1.副本(Replica)和分片(shard)
1.1 副本(replica) :可以接收读请求,不接收写请求
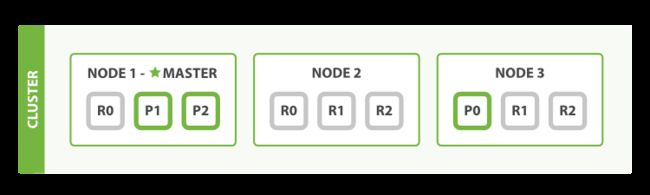
1)容错:副本的使用可以提高系统的容错性,类似于zk等其他分布式系统,当主分片出现故障,系统将切换到其副本分片,这就要求,主分片和其副本分片不能在同一节点上,副本数量也不是越多越好,比如以下有3个节点,设置了3个分片处理请求,如果将副本数量设置为3,那么主分片必然会和副本分片处于同一节点上,达不到容错的效果。
2)负载均衡:副本分片可以服务于读请求,意味着可以通过横向扩展副本节点对请求进行负载均衡。
1.2 分片(shard):处理读、写请求
当有请求发送到分片上时,任何分片都可以接收这个请求,并进行一次文档路由计算,决定哪一个分片能处理这个请求
shard = hash(routing) % number_of_primary_shards
routing是一个可变值,默认是文档的id,从这个规则就可以看出一个索引的分片数量从创建开始就不应该进行改变了,但是这并不意味着ES不能做到水平扩容。
1.3 分片预分配机制
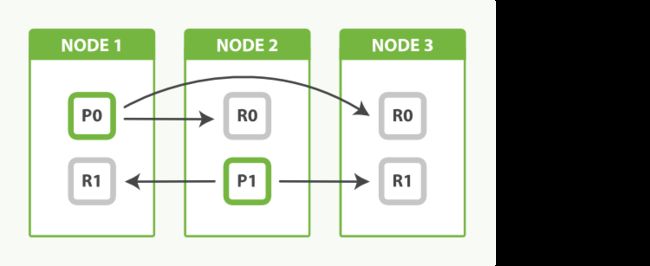
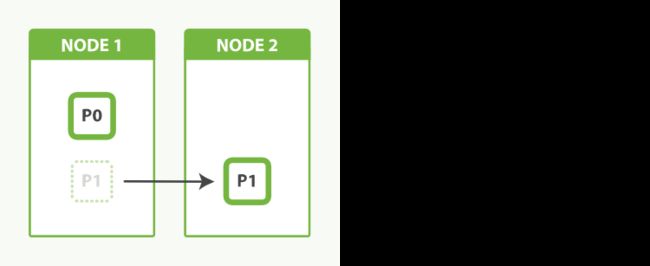
ES的分片预分配机制可以做到扩容,如下图,一开始就为索引分配了2个分片,当只有一个node时,两个分片都在node1上,当node2加入集群时,ES会将P1分片移动到node2上,并且在这个过程中分片仍然能处理请求,达到零停机的效果。
但并不是预分配分片数量越多越好,每一个分片都是有独立处理请求的进程(底层是一个luence索引),会消耗节点的物理资源,如果在一个节点上有N个分片都在处理请求时,就会对本地节点的资源进行竞争,并且计算相关度时会用到TF/IDF算法,分片数越多,每个分片上的词项就会越少,每一个分片计算出来的相关度会很低。
2. 节点间请求处理流程
2.1 新建、索引、删除文档流程
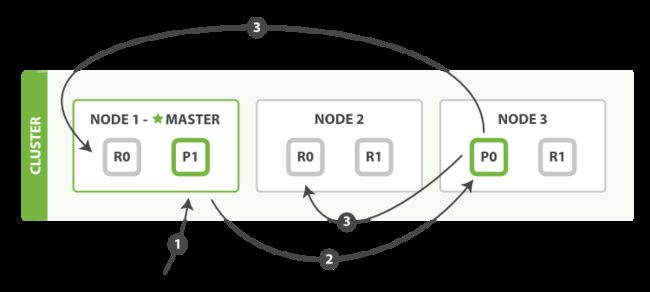
1)客户端发送请求到node1
2)node1根据文档id计算目标分片为P0,即将请求转发到node3
3)node3接收node1转发到请求,本地操作失败则返回失败;操作成功则将请求并行转发给副本分片R0,当副本分片全部返回成功,则P0返回成功(意味着客户端接收到操作成功响应时,主副分片都已经完成了请求的操作)
2.2 读取一个文档
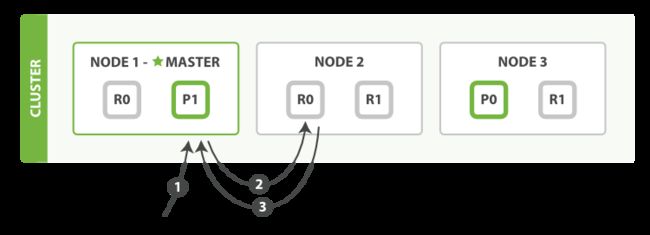
1)客户端向node1发送读请求
2)node1根据文档id计算文档属于P0,P0的副本位于node2,则将请求转发给node2(为了达到负载均衡,每次轮询不同副本分片转发请求)
