nginx是我们常用反向代理软件,它的监控对于我们来说十分重要,今天介绍一些怎样利用nginx-vts模块和prometheus来实现对nginx的详细监控。
在使用vts之前,我们想要获取nginx 状态码统计,访问量,响应时间等都是通过es分析nginx访问日志得到的,受限于公司es集群的规模,我们没办法做时间跨度过大的统计。后来调研vts模块,发现我们这个模块可以完全满足我们的需求,并且查询速度非常快,查询半年数据也能很快展示出来(我们prometheus只保留半年数据)
安装
1、下载模块
https://github.com/vozlt/nginx-module-vts/releases
2、编译
编译参数添加--add-module=/path/to/nginx-module-vts
然后编译
3、替换现有bin文件
4、reload nginx
通过nginx -V来查看模块是否添加成功
###配置
1、配置状态访问接口
在default server里添加状态查看location,并做好相关访问限制
location /status{
allow 127.0.0.1;
deny all;
vhost_traffic_status_display;
vhost_traffic_status_display_format html;
}2、开启vts统计
如果想统计所有的虚拟主机,就在http配置中添加配置,否则就只在想要监控的server中添加配置
配置说明:vhost_traffic_status_zone; 开启基础监控
vhost_traffic_status_filter on;
vhost_traffic_status_filter_by_set_key $status $server_name;
#开启详细状态码统计vhost_traffic_status_filter on;
vhost_traffic_status_filter_by_set_key $uri uris::$server_name;
#开启uri统计此外还有基于地理信息的统计,根据访问量或访问流量对nginx
做访问限制,详细使用见文档:https://github.com/vozlt/nginx-module-vts#installation
监控
prometheus增加nginx-vts的target即可
http://127.0.0.1/status/format/prometheus
nginx-vts v0.1.17之前的版本没有支持promtheus格式的输出,如果是v0.1.17之前的版本,需要通过nginx-vts-exporter 将nginx-vts输出的信息转换为prometheus识别的格式。当然,建议最好还是使用最新的版本。
prometheus record rules:
groups:
- name: nginx
rules:
#虚拟主机rpm
- expr: sum by (host) (rate(nginx_vts_server_requests_total{code="total",host!="localhost"}[40s])*60)
record: 'nginx:total:rpm'
#虚拟主机状态码1xx的rpm
- expr: sum by (host) (rate(nginx_vts_server_requests_total{code="1xx",host!="localhost"}[40s])*60)
record: 'nginx:1xx:rpm'
#虚拟主机状态码2xx的rpm
- expr: sum by (host) (rate(nginx_vts_server_requests_total{code="2xx",host!="localhost"}[40s])*60)
record: 'nginx:2xx:rpm'
#虚拟主机状态码1xx的rpm
- expr: sum by (host) (rate(nginx_vts_server_requests_total{code="3xx",host!="localhost"}[40s])*60)
record: 'nginx:3xx:rpm'
#虚拟主机状态码5xx的rpm
- expr: sum by (host) (rate(nginx_vts_server_requests_total{code="5xx",host!="localhost"}[40s])*60)
record: 'nginx:5xx:rpm'
#虚拟主机异常访问的rpm
- expr: sum by (host) (rate(nginx_vts_server_requests_total{code=~"[4-5]xx",host!="localhost"}[40s])*60)
record: 'nginx:error:rpm'
#nginx实例的rpm
- expr: sum by (hostname) (rate(nginx_vts_server_requests_total{code="total"}[40s])*60)
record: 'nginxhost:total:rpm'
#nginx实例状态码2xx的rpm
- expr: sum by (hostname) (rate(nginx_vts_server_requests_total{code="2xx"}[40s])*60)
record: 'nginxhost:2xx:rpm'
#nginx实例异常访问的rpm
- expr: sum by (hostname) (rate(nginx_vts_server_requests_total{code=~"[4-5]xx"}[40s])*60)
record: 'nginxhost:error:rpm'
#虚拟主机的访问异常率
- expr: 'nginx:error:rpm/nginx:total:rpm'
record: 'http:error:rate'
#nginx实例的的访问异常率
- expr: 'nginxhost:error:rpm/nginxhost:total:rpm'
record: 'nginxhost:error:rate'图表展示

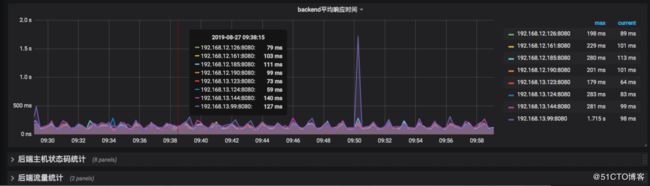
因为vts-module 暴露出的metrics里,server和upstream并没有关联关系,所以为了能在grafana中通过选择项目名称来同时展示server信息和upstream信息,就需要在命名上做一些规范。
我们项目的命名方式: 机房名称.运行环境.项目属组.项目名称
例如:
azure.prod.ops.download
一个vhost的配置大概如下:
upstream azure.prod.ops.download {
server 192.168.12.1 weight=2;
server 192.168.12.2 weight=1;
}
server {
listen 80;
server_name
azure.prod.ops.download
download.domain1.com
download.domain2.com
;
access_log /usr/local/nginx/logs/azure.prod.ops.download_access.json json;
error_log /usr/local/nginx/logs/azure.prod.ops.download_error.log;
client_max_body_size 200m;
location / {
proxy_pass http://azure.prod.ops.download;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_next_upstream error timeout http_404;
}
}这样通过同一个lebal就能选择出server和upstream的信息。
如果一个server有多个upstream,就在后面添加子名称,然后通过正则匹配前缀来获取所有的upstream.
这样prometheus也可根据idc名称,运行环境,项目组来编写通用的alert rules。
补充:
1、参数vhost_traffic_status_filter_by_host
vts-module 默认是将一个vhost的metrics汇总到第一个server_name 上显示出来,如果想按域名分开统计,可以开启此参数。注意:如果一个vhost拥有多个域名,开启此配置,在监控和展示层面上会比较麻烦。
2、如果没有url统计需求,谨慎开启uri过滤。如果需要开启,要做好相关限制,比如限制采集数量上限vhost_traffic_status_filter_max_node。尽量才用精确配置,比如将url过滤参数写在需要监控的localtion中,而不是整个server配置段里。还有做好反扫描配置。
3、如果在http段配置默认采集所有vhosts 信息,可在server配置段内,通过vhost_traffic_status_bypass_stats on跳过采集
4、nginx-vts-modules 与模块nginx_upstream_check_module冲突