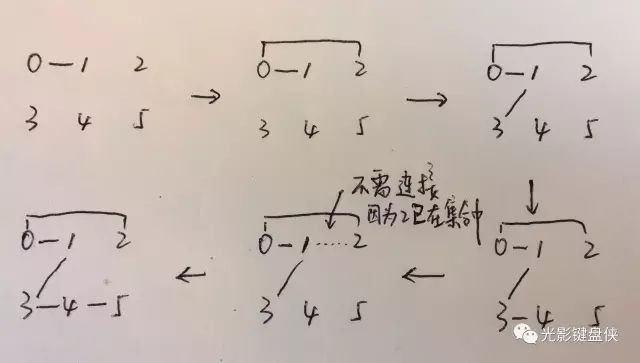
最后查找0所在的集合
Other applications
2、用在求解最小生成树的Kruskal算法里。
初始化、查找、合并
初始化存储空间(array or struct)
一般来说,题目简单用数组,题目复杂用结构体,因为结构体有条理,数组可以少打几个字。
包括对所有单个的数据建立一个单独的集合(即根据题目的意思自己建立的最多可能有的集合,为下面的合并查找操作提供操作对象)
在每一个单个的集合里面,有三个东西。
1,集合所代表的数据。(这个初始值根据需要自己定义,不固定)
2,这个集合的层次通常用rank表示(一般来说,初始化的工作之一就是将每一个集合里的rank置为0)。
3,这个集合的类别parent(有的人也喜欢用set表示)(其实就是一个指针,用来指示这个集合属于那一类,合并过后的集合,他们的parent指向的最终值一定是相同的。)
(**有的简单题里面集合的数据就是这个集合的标号,也就是说只包含2和3,1省略了)。
初始化的时候,一个集合的parent都是这个集合自己的标号。没有跟它同类的集合,那么这个集合的源头只能是自己了。
(最简单的集合就只含有这三个东西了,当然,复杂的集合就是把3指针这一项添加内容,如PKU食物链那题,我们还可以添加enemy指针,表示这个物种集合的天敌集合;food指针,表示这个物种集合的食物集合。随着指针的增加,并查集操作起来也变得复杂,题目也就显得更难了)
结构体表示法
有的人是建立一个结构体把集合表示出来,如:
#define MAX 10000
struct Node
{
int data;
int rank;
int parent;
}node[MAX];
数组表示法
有的人则是弄很多相同大小的数组,如:
int set[max];//集合index的类别,或者用parent表示
int rank[max];//集合index的层次,通常初始化为0
int data[max];//集合index的数据类型
//初始化集合
void Make_Set(int i)
{
set[i]=i;//初始化的时候,一个集合的parent都是这个集合自己的标号。没有跟它同类的集合,那么这个集合的源头只能是自己了。
rank[i]=0;
}
一般来说,题目简单用数组,题目复杂用结构体,因为结构体有条理,数组可以少打几个字。
Find without PathCompression : 查看某个元素在不在集合中,返回parent代表元
就是找到parent指针的源头,可以把函数命名为get_parent(或者find_set,这个随你喜欢,以便于理解为主)
如果集合的parent等于集合的编号(即还没有被合并或者没有同类),那么自然返回自身编号。
如果不同(即经过合并操作后指针指向了源头(合并后选出的rank高的集合))那么就可以调用递归函数,如下面的代码:
/**
*查找集合i(一个元素是一个集合)的源头(递归实现)。
如果集合i的父亲是自己,说明自己就是源头,返回自己的标号;
否则查找集合i的父亲的源头。
**/
int get_parent(int x)
{
if(node[x].parent==x)
return x;
return get_parent(node[x].parent);
}
数组的话就是:
//查找集合i(一个元素是一个集合)的源头(递归实现)
int Find_Set(int i)
{
//如果集合i的父亲是自己,说明自己就是源头,返回自己的标号
if(set[i]==i)
return set[i];
//否则查找集合i的父亲的源头
return Find_Set(set[i]);
}
Union
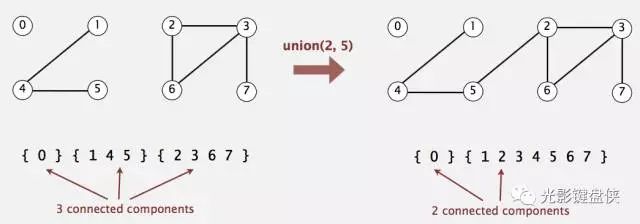
这就是所谓并查集的并了。至于怎么知道两个集合是可以合并的,那就是题目的条件了。
先看代码:
void Union(int a,int b)
{
a=get_parent(a);
b=get_parent(b);
if(node[a].rank>node[b].rank)
node[b].parent=a;
else
{
node[a].parent=b;
if(node[a].rank==node[b].rank)
node[b].rank++;
}
}
再给出数组显示的合并函数:
void Union(int i,int j)
{
i=Find_Set(i);
j=Find_Set(j);
if(i==j) return ;
if(rank[i]>rank[j]) set[j]=i;
else
{
if(rank[i]==rank[j]) rank[j]++;
set[i]=j;
}
}
Union工作原理
每次做Union操作的时候都需要先做find操作,然后再合并两个集合的祖先;K次union操作最多涉及2k个元素(假设每次做union操作的两个元素术语不同的集合)
至少需要n-1次union才能把所有元素都合并成一个n元素的大集合。也就是说,每次union操作以后,集合的数据最多减少一个(这里可以注意一下:因为之后的一道题就会用到这个理论)
Union Optimal
Path Compression通过更改查找部分的代码实现
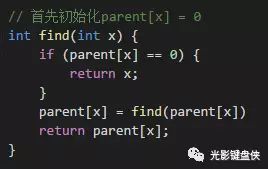
parent[x] = find(parent[x]); //路径压缩
控制树的高度来降低复杂度
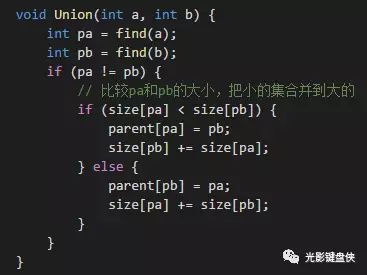
一般来说,在union操作的时候,我们有两个原则:
a. Link by size:节点较少的合并到节点多的;
b. Union by rank:高度较低的树合并到高度较高的树。
这两个优化的原理都是通过控制树的高度来降低复杂度的,因为find的时间复杂度取决于树的高度。
Exercise
小试牛刀
Longest Consecutive Sequence
大展身手
Number of Islands
http://dwz.cn/39Y5PD