邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
举个例子:下图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
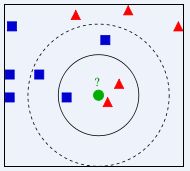
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比。
简单的kNN源码实现:
import java.util.LinkedList;
import java.util.List;
/**
* kNN算法思想:
* 找出与当前节点距离(这里用最简单的欧式距离)最近的k个节点,然后通过这k的节点的所属类型进行投票分类。少数服从多数。
* 约定原始数据为等长度的double类型数组,最后一位表示数据的class类别属性(默认二分类0,1)
* @author zhaoshiquan 2018年1月24日 下午2:25:12
*
*/
public class Algorithm_kNN {
public static double pos = 1.0;
public static double neg = 0.0;
public List kNN(List train, List sample, int k){
LinkedList list = new LinkedList();
sample.forEach(s->{
list.add(kNN(train, s, k));
});
return null;
}
public Res_Node kNN(List train, double[] sample, int k){
LinkedList list = new LinkedList();
train.forEach(t->{
insertNode(list, new KNN_Node(euclideanDistance(t, sample),t[t.length - 1]),k);
});
return getResult(list);
}
//欧式距离的计算
private double euclideanDistance(double[] train, double[] sample){
double sum = 0;
for(int i = 0; i list, KNN_Node node, int k){
//插入排序,并移除最后一个节点
int orig = list.size();
for(int i = 0; i< list.size(); i++){
if(list.get(i).dist >= node.dist){
list.add(i, node);
break;
}
}
//判断当前节点是否加入list中
if(orig == list.size())
list.addLast(node);
//判断list是否超过长度k
if(list.size() > k){
list.removeLast();
}
}
//获取分类结果
private Res_Node getResult(LinkedList list){
int count_pos = 0;
for(KNN_Node n:list){
if(n.label > 0.5)
count_pos++;
}
double conf = 1.0 * count_pos / list.size();
return conf>=0.5 ? new Res_Node(pos,conf) : new Res_Node(neg, 1 - conf);
}
class KNN_Node{
double dist = Double.MAX_VALUE;
double label;
public KNN_Node(double dist, double label){
this.dist = dist;
this.label = label;
}
}
class Res_Node{
public double label = neg;
/**
* confidence表示当前样本分类为label的置信度
*/
public double confidence = pos;
public Res_Node(double label, double confidence){
this.label = label;
this.confidence = confidence;
}
@Override
public String toString() {
return "Res_Node [label=" + label + ", confidence=" + confidence + "]";
}
}
}
测试数据及分类结果:
public static void main(String[] args) {
//测试数据
List train = new ArrayList<>();
double[] t1 = {1,1,1,1,1};
double[] t2 = {1,2,1,0,0};
double[] t3 = {1,3,1,3,1};
double[] t4 = {1,2,4,1,0};
double[] t5 = {1,0,5,1,0};
double[] t6 = {1,0,9,1,0};
double[] t7 = {1,1,2,1,1};
double[] t8 = {1,4,1,1,0};
double[] t9 = {1,5,0,1,1};
double[] t10 = {1,8,4.5,1,1};
train.add(t1);
train.add(t2);
train.add(t3);
train.add(t4);
train.add(t5);
train.add(t6);
train.add(t7);
train.add(t8);
double[] s1 = {0.0,0.0,0.0,1};
double[] s2 = {2,6,3,1};
double[] s3 = {1,1,2,0};
Algorithm_kNN knn = new Algorithm_kNN();
System.out.println(knn.kNN(train,s1,5));
System.out.println(knn.kNN(train,s2,7));
System.out.println(knn.kNN(train,s3,10));
}
分类结果:
Res_Node [label=1.0, confidence=0.6]
Res_Node [label=0.0, confidence=0.5714285714285714]
Res_Node [label=0.0, confidence=0.625]
kNN三要素
kNN模型由三要素——距离度量方式、k值选定和分类决策规则来确定。
距离度量
特征空间中两个点实例之间的距离是两个实例相似程度的反应。kNN一般使用的距离是欧式距离,但也可以是其他距离,如更一般的距离。
这里的。当时,称为曼哈顿距离,即:
当时,称为欧氏距离,即:
k值选择
k值得选择会之间对kNN模型的结果产生影响。k值较小时,只选择较小的领域内的训练实例进行预测,学习的近似误差会比较小,但是学习的估计误差会比价大,因为预测的结果会对邻近的点比较敏感,k值越小意味着整体模型的复杂度较高,容易发生过拟合。
如果选择的k值较大,相当于用较大领域的数据进行预测。优点是可以减少估计误差,但是近似误差会增大。k值越大意味着模型的复杂度越低,模型相对越简单。在实际应用中,k值一般是一个比较小的值,通常可以通过交叉验证大来选择最优的k值
分类决策规则
kNN的分类决策规则一般是少数服从多数,即多数表决规则。多数表决规则等价于经验风险最小化。
以上就是kNN的全部内容,在实际实施过程中,kNN需要考虑如何针对训练数据快速地进行kNN检索。最简单的方法是线性扫描,但是这种方法在数据量特别大的时候,计算非常耗时。一种较快的kNN检索的方式称为k-d Tree,可以使用k-d树对训练数据进行存储,并在k-d树的基础上进行kNN检索。