文章主要内容如下:
- 数据集介绍
- 数据预处理
- 特征提取
- 训练分类器
- 实验结果
- 总结
1. 数据集介绍
使用中文邮件数据集:trec06c。
数据集下载地址:https://plg.uwaterloo.ca/~gvcormac/treccorpus06/
下载的数据集压缩包里有“data” 文件夹,“full” 文件夹和 “delay” 文件夹。“data” 文件夹里面包含多个二级文件夹,二级文件夹里面才是垃圾邮件文本,一个文本代表一份邮件。“full” 文件夹里有一个 index 文件,该文件记录的是各邮件文本的标签。
data 文件夹
|
index 文件
|
|---|
2. 数据预处理
这一步将分别提取邮件样本和样本标签到一个单独文件中,顺便去掉邮件的非中文字符,将邮件分好词。
邮件大致内容如下图:
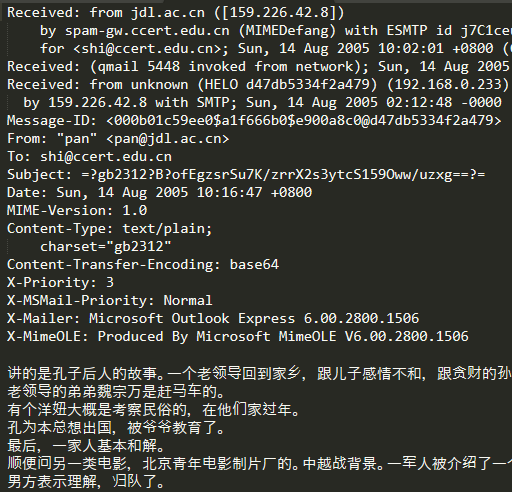
每一个邮件样本,除了邮件文本外,还包含其他信息,如发件人邮箱、收件人邮箱等。因为我是想把垃圾邮件分类简单地作为一个文本分类任务来解决,所以这里就忽略了这些信息。
用递归的方法读取所有目录里的邮件样本,用 jieba 分好词后写入到一个文本中,一行文本代表一个邮件样本:
import re
import jieba
import codecs
import os
# 去掉非中文字符
def clean_str(string):
string = re.sub(r"[^\u4e00-\u9fff]", " ", string)
string = re.sub(r"\s{2,}", " ", string)
return string.strip()
def get_data_in_a_file(original_path, save_path='all_email.txt'):
files = os.listdir(original_path)
for file in files:
if os.path.isdir(original_path + '/' + file):
get_data_in_a_file(original_path + '/' + file, save_path=save_path)
else:
email = ''
# 注意要用 'ignore',不然会报错
f = codecs.open(original_path + '/' + file, 'r', 'gbk', errors='ignore')
# lines = f.readlines()
for line in f:
line = clean_str(line)
email += line
f.close()
"""
发现在递归过程中使用 'a' 模式一个个写入文件比 在递归完后一次性用 'w' 模式写入文件快很多
"""
f = open(save_path, 'a', encoding='utf8')
email = [word for word in jieba.cut(email) if word.strip() != '']
f.write(' '.join(email) + '\n')
print('Storing emails in a file ...')
get_data_in_a_file('data', save_path='all_email.txt')
print('Store emails finished !')
然后将样本标签写入单独的文件中,0 代表垃圾邮件,1 代表非垃圾邮件。代码如下:
def get_label_in_a_file(original_path, save_path='all_email.txt'):
f = open(original_path, 'r')
label_list = []
for line in f:
# spam
if line[0] == 's':
label_list.append('0')
# ham
elif line[0] == 'h':
label_list.append('1')
f = open(save_path, 'w', encoding='utf8')
f.write('\n'.join(label_list))
f.close()
print('Storing labels in a file ...')
get_label_in_a_file('index', save_path='label.txt')
print('Store labels finished !')
3. 特征提取
将文本型数据转化为数值型数据,本文使用的是 TF-IDF 方法。
TF-IDF 是词频-逆向文档频率(Term-Frequency,Inverse Document Frequency)。公式如下:
在所有文档中,一个词的 IDF 是一样的,TF 是不一样的。在一个文档中,一个词的 TF 和 IDF 越高,说明该词在该文档中出现得多,在其他文档中出现得少。因此,该词对这个文档的重要性较高,可以用来区分这个文档。
假设文档中出现的所有词的集合为词典 ,集合大小为 ,则该文档的特征表示是一个 维向量,向量的每一个元素为对应词在该文档的 TF-IDF 值。用 TF-IDF 提取文本特征的代码如下:
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
def tokenizer_jieba(line):
# 结巴分词
return [li for li in jieba.cut(line) if li.strip() != '']
def tokenizer_space(line):
# 按空格分词
return [li for li in line.split() if li.strip() != '']
def get_data_tf_idf(email_file_name):
# 邮件样本已经分好了词,词之间用空格隔开,所以 tokenizer=tokenizer_space
vectoring = TfidfVectorizer(input='content', tokenizer=tokenizer_space, analyzer='word')
content = open(email_file_name, 'r', encoding='utf8').readlines()
x = vectoring.fit_transform(content)
return x, vectoring
这里返回的 是一个 维的样本矩阵,vectoring 可用来将文本转化为 TF-IDF 表示。
4. 训练分类器
python sklearn 中有许多分类器,直接调包就行了。代码如下:
from sklearn.linear_model import LogisticRegression
from sklearn import svm, ensemble, naive_bayes
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as np
if __name__ == "__main__":
np.random.seed(1)
email_file_name = 'all_email.txt'
label_file_name = 'label.txt'
x, vectoring = get_data_tf_idf(email_file_name)
y = get_label_list(label_file_name)
# print('x.shape : ', x.shape)
# print('y.shape : ', y.shape)
# 随机打乱所有样本
index = np.arange(len(y))
np.random.shuffle(index)
x = x[index]
y = y[index]
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
clf = svm.LinearSVC()
# clf = LogisticRegression()
# clf = ensemble.RandomForestClassifier()
clf.fit(x_train, y_train)
y_pred = clf.predict(x_test)
print('classification_report\n', metrics.classification_report(y_test, y_pred, digits=4))
print('Accuracy:', metrics.accuracy_score(y_test, y_pred))
5. 实验结果
| Algorithm | Accuracy | Precision | Recall | f1 score |
|---|---|---|---|---|
| SVM | 99.30% | 99.30% | 99.30% | 99.29% |
| Random Forest | 98.94% | 98.94% | 98.94% | 98.94% |
| Logistics Regression | 98.74% | 98.74% | 98.74% | 98.74% |
可以看到,几个算法的分类结果都很不错。不过也说明了 trec06c 数据集挑战性不高,哈哈。
总结
这一次实验大多数代码都是调包的。当然,我们也不能只会调包,应该要了解背后的算法的原理。甚至有时间的话,得看看 sklearn 一些包的源码,应该挺值得借鉴学习的。