3)node2将文档返回给node1,最后node1将文档返回给客户端(读取的文档可能在主分片上,但还未同步到副本分片,副本分片就会返回找不到此文档)
2.3 局部更新文档
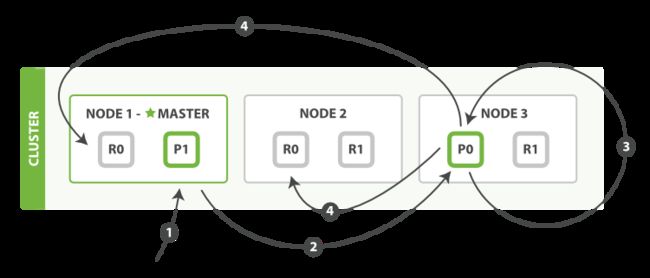
1)客户端向node1发送更新请求
2)node1根据文档id计算文档属于P0,则将请求转发给node3
3)node3从主分片P0检索文档,修改_source中字段的JSON,并尝试重新索引该文档,如果文档被另一个进程修改,则会重试直到达到阈值次数(乐观锁version)
4)将更新的完整文档转发给node1,node2副本分片,这里不保证顺序性
2.4 搜索类型
1)QUERY_AND_FETCH
客户端请求10个数据,协调节点转发请求并接受各节点返回值,对其汇总、排序,返回给客户端(客户端会收到10 * shard_num个数据)
缺点:数据量、排名有问题
2)QUERY_THEN_FETCH(默认)
客户端请求10个数据,协调节点转发请求并接受各节点返回值,对其汇总、排序,取前10个数据并去各个分区查询具体数据,最后返回给客户端
缺点:排名有问题
3)DFS_QUERY_AND_FETCH
查询之前,协调节点会从各个分片上搜集TF/IDF评分需要的数据,协调节点转发请求并接受各节点返回值,对其汇总、排序返回给客户端
缺点:数据量有问题
4)DFS_QUERY_THEN_FETCH
查询之前,协调节点会从各个分片上搜集TF/IDF评分需要的数据,协调节点转发请求并接受各节点返回值,对其汇总、排序取前10名,并到对应的分片查询数据详细内容,最后返回给客户端
缺点:性能最差
3. 文档处理过程(refresh和flush)
3.1 处理流程
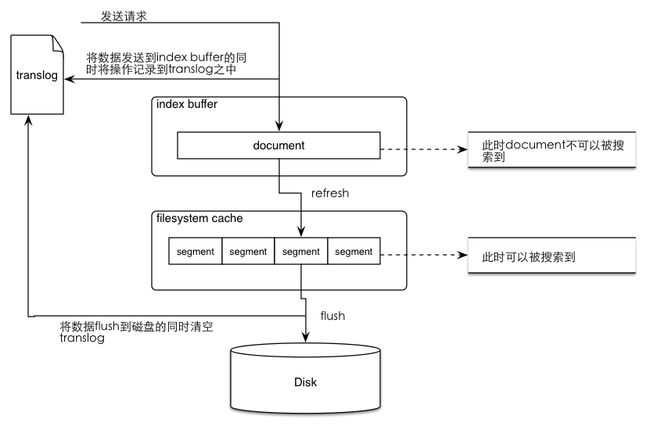
1)分片接收请求
2)将数据写入translog和index buffer中(此时文档不可被搜索)
Translog
-a.保证在filesystem cache中的数据不会因为ES重启或是发生意外故障的时候丢失
-b.当系统重启时会从translog中恢复之前记录的操作
-c.当对ES进行CRUD操作的时候,会先到translog之中进行查找,因为tranlog之中保存的是最新的数据
-d.在flush操作之后(将数据从filesystem cache刷入disk之中)才清除translog
index buffer 可能存在的OOM:
这个参数的默认值是10% heap size。根据经验,这个默认值也能够很好的工作,应对很大的索引吞吐量。 但有些用户认为这个 buffer 越大吞吐量越高,因此见过有用户将其设置为 40% 的。到了极端的情况,写入速度很高的时候,40%都被占用,导致OOM。
3)每隔一段时间进行一次refresh,将index buffer中的文档取出写入segment中
POST /index/_settings {“refresh_interval”: “10s”}
POST /index/_settings{“refresh_interval”: “-1″} //大规模创建索引时可以关闭refresh
4)将filesystem cahce中数据flush到磁盘,然后清除translog
PS:默认30分钟或者translog过大就会触发flush
3.2 segment
1)每一个磁盘segment都会维护一个del文件,删除操作不会直接删掉原文档,而是在del文件中标记原文档被删除;更新操作也不会在原文档上操作,而是先获取原文档,然后将修改后的文档写入内存,将原文档标记为删除。
2)ES提供合并segment机制,提高搜索效率,压缩所需空间
4. 分片内请求处理流程
4.1 数据结构
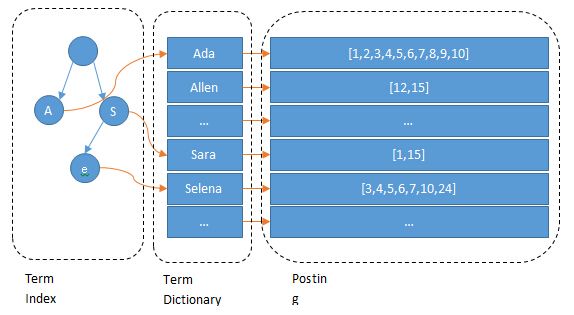
1)Term Index(前缀字典树)
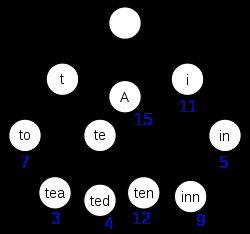
Term Index只保存了每个term的前缀,比如一本英文词典,A开头的词从第几页开始,AN开头的词从第几页开始,每一个节点都保存了该前缀在Term Dictionary的偏移量。
PS:该数据结构使用FST(Finite State Transducers)压缩技术,保存在内存中。
2)Term Dictionary(倒排索引中的term)
将所有的term进行字典排序,查找目标词时用二分查找,时间复杂度为logN
3)Posting List(term对应的文档id)
记录了每一个term对应的文档id。
PS:增量编码技术压缩/Roaring bitmaps压缩/bitset压缩,id为全局递增或者是有公共前缀等具有一定规律性的ID压缩效果最好
4.2 查询流程
目标词=>Term Index(查找大概的位置,得到要查询的起始offset和截止offset)=>Term Dictionary(根据offset进行二分查找)=>Posting List(获取目标文档id)
PS:联合索引按照上述过程查询,得到结果后,使用跳表或者bitset进行聚合
参考内容:
ES权威指南 https://elasticsearch.cn/book/elasticsearch_definitive_guide_2.x/index.html
ES索引原理 https://www.cnblogs.com/sha0830/p/8000242.html
ES最佳实践 https://www.jianshu.com/p/e59a3cce5